Hi,
I need to solve a problem and I think I know how to do it but I’m not sure.
I have a set of data which are partitioned into clusters via K-means.
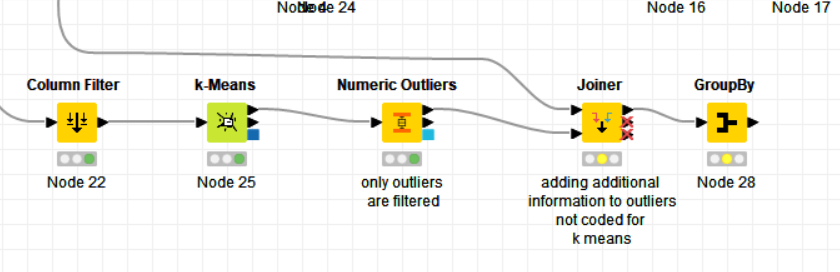
Then for each cluster I want to find out the Outlier. For this there is a node Numeric Outliers .
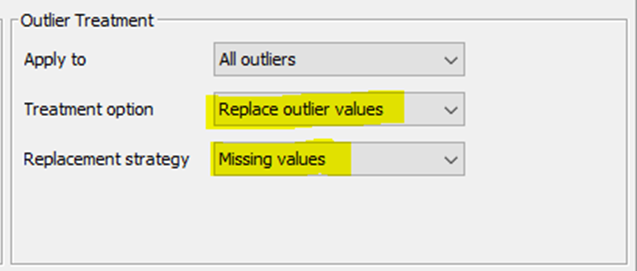
I have set the parameters for Outliers.
For each cluster I evaluated the outliers separately.
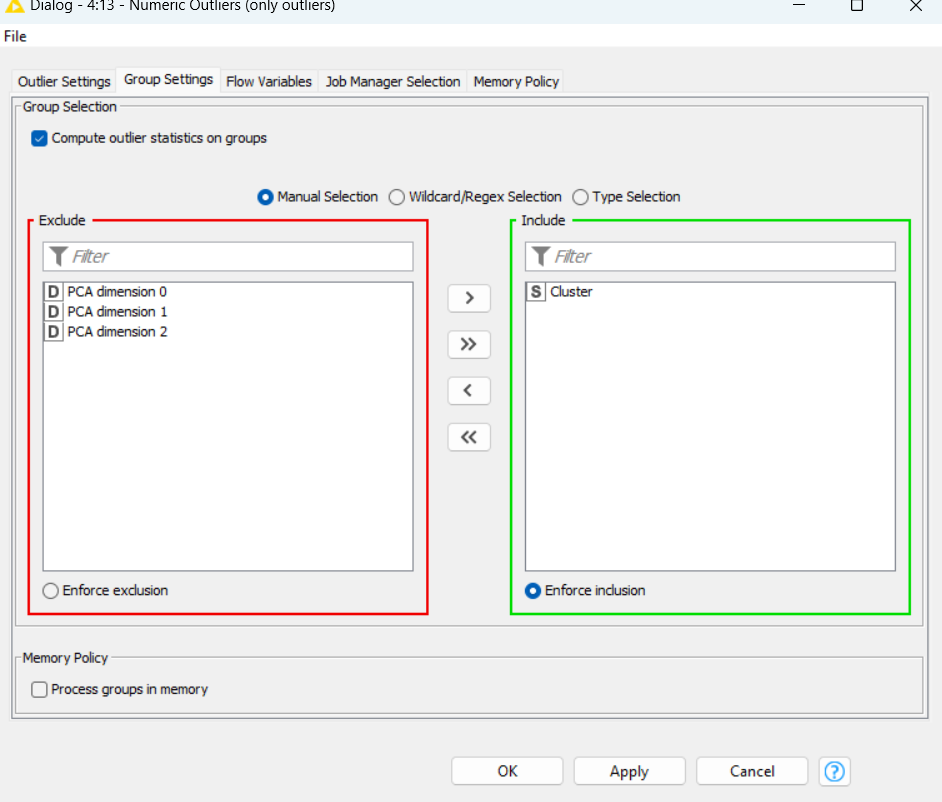
Because I have selected only a certain set of columns according to the node PCA , so then I will tighten the infomation before the PCA to be able to assess the already data or check it .
Is this the correct approach I am not sure.
I did not find any solved example for my problem .
Marek
Hello @MarekV
I looks fine for me; the problem I see is within your node configuration, as it is currently identifying many outlier… besides you should be aware about interquartile range multiplier; for some reason you have settled it as 3.0 (?)
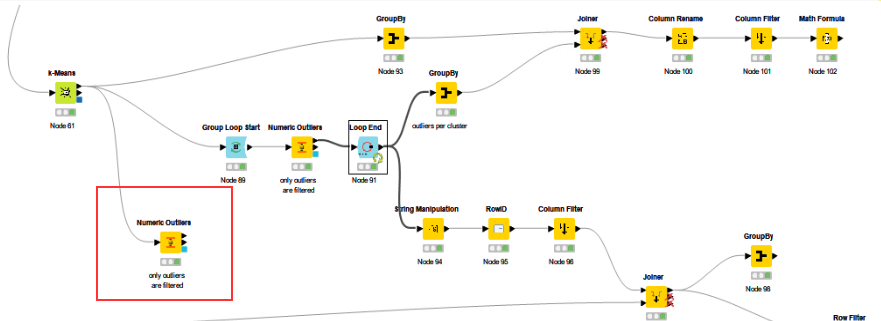
Suggested configuration, because you just want to identify them, for each of the PCA dimensions:
There are some other alternatives for outlier detection, as DBSCAN . You can find few examples in the following post -in my workflow you can inspect DBSCAN implementation as well-:
Hi @MarekV,
I use a similiar approach to look at the outliers. The truth is in the outliers not in the majority of the datapoints
I think you configured the “Numeric Outliers” Node slightly wrong. You do not need to do this GroupLoop Start / End looping for each Cluster as you can set this in the “Group Pane”. And then the addional nodes to get the RowID right are obsolete.
I chose 3 because I want to have as few oultiers as possible. I have a population of 130000 records and currently it shows up to a few thousand for cluster outliers . This is not desirable I need as few as possible . Unfortunately then I have to manually check if it is really ok .
There are very complex calculations involved.
I don’t want to identify for each PCA but together because in that record there are dependencies by rows not by columns .
I don’t know DBSCAN it seems it doesn’t need normalization and scaling. and I have used both because there is missing data in some records and potodobne.