Hi ,
I have a 4 different file data file for 4 months (Jan ,Feb, March n April ) when we are getting the April month data … i need to call the Jan , Feb & March data and append those records to the final file .
Can you please guide which nodes can be used to acheive this .
Hello @prashanthpatil
Can you be more accurate on whether you are finding difficulties?, as I can spot two different tasks in your challenge description:
Read files and append (bind) data.
Create the MTD / YTD workflow. As the topic title suggested.
For the second task you can tale a look into the JKI Ch10 ‘Calculating YTD and MTD’ for insights.
Thanks@haddock for your response . To be more specific … The problem statement is as mentioned below :
In the backend table , we will have only one month data for example its Feb 2024 data .
We have the previous month data (Dec 2023, Jan 2024) captured in another backend table or csv file .
In this case using which nodes can we invoke the previous months data and we need this iteration to continue when march data present in backend , in that case i need the dec 2023,jan 2024 & feb 2024 data to be fetched from another backend table or csv file .
Hello @prashanthpatil
I have to assume that all your data is feed from excel files; is it?
There is not a single option, as it depends on how your data is stored and structured…
In the simplest case, all your files are standardized (columns, data type, sheet name) and stored in the same folder. Then the Excel Reader node can read and append the data at once; with the option ‘Files in folder’. More complex scenarios can be customized by reading the file paths in loop…
Besides that, you didn’t mentioned the type of data you are importing. I am assuming Sales as in the JKI example provided.
Ideally you can provide some example about: how your data looks like, your expected output, and what you have try so far.
I hope I am not giving you an out of context solution. If I am let me know. As per your initial requirement:
If there are multiple files (XLSX/XLS/CSV) then is this case you will use multiple files readers, for example (Excel /CSV reader).
If all are coming from the table, you will be using DB connection to connect with DB. If there are multiple DB sources, then you have to use a multiple DB connection node.
Secondly, Business logic you know better. Once all these data are in your canvas proceed with your flow as per your business requirement.
Thanks for your response .
Your are correct we are using the above mentioned nodes (XLSX/XLS/CSV or DB connection) .
But query here is if i am getting the data from backend is having the feb 2024 , in that case i need to fetch the Dec 2023 & Jan 2024 data and similar if we are getting the march 2024 data then i need to fetch the Dec 2023 , Jan 2024 & Feb 2024 .
How do i fetch the pervious period data dynamically .
If I were you, I would make the flow dynamic (you can hard code all these as well). You can make the mapping (or can call configuration/refrence)file for each case in Excel, and store it, read it, and use IF node or Snippet node to read the mapping and execute the further logic on the basis of scenarios in the mapping file (this answer is just an overview). Hope this helps.
Example: To fetch the required data based on the backend date provided, you can use KNIME to manipulate the data accordingly. Here’s a general approach you can take:
Date Comparison: Compare the backend date with the target month (e.g., Feb 2024 or March 2024) to determine the data retrieval range.
Data Filtering: Use KNIME nodes like “Row Filter” or “Date&Time-based Row Filter” to filter the data based on the specified range. For example, if the backend date is Feb 2024, filter data for Dec 2023 and Jan 2024.
Data Aggregation: After filtering, you can aggregate or combine the data from the selected months to create the desired dataset for analysis
My data has the following details : Employee_Id, Year, Period, Sales data for month of April 2023
Expected result : When the Period is April or 04 , i need to fetch the Jan , Feb & March Details from CSV file . Similar if Period is March or 03 , i need to fetch the Jan & Feb data file .
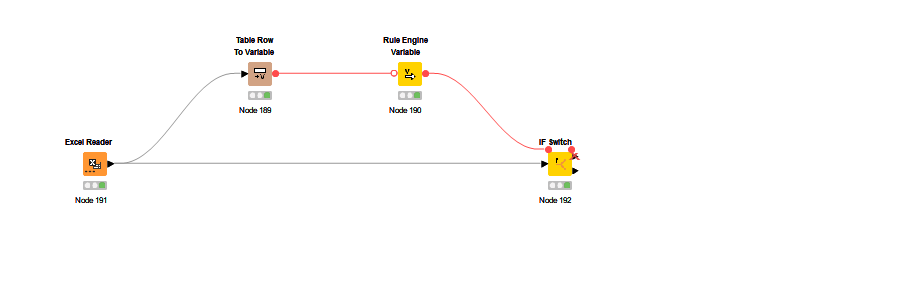
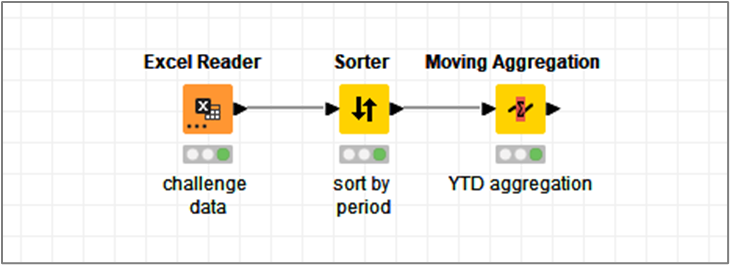
In my JKI S2 Ch10 attempt, you can find a tested full deployment for a MTD / YTD multiyear data set (no loops). You can check it for custom use case upgrades.
Have you tried the already proposed solution regarding excel reader from folder or in case you have multiple sheets a loop for reading all files in a folder?
br