We had a similar discussion about metrics in multi class predictions here:
Besides accuracy you could use a LogLoss metric. That means that not only the outcome of prediction will be taken into account but also the ‘level of certainty’.
If you have two predictions from two models
A) 1=51%, 2=39%, 3=10% TRUTH=>1
B) 1=90%, 2=5%, 3=4% TRUTH=>1
both come up with the correct result (1). But prediction B) would be better as it predicts the correct answer with higher confidence and might be more robust. So you would prefer the model behind B). The LogLoss takes that into account.
I reworked the workflow from our late discussion and put in a comparison of 4 modelling approaches with the great H2O.ai nodes. In this case the Random Forest comes out on top but barely. Please be aware: there are dozens of settings to be played around with and with different settings GLM might carry the day. The models are just there to give an illustration. You could easily adopt more models.
The LogLoss is done in Python, since I did not found one within KNIME.
You can read about the KNIME scorer metric here:
And about LogLoss here:
http://wiki.fast.ai/index.php/Log_Loss
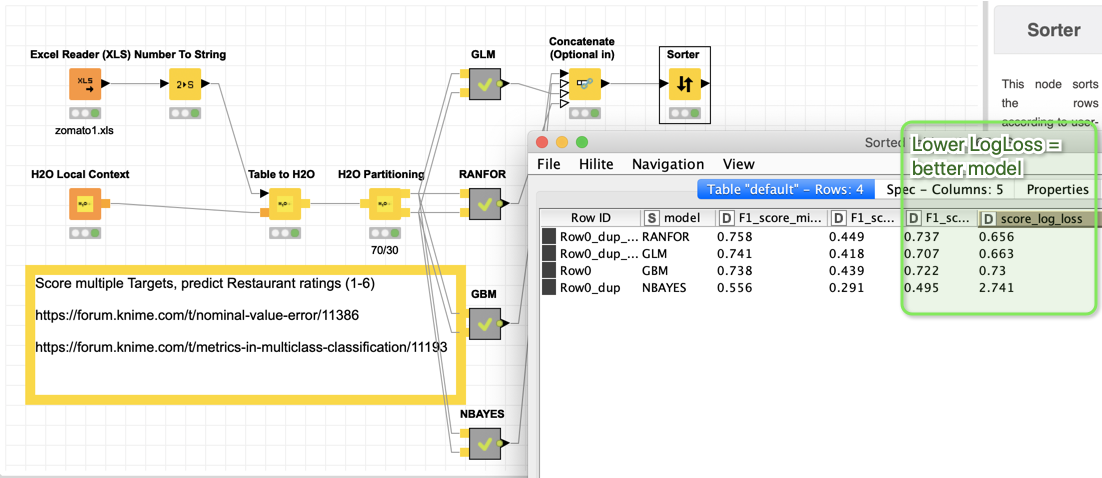
The workflow expects a string variable “Class” that should have values 1-6 (or more) but might have other values as well (I have not tested that). If you have a different set of classes it should adapt to that.
kn_example_multiclass.knar (403.3 KB)
You would also get an overview of what all models do in an exported Excel. With a matrix about true and false predictions.

As has been discussed earlier. Be careful with relying on 99.x% accuracy claims. The usefulness of a model very much depends on your business question, what the default outcome is and what cost/consequences a misclassification has. Eg. if 95% of your population are Class=1 and you would predict everyone to be Class=1 your Accuracy still might be nominally high but the model would still be useless.
–
Edit - There is a new workflow for Multi-Class Problems Multiclass Machine Learning - Wine Quality – KNIME Community Hub