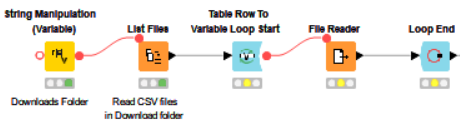
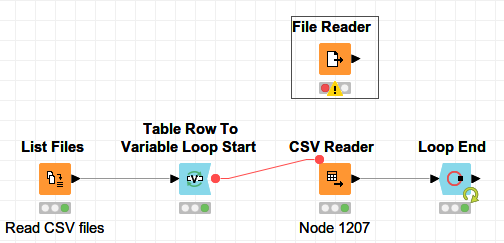
I’m trying to merge a dozen different CSV files from one folder into a single file. I’m using a method I’ve used before, as shown below:
However, when I try to run this, I get an error. The error I get depends on whether I’ve checked the “ignore spaces and tabs” box in the basic settings of the File Reader node. When I have it checked, I get this error:
Execute failed: Too many data elements
When I have that box unchecked, I get this error:
Execute failed: For input string: “233times” In line 2 (Row0) at column #27 (‘Follow Link Ratio’).
I have tried importing each of these files separately in the File Reader node without using the variable, and it seems that some files preview better with that box checked, and some do not.
The files all come from the same system, and the first 20 columns are identical, but the files do not all have the same number of columns. Some may have 25, some may have 30. I’m only interested in the data that’s in a couple of the first 20 columns.
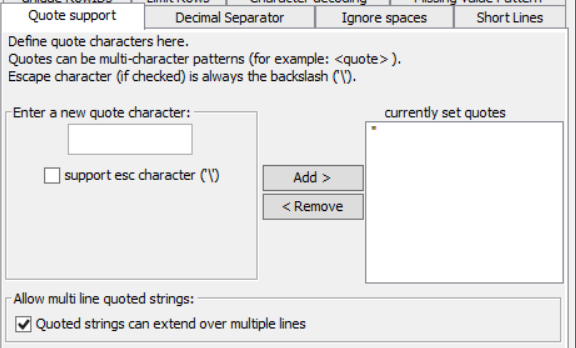
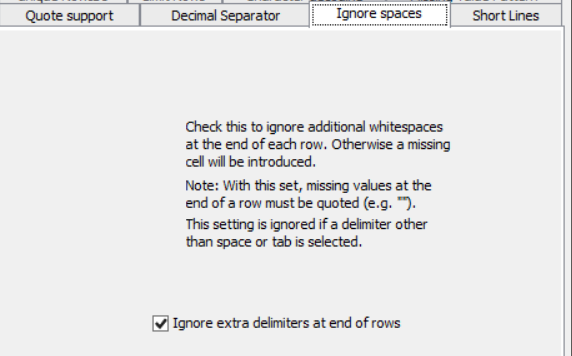
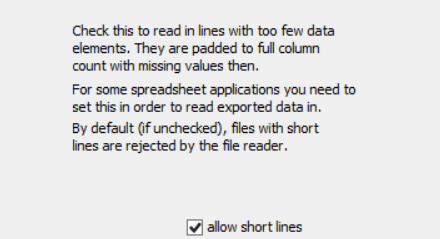
In case it might be helpful, here are all of the other settings that I have configured on the File Reader Node.
Maybe there’s a setting I could adjust using a flow variable so that all of the fields are brought in as string values or something? Or a way for me to only import the first 10 columns?
Thanks for the idea. I tried that, with no luck. I think it’s having an issue putting string values in the same column location as integer/double columns. Here are a couple files with some made up data. I need the data in the first 21 columns, but nothing after that. Sample Files.zip (7.1 KB)
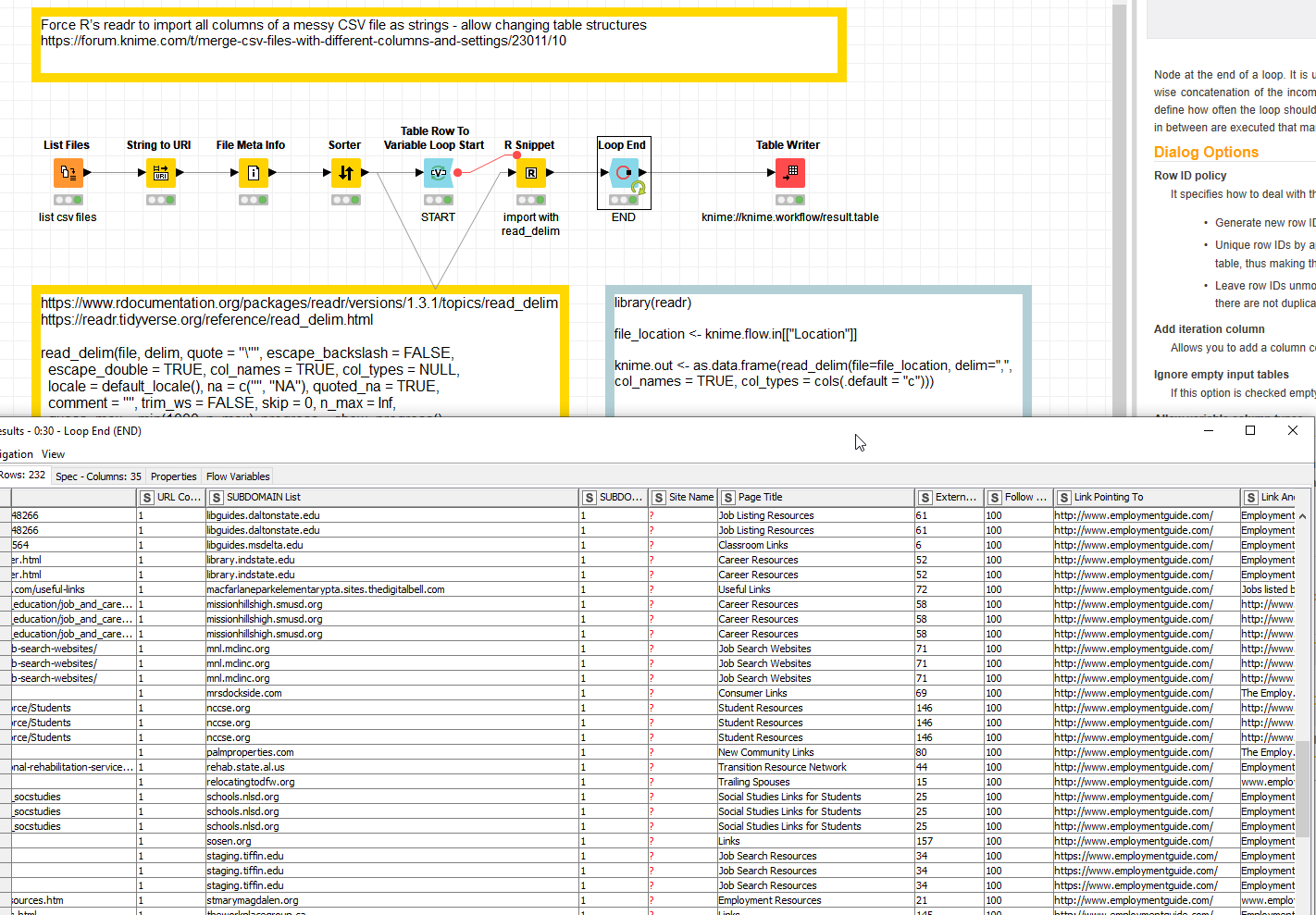
From my experience the use of the R package Readr can help with ‘messy’ csv files. You could force all columns to be imported as string for example and deal with formats later.
like mlauber71 already wrote - as far as I can see the example files works fine when using the csv reader.
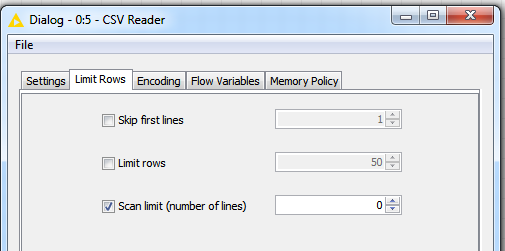
