Hello,
As you can see in the excel data below, I have a Unit ID and a Device ID. I need to assign a unique Unit ID to the Device and eliminate all rows that duplicate either value. I added the “Good?” column to show how these IDs should be assigned and the rows that need to be eliminated. Any help would be appreciated.
Hi @rangerry , welcome to the KNIME community
Could you upload your sample input data so that people can try out ideas. On the face of it this looked like a simple de-duplication problem, where rows would be simply eliminated because of duplicates found in each column in turn, but there is a subtlety here which makes it more complex than that.
Just taking the first 4 rows as an example:
| 1 | Unit ID | Device ID |
|---|---|---|
| 2 | 267.001.2 | S1005215 |
| 3 | 267.001.2 | S1005216 |
| 4 | 267.002.2 | S1005215 |
| 5 | 267.002.2 | S1005216 |
if we eliminate duplicates in Unit ID (keeping first) that would result in
| 1 | Unit ID | Device ID |
|---|---|---|
| 2 | 267.001.2 | S1005215 |
| 4 | 267.002.2 | S1005215 |
and then if we eliminate duplication in Device ID that leaves just one row:
| 1 | Unit ID | Device ID |
|---|---|---|
| 2 | 267.001.2 | S1005215 |
which of course is the wrong answer, as we want to choose to eliminate the duplicate which leaves us with the greatest number of non-duplicate rows
i.e.
| 1 | Unit ID | Device ID |
|---|---|---|
| 2 | 267.001.2 | S1005215 |
| 5 | 267.002.2 | S1005216 |
I wonder then what happens if we have a variety of combinations involving several different Device IDs and Unit IDs, e.g. a 3 or 4-way swap… Suddenly this feels like it could become a non-trivial problem involving finding all the combinations and recursively inspecting what could be removed to leave the greatest number of non-duplicated rows.
I may be overcomplicating it, but an algorithm has to be able to cope with the worst case data set, so if there are any limits on the number of different Device IDs that a given Unit ID can appear against or anything else like that it would be good to know.
1 Like
So … I had a chat with a friend… it went like this:
If have a table of data consisting of UnitID and DeviceID
e.g.
Unit ID Device ID
267.001.2 S1005215
267.001.2 S1005216
267.002.2 S1005215
267.002.2 S1005216what algorithm could I use to return the largest number of rows that does not contain a repeated Unit ID or Device ID
and my friend (ok, it was chatGPT) replied:
“To find the largest number of rows that do not contain a repeated Unit ID or Device ID, you can use a graph-based approach. You can represent the relationships between Unit IDs and Device IDs as a graph and then find the largest set of rows that do not share common nodes (Unit ID or Device ID).”
It then presented me with some python, which I decided not to use because I wanted to find some non-python way, at least for now…
but what it did also say was this:
This code creates a directed graph where each row in your data is represented as an edge between Unit ID and Device ID. It then finds the largest acyclic subgraph using the connected components of the undirected graph. Finally, it extracts the rows corresponding to the largest acyclic subgraph, which represents the largest number of rows that do not contain a repeated Unit ID or Device ID.
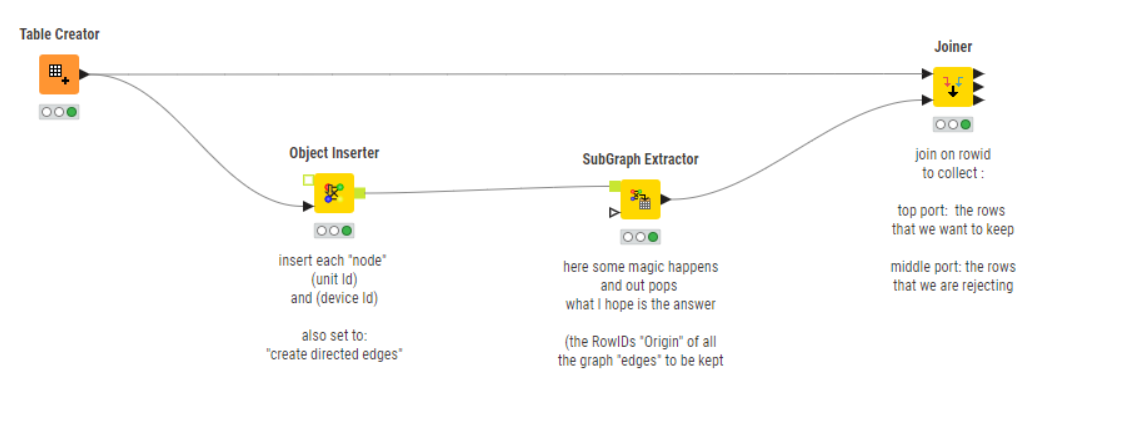
That seemed interesting, so I went searching for KNIME “acyclic subgraph”, which led me back to the “network” / “subgraph” nodes used here:
and here
and that ultimately led me build a workflow that it would be good to try out with your data, because I have no idea if (or how!!) it works ![]() I suspect @tobias.koetter might be able to tell us!
