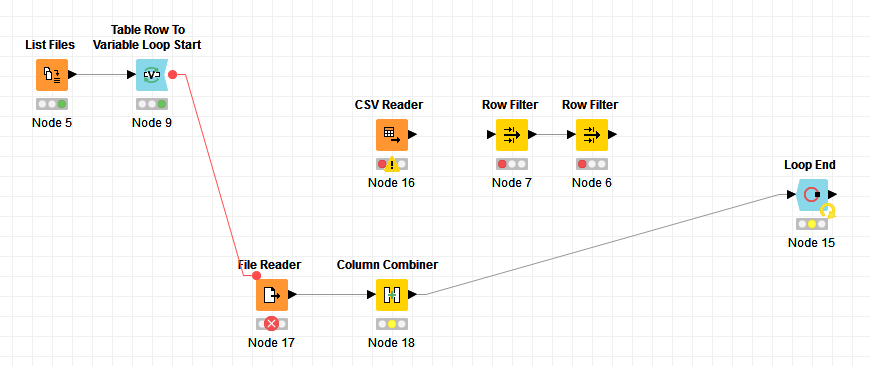
ERROR File Reader 2:17 Execute failed: Too few data elements (line: 1 (Row0), source: ‘file:/P:/Exportations_LabPlus/resultatspreliminaires%20(10).csv’)
I’m very new with Knime and I don’t know how to begin to solve my problem…
Could you provide us with data representing your problem. If you cannot share the date because of privacy and confidentiality you might want to create files that have the same logical structure as your problem. From the screenshot I have a few questions
do you have ‘stable’ headers? would they always be on the same row or might that be different? (If different is there an indicator identifying the Header)
do you want to use IDs and merge the various lines so that you have all the different columns or would you just store them beneath each other while there might be more and more columns
do you have columns with different names that still would carry the same information and do you want to combine them?
From the screenshot my impression is that you would need several steps. You might have to extract the column information first and then the data itself from line 5 on. You can later bring back the column names with the:
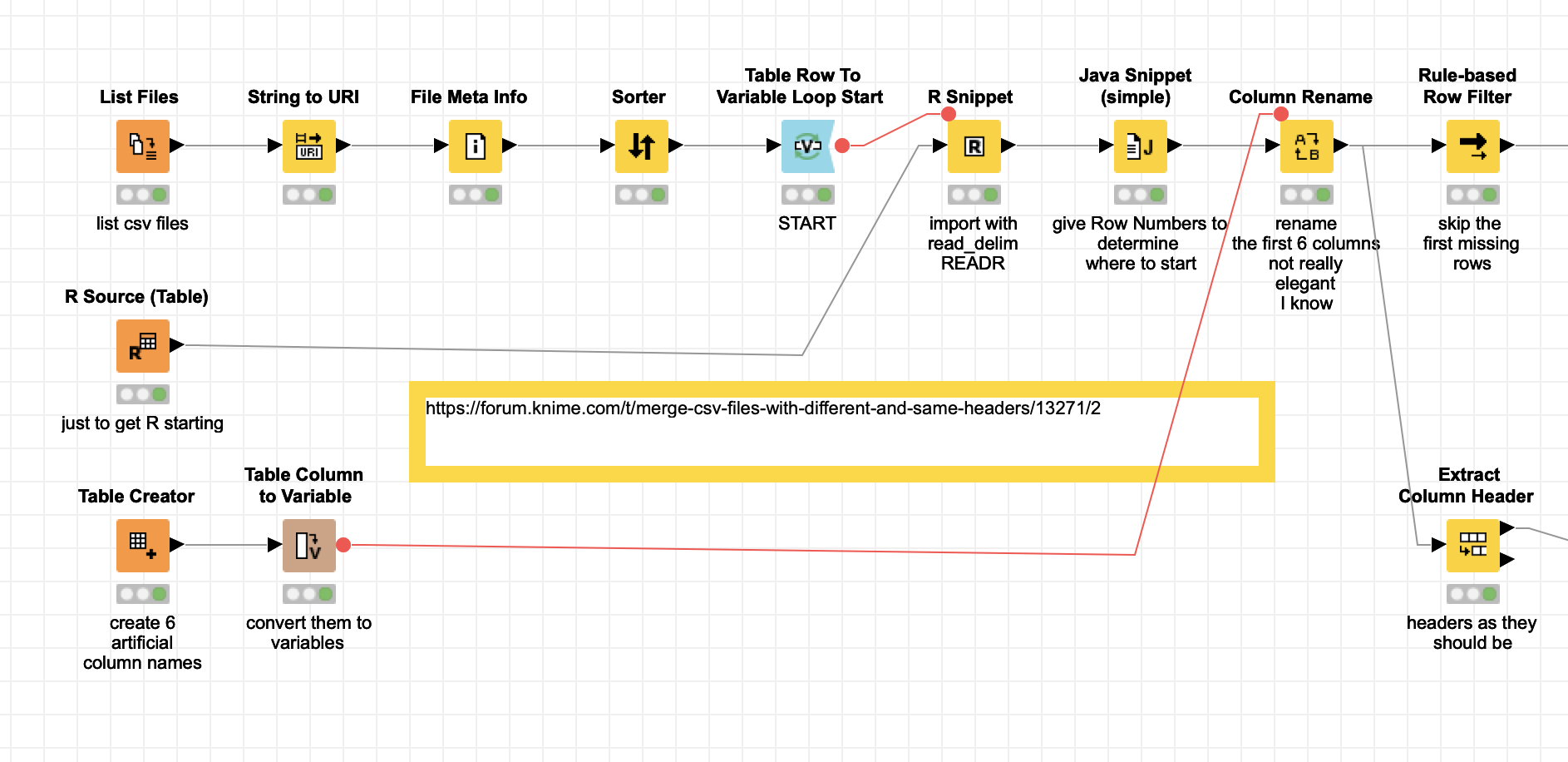
Well well. I set up a workflow that hopefully does what you want. The CSV data really seems to be quite messy with funny column headers and stuff. For the “resultatspreliminaires (15).csv” I had to revert to my trusted readr package from R. I really would recommend investing in some useful data storage concepts - CSV is widespread but also unstable and messy. Why not use Parquet, or SQLite, or ARFF - all supported by KNIME - but that is just me
The workflow assumes the first 6 columns are always the same and gives them the names Column1 - 6 (you can later rename them to something useful).
Then I use readr to just import the data and determine the column headers and where the real data starts when the first line of Column1 does not have any missing (you might have to tweak that, give a fix number or delete some rows with missing data).
Then I load the data starting from the recently identified 1st row. Then the column names get assigned back.
hmm might be again a little bit over-engineered but I hope it works. Feel free to adapt it.
For the moment, I can’t try it because I’ve some issues with R and Knime connection…
But I will come back here when I had tried it.
I’m working with our IT support to modify the output data form, because I know that it’s horrible…
But you know… IT are not usually very fast… especially in large companies…
Glad it works. R and KNIME is sometimes a little bit complicated because you need to have RServe working and the latest version of that needs to be compiled. I can provide you with some links about that.