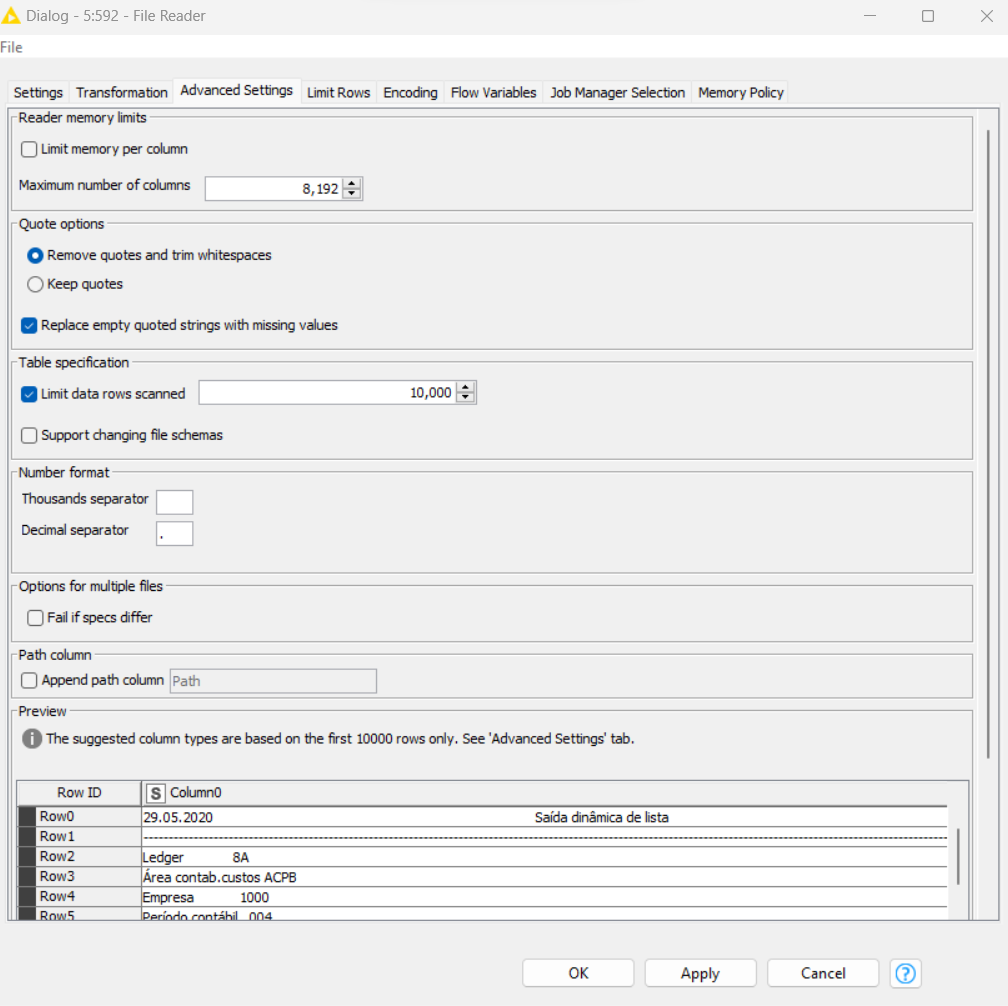
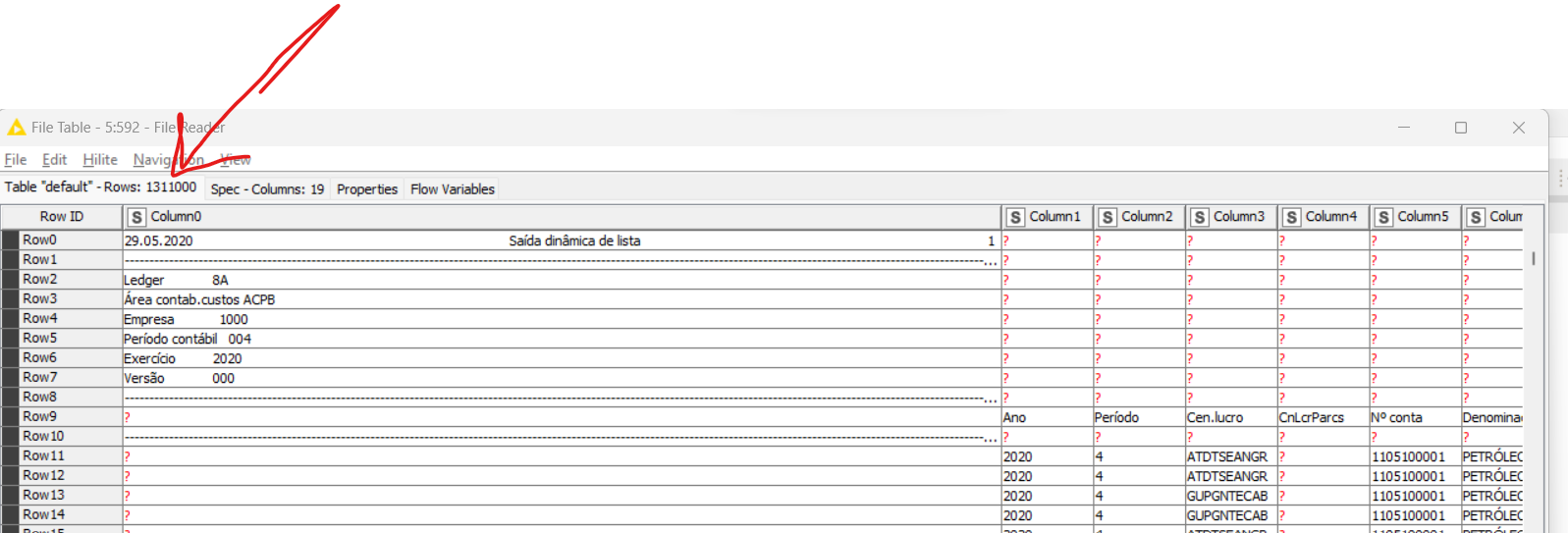
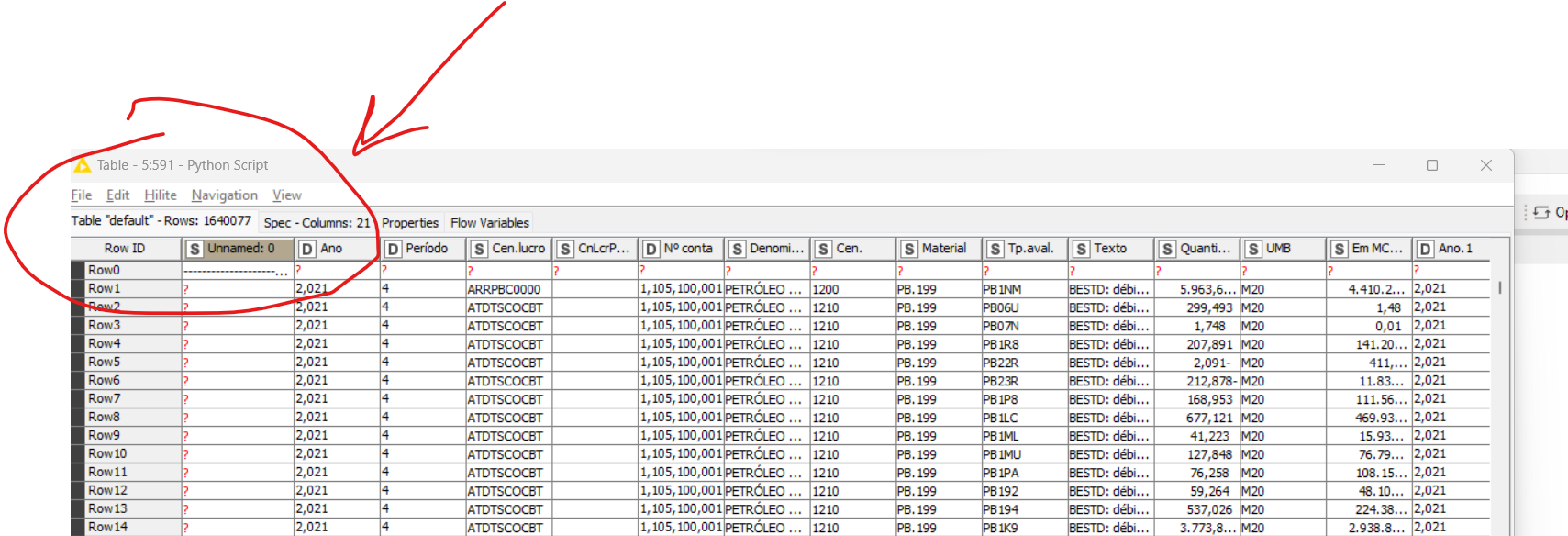
I am reading a txt file and the number of lines read is less than the content of the file. I tried using the file reader, the read csv, and I’m not succeeding. I set it to read via Python Script and it’s reading everything. What am I doing wrong? I have read many identical files to this one and only this one is giving me this problem. Attached is a screenshot of the configuration I used on the file reader.
