I’m working on a prediction model for compound activity. I have already gone ahead made the workflow in order to predict chemical allergins based on their structure.
When I perform the cross-validation the outcome seems generally alright with high accuracy and ROC curves. Where I am encountering difficulty is with the ROC curve for the external validation. The external validation is too good.
Right now when I read the test set civ there are no positive class compounds – this means that the assessment isn’t binary since only one class is represented. So when I do the scoring, the model looks strong…but I don’t believe you results. Can someone offer me advice here?
@mlauber71 I am noticing this also. The data was curated by an advisor Is there any way that the outcome is like this because I converted a “document” to a csv? I tried to upload both as a csv and a document, but I’m getting this same outcome
@fath1 and your Activity is a double. The question is do you want to just predict a 0/1 outcome that is a binary model? Then you might have to employ another approach.
The activity doesn’t have to be double. That was a mistake, which I’ve now corrected to a a number (integer) form. I do want to predict an outcome of a binary model.
@fath1 first I think you will have to sort out the thing with your test and training data. This seems strange.
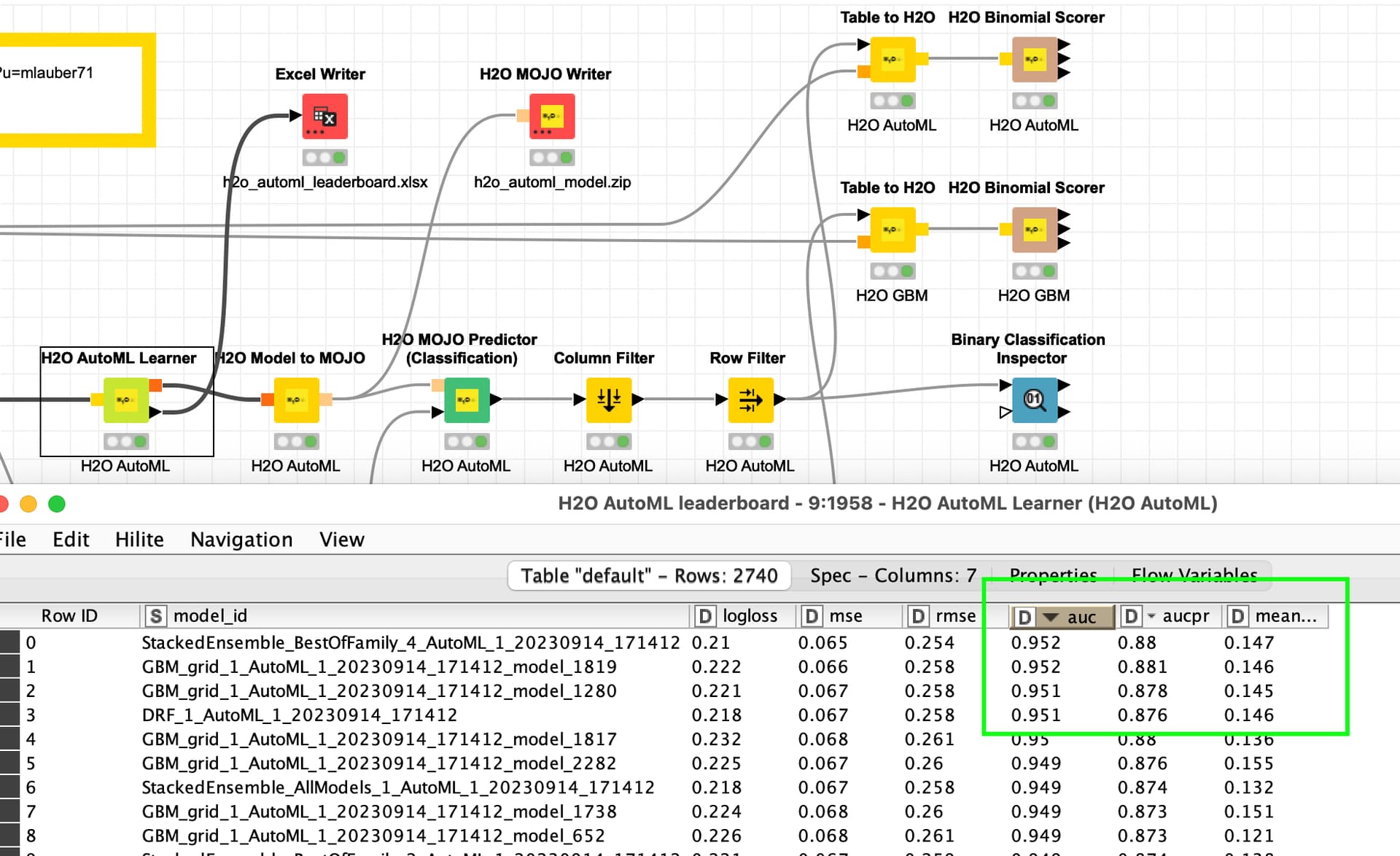
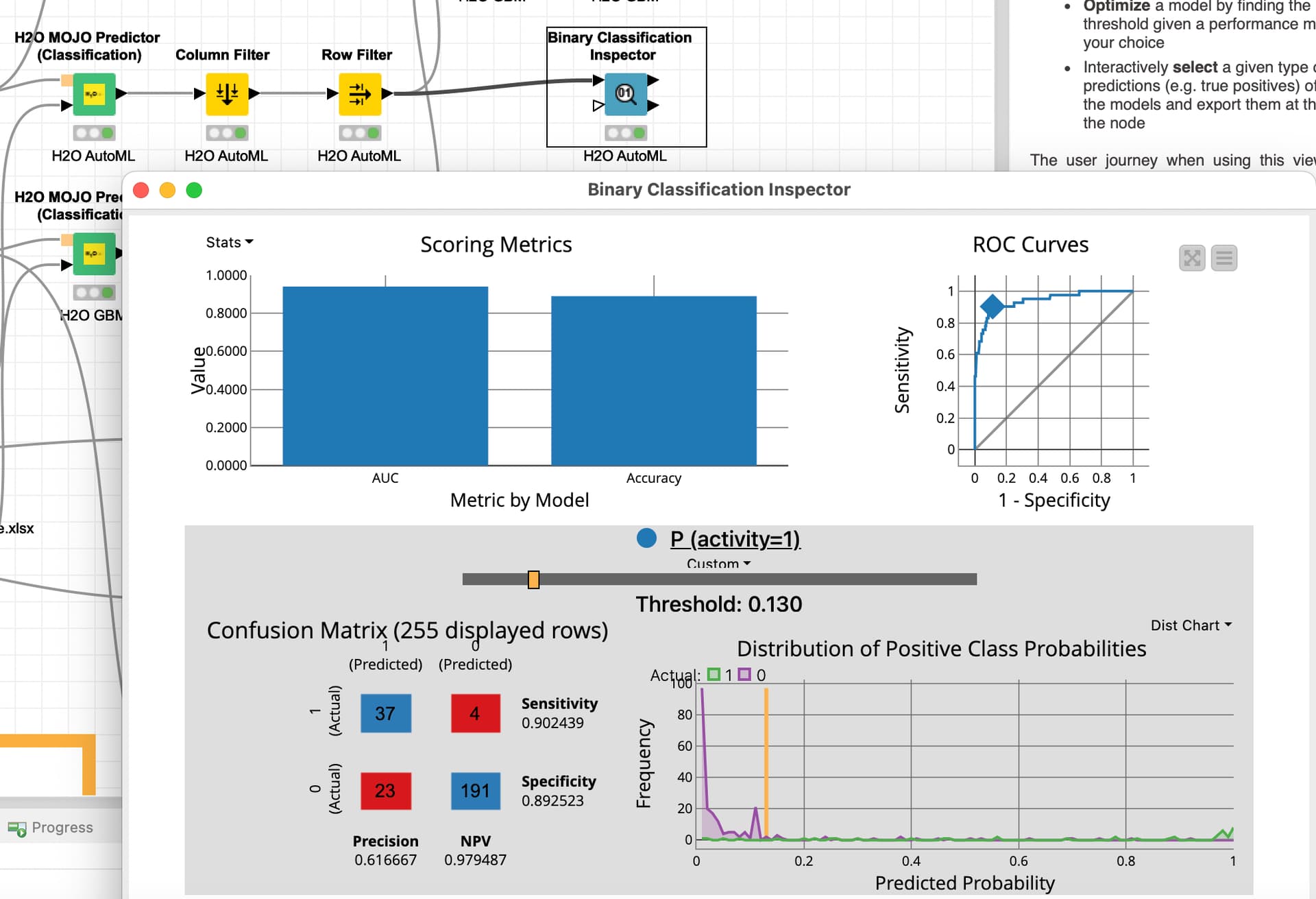
When you just use the training data and split them and train a model you get quite decent values with GBM models. Since this data is unbalanced you might opt for AUCPR as the deciding metric if you want to focus on the top group of Active=1.
You will have to think about what precision you want to accept and where to put the threshold - this very much depends on what happens to the wrongly classified cases. In this example: what would it mean if the 23 cases which are considered by the model to be 1 are in fact 0 and you would have acted upon the decision.
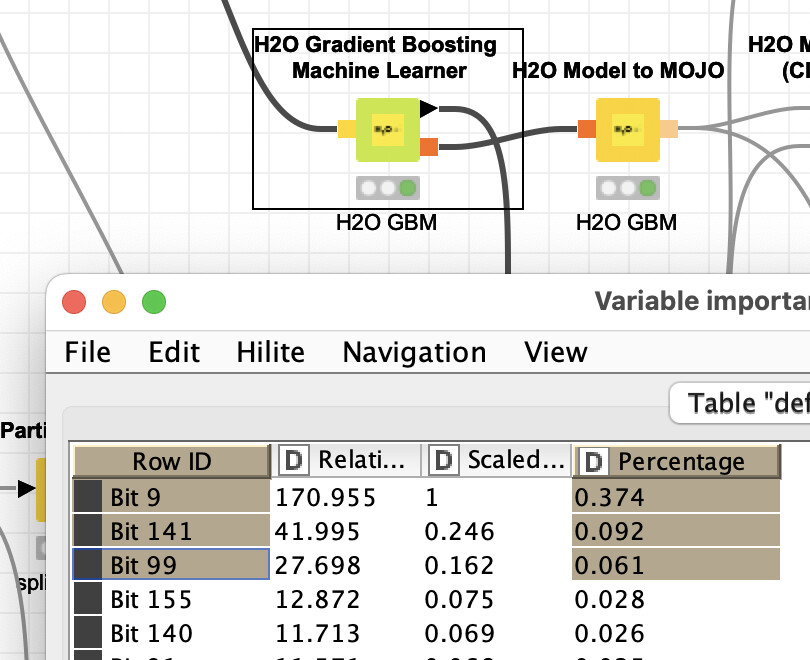
Then you might want to take a look at the data itself. I have no idea about the (business/scientific) domain of the case. With a quick GBM model 3 “Bits” take a significant amount of ‘explaining’ power. You might want to check with experts if this does make any sense. “Bit 9” is very prominent.
Since you have some 150+ variables you might think about some data engineering and data preparation. Maybe bring the number down to half of them. I have written an article about how to do that in an automatic way with the help of vtreat, but there are other techniques of dimension reduction (thread 1, thread 2).