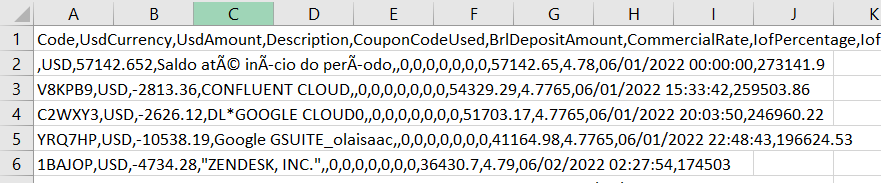
I’m trying to read a file but it doesn’t breaks the columns the right way for all the comma matches. For this example, the line that starts with “1BAJOP” is the one that it’s not working. I have more lines in the file with the same problem as this one.
Could you please upload your text file here (at least with the text portion you are displaying) if it is not confidential so that we can try to help from there ?
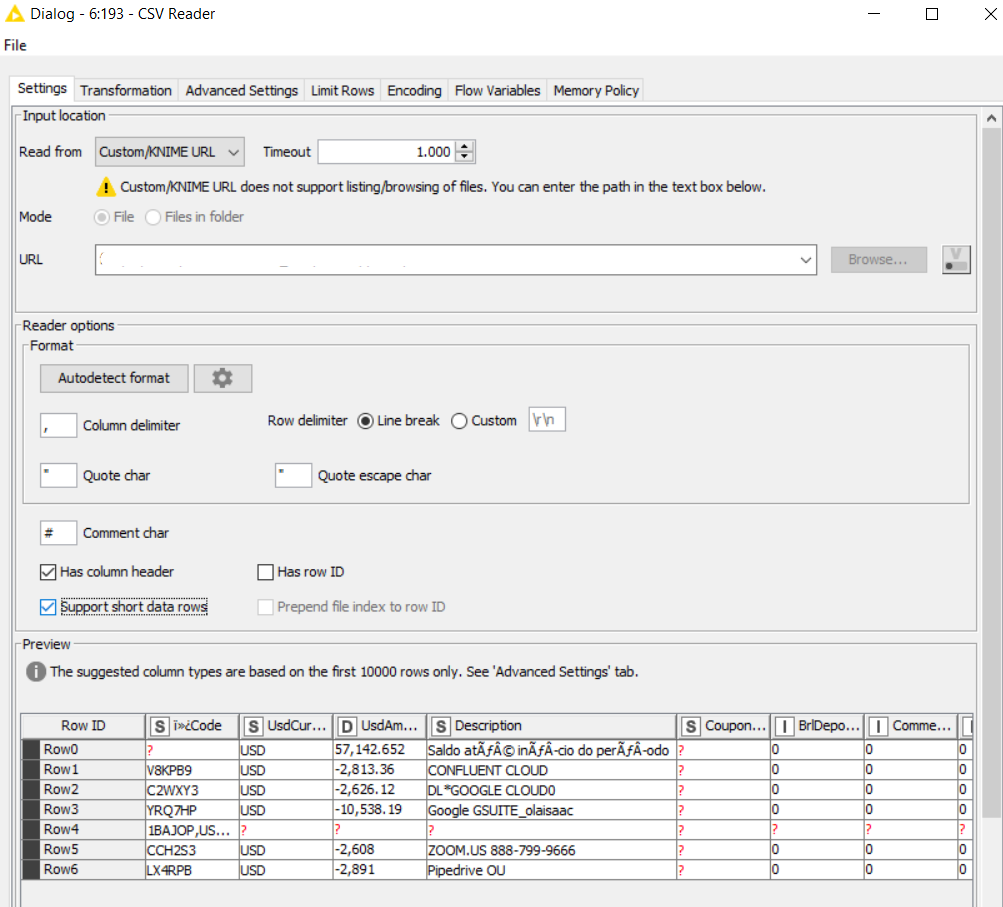
@Le18BR you might have to try and toy with the advanced settings especially the ones dealing with quotations since this seems to be the line where there is a problem.
