you will have to do the whole preprocessing you did for your training also for your new data, otherwise the model will not have the same structure and cannot be applied
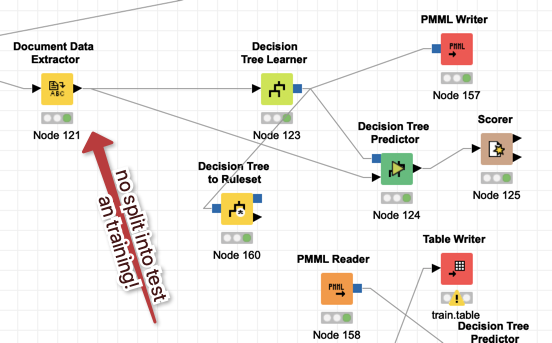
then you are not splitting your data into test and training for the development of your model. So the very high score is not very useful since both deal with the same set of data
and you will have to make sure that the answer is not somewhere encoded in the data (which will not be present in any future data you might want to score)
I will have a look and see if I can find a fix.
If you want to read about Yes/No models you can follow these links and will also find some example workflows you could use (the data preparation would still have to be yours)
Understand metrics like AUC and Gini (and use H2O.ai)