I used this example
to turn it into a workflow to predict multiple classes. And I also added the accuracy statistics. One with F1 in Python but also the KNIME Scorer which also has a “micro” F1 as “Accuracy” - so the Python is more there to test the logic.
I am though a little bit reluctant to just use such multiple classifications as targets. Maybe someone could weight in who has more experience in that field. And of course you should be careful and test your results with real life data (and new data for that matter).
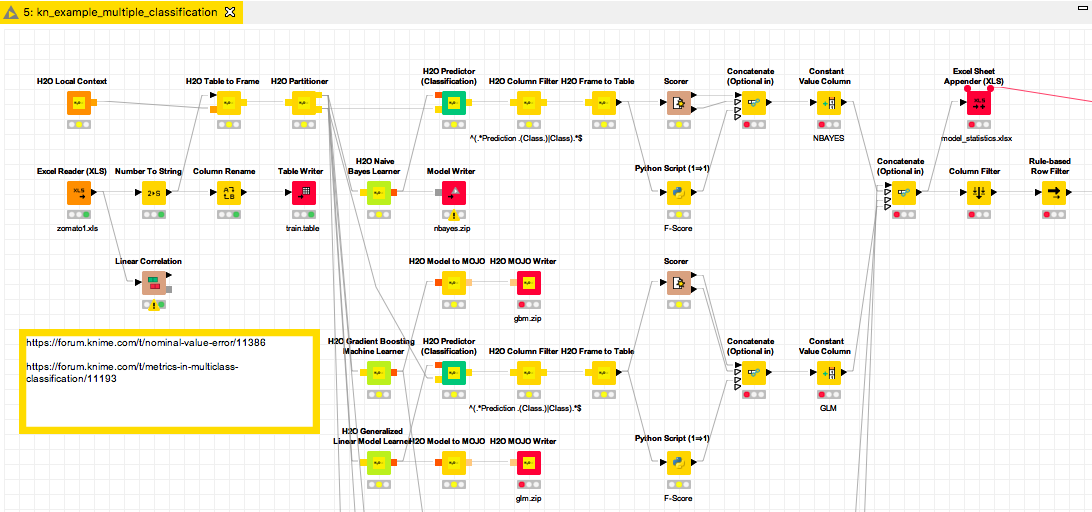
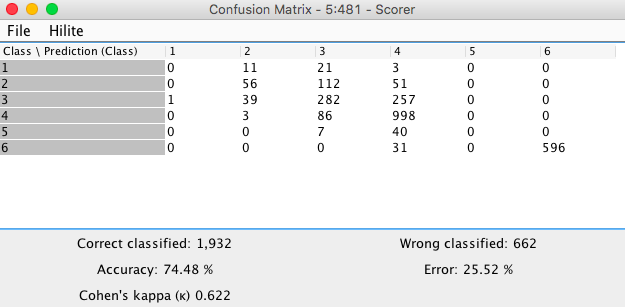
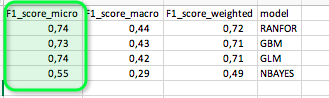
kn_example_multiple_classification.knwf (460.2 KB)
–
Edit - There is a new workflow for Multi-Class Problems Multiclass Machine Learning - Wine Quality – KNIME Community Hub