Have you tried with Support short data rows off? To be honest, your python script output looks quite weird. It’s omitting all the header information?
Your first two screenshots show everything being read in accordance with your last screenshot, or am I reading it wrong? Is that a precise point where data starts to be omitted??
Ledger 8A
Área contab.custos ACPB
Empresa 1000
Período contábil 002
Exercício 2020
Versão 000
| Ano|Período|Cen.lucro |CnLcrParcs|Nº conta |Denominação |Cen.|Material |Tp.aval. |Texto | Quantidade|UMB| Em MCont.| Ano|Usuário |TD|Tipo|
|2020| 2|ATDTSEANGR| |1105100001|PETRÓLEO PRO PRÓPRIA|1055|PB.199 |PB19G |BESTD: débito/crédito material | 124,978-|M20| 13.866,97-|2020|Z550 | |ML |
|2020| 2|ATDTSEANGR| |1105100001|PETRÓLEO PRO PRÓPRIA|1055|PB.199 |PB1NG |BESTD: débito/crédito material | 154,188 |M20| 10.070,34 |2020|Z550 | |ML |
|2020| 2|GUPGNTECAB| |1105100001|PETRÓLEO PRO PRÓPRIA|0247|PB.199 |PB2CR |BESTD: débito/crédito material | 1.029,279-|M20| 281.647,22-|2020|Z550 | |ML |
|2020| 2|GUPGNTECAB| |1105100001|PETRÓLEO PRO PRÓPRIA|0247|PB.012 |PRODUZIDO |BESTD: débito/crédito material | 1.090,801-|M20| 275.344,63-|2020|Z550 | |ML |
|2020| 2|EE00000000| |1105100001|PETRÓLEO PRO PRÓPRIA|0630|PB.1ME |PRODUZIDO |BESTD: débito/crédito material | 1.355,539-|M20| 58.515,30-|2020|Z550 | |ML |
|2020| 2|ARREDUC000| |1105100001|PETRÓLEO PRO PRÓPRIA|1050|PB.199 |PB1QX |BESTD: débito/crédito material | 226,319 |M20| 0,27 |2020|Z550 | |ML |
|2020| 2|ARREDUC000| |1105100001|PETRÓLEO PRO PRÓPRIA|1050|PB.199 |PB06H |BESTD: débito/crédito material | 276,885 |M20| 0,32 |2020|Z550 | |ML |
|2020| 2|ARREDUC000| |1105100001|PETRÓLEO PRO PRÓPRIA|1050|PB.199 |PB15G |BESTD: débito/crédito material | 10.211,851-|M20| 1.406.487,71-|2020|Z550 | |ML |
|2020| 2|ARREDUC000| |1105100001|PETRÓLEO PRO PRÓPRIA|1050|PB.199 |PB29R |BESTD: débito/crédito material | 20.074,388 |M20| 1.376.827,28 |2020|Z550 | |ML |
I’m reading a folder with several files with this structure. The columns are separated by “|”. The first 9 lines are the beginning of the header. They have column names and a line full of dashes “-”. If I dont’t use “support short data rows” it causes a problem, I believe because of this line of “-”.
What’s even stranger is that I’m doing this process using the csv reader to read 10 years worth of files, and only one of them is causing this issue.
I forgot to mention that I am also trying to read only the specific file for the month/year that is causing the problem. It was at this point that I identified that the difference was due to the number of lines read.