I suspect @tobias.koetter might be able to tell us! ![]()
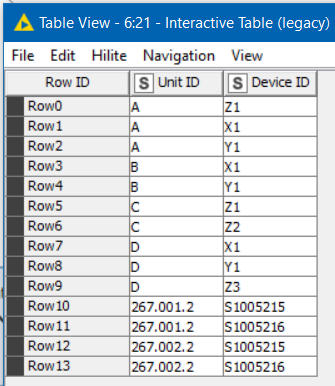
What I can tell you is that given this input:
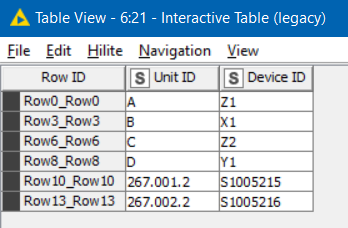
it returns the following output (rows to keep)
and given this input:
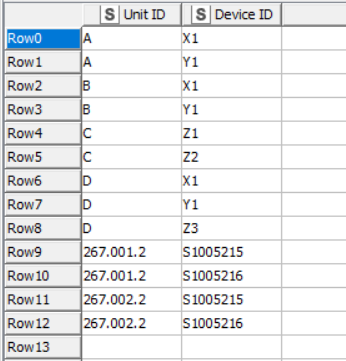
it produces this output:
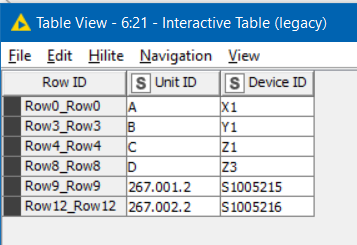
That appears right to me!
remove duplication in two columns.knwf (82.7 KB)
Will be good to know what happens with the “real” data.
btw Anybody interested in the python code that chatGPT generated for this can find the chat here
1 Like
Yes, here is the dataset.
Sample ID Data.xlsx (31.7 KB)
I also have a sample workflow that does not work, but I believe is close to a solution using recursive loop start to increment the last row and do a comparison. I will upload that as well.
Unit ID number is broken down to (LocationID.UniqueDeviceID.NumberOfDevicesAtLocation).
Sample Unique ID.knwf (26.3 KB)
1 Like
This looks to be correctly eliminating the duplicate rows…other than where I have errors in my sample data ![]() .
.
I will rerun with real data and see.
Thanks for the help!! I will mark solution if all goes well.
1 Like
Hi @rangerry, thanks for uploading the sample data, and glad to hear it looks promising.
I’ve added it into this workflow, renaming the columns so that it would work with the rest of the flow, then at the end concatenating back the rows to keep and remove (with the Good marker), which is obviously an “optional extra” but may assist with any testing.
In some cases, I think it may be an arbitrary decision over which rows are ultimately kept as there could be multiple possibilities.
remove duplication in two columns - with sample data.knwf (101.9 KB)
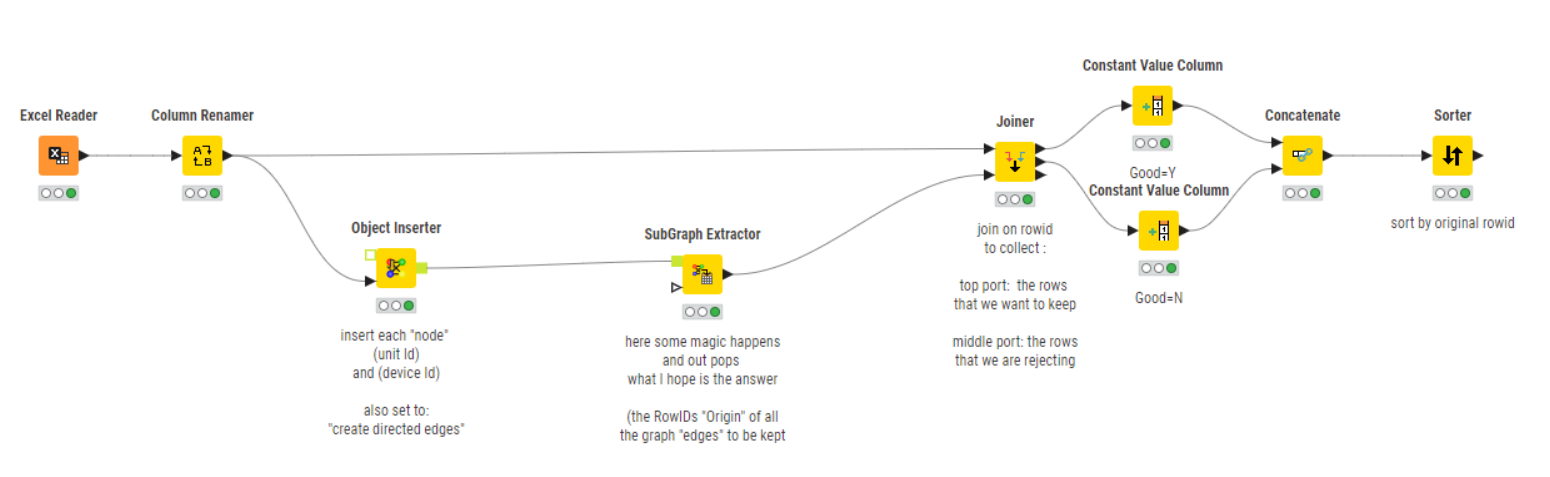
That was certainly a challenge that took me completely by surprise about the direction it headed ![]()
2 Likes
Yeah, tell me about it!! I’ve been scratching my head for days on this one! ![]()
2 Likes
I think the recursive loop direction you were headed made sense, but it would certainly be a “fun” one to write, and I suspect ultimately a bit slow on lots of data. If the above nodes hadn’t been available (and hopefully they do the job), then I think python would have been the likely next stop!
Thanks for marking the solution, and good luck! ![]()
Python was def my next stop. I’m glad this one got the creative juices flowing! Lol. It was harder than it looked on the outside. Thanks again for the help!
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.