In case you want to enforce that you do not get the different types for the same column names you can change the “Scan limit” in the config to 0 (then all columns are read in as String)
Then you could cast the columns to your desired format afterwards
Thanks for the suggestion @mlauber71. I’ve tried to use this R package reader, but I’ve never used it before and I’m not sure exactly what I’m doing. I get the following errors when I try to use it.
ERROR R Snippet 3:20 Execute failed: Error in R code:
Error: there is no package called 'readr'
Error: could not find function "read_delim"
Any ideas on what I’m doing wrong?
Also, it looks like this is designed to read the last modified file in a folder. I presume it would be able to be put into a loop so I could read all files in a folder as well, right?
Thanks @HansS, apparently I didn’t put enough of the issues in my sample files. My actual dataset also has line breaks in quoted strings in the CSV files, which gives me the following error when using the CSV reader.
Execute failed: New line in quoted string (or closing quote missing).
So, I’m dealing with different columns after the first 20 or so, as well as line breaks in quoted strings. I haven’t been able to find a solution that fixes both of those issues yet. I’m attaching 2 new sample CSVs that also have line breaks in quoted strings. Sample Files 2.zip (7.2 KB)
@mlauber71 - Thanks for the clarification. I’m going to install R and see if I can get this all to work. I’ve been curious about dabbling in R in the past, and this is a nice excuse to start.
However, I currently build workflows for a remote team that executes them on their computers, and I’d love to find a solution that doesn’t require me to install R on all their different machines. If anyone else has any other ideas on this, I’m all ears.
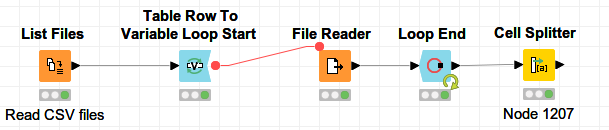
I took another look and made “a small adjustment” to my flow above. I used the File Reader node. But I selected for a delimiter: none . After reading the sample files, I used a Cell Splitter node (split by , ) , and for me it looks quite ok… Sample_Different CSV files.knwf (56.8 KB)
gr. Hans