Hello @MarekV
I looks fine for me; the problem I see is within your node configuration, as it is currently identifying many outlier… besides you should be aware about interquartile range multiplier; for some reason you have settled it as 3.0 (?)
Suggested configuration, because you just want to identify them, for each of the PCA dimensions:
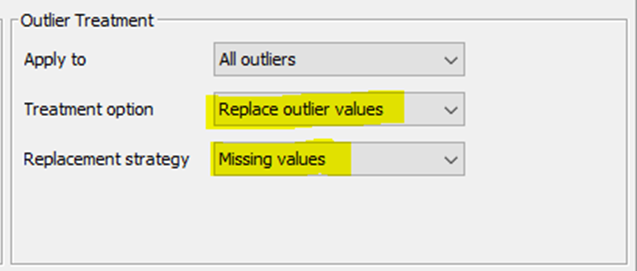
There are some other alternatives for outlier detection, as DBSCAN . You can find few examples in the following post -in my workflow you can inspect DBSCAN implementation as well-:
keep coding ![]()