Knime forum doesn’t allow uploading .csv files, I’ve renamed the extension of the file to .txt, just rename it back to .csv and you should have the same file. abc.txt (898 Bytes)
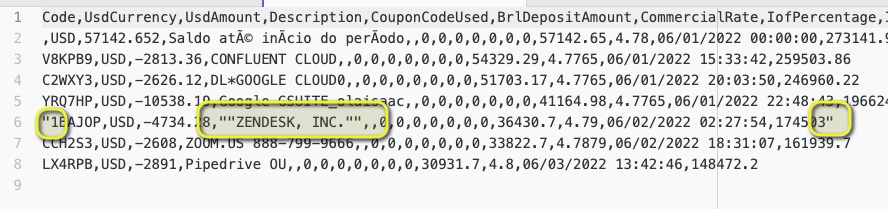
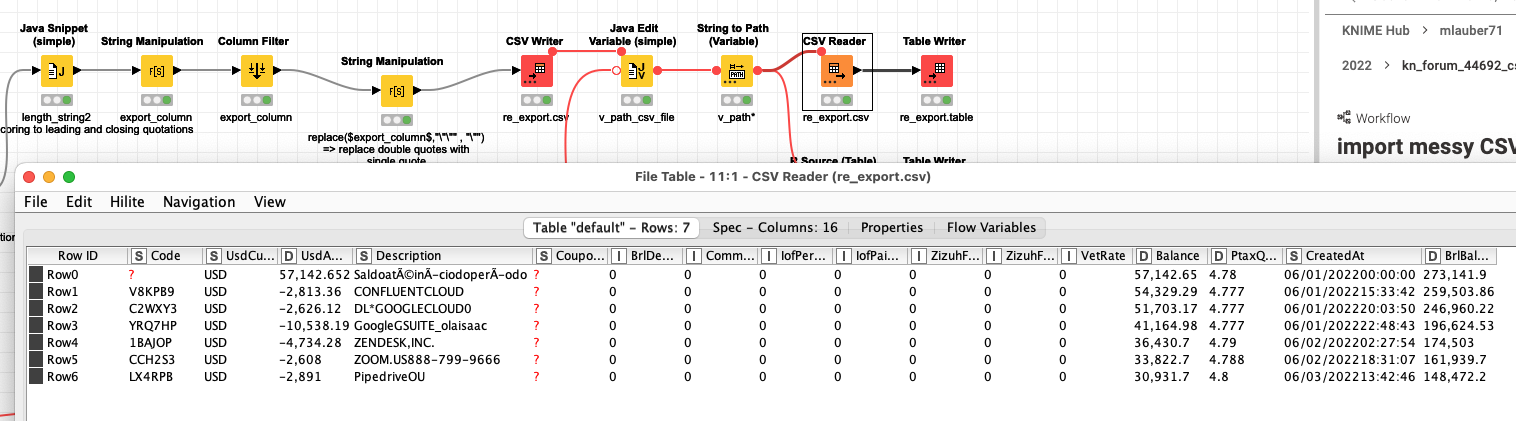
@Le18BR in line 6 there is a very messed up format. The whole line is enclosed in a quotation and then ZENDES, INC. (which has a comma in the name) again is enclosed in a double quote. Some cleanup might be necessary and if such things appear in a CSV file on a regular basis disaster is imminent. I will see if I can come up with a solution. Question ist would this be a pattern like quotes at the beginning and end or would there be all sorts of strange quotations.
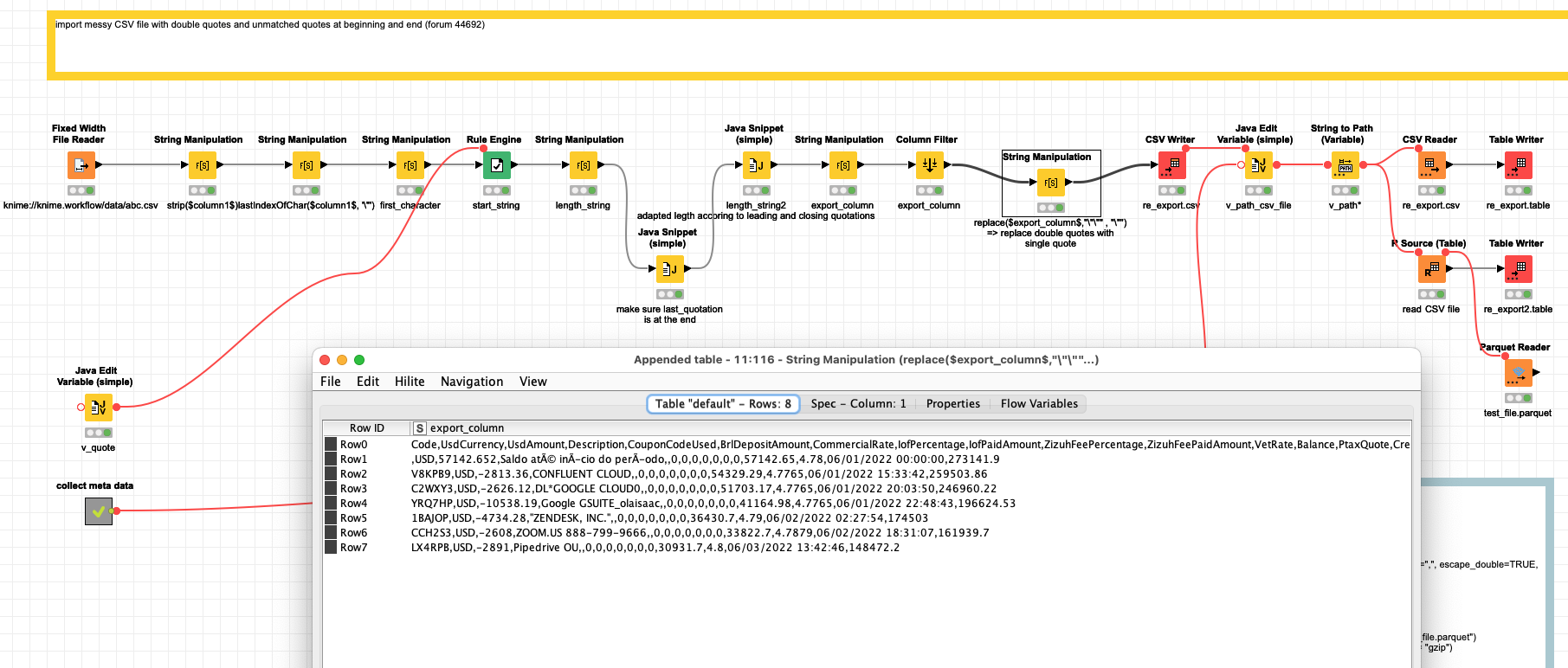
@Le18BR I built a workflow that would remove leading and closing quotation marks (if a ‘legitimate’ double quotation is in the first or last column the workflow will have to be modified).
The idea ist to read the CSV as one string in one column. Clean the columns according to several rules, export it again as CSV and then read the thing back into KNIME as a ‘clean’ CSV. The R Readr package should be able to handle double escapes but it did not work immediately.
Again my recommendation stands: use other file formats like Parquet, ARFF or SQLite to transfer data