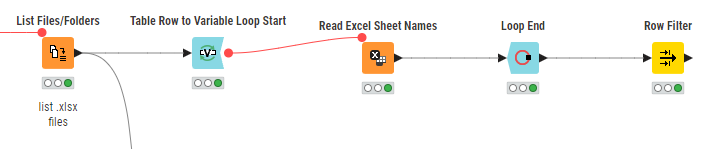
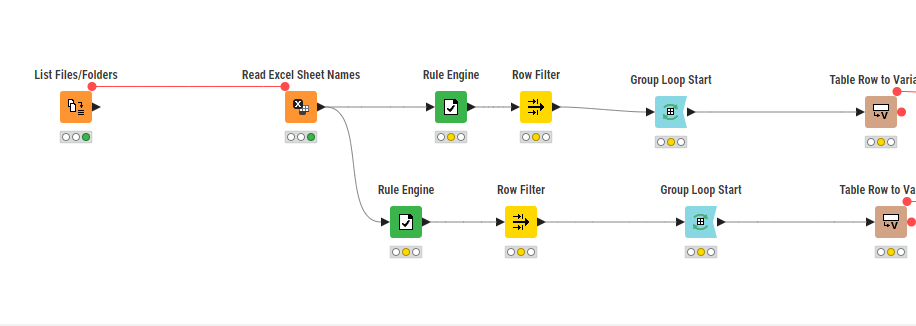
I have multiple Excel files in a folder and want to process them in parallel in a single KNIME workflow. Each file should be processed based on its sheet names not file names: if a file has a specific sheet name, it should follow a particular workflow path. I want to have each file and its matching sheet name run concurrently. Please let me know starting few nodes for this.
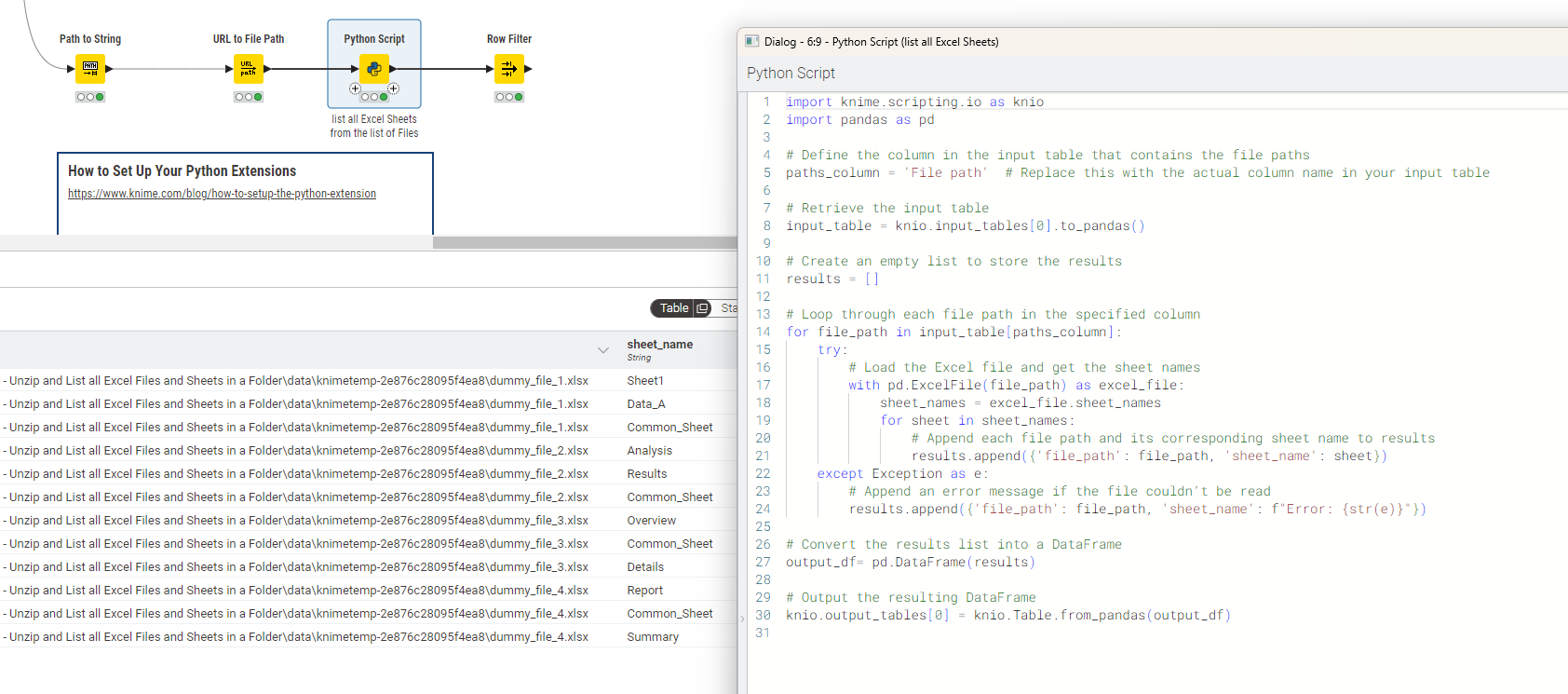
The issue is that using the “Read Excel Sheet Name” function on multiple large files takes over 15 minutes just to retrieve the sheet names. Is there a way to add a condition node that checks the sheet name, and if it matches a specified name, proceeds to read only that specific sheet?
I’ve attempted the same approach and to list all files. However, the challenge is that with a large number of high-volume files, the process becomes time-consuming. We’re working on a bulk data upload and aim to complete the process quickly. I’ve attached a workflow image for reference. Could you assist with optimizing this?
@san_98 we had a similar discussion before. Not sure if this is a bot thing? My suggestion: you try to plan out what it is you want to do - which data do you want to transfer where? For transfer zipping might be and option, also to do this in chunks, maybe.
I have multiple Excel files with large datasets, each containing a maximum of 2 sheets. I want to read all these files and then read the sheet names within each Excel file. The data from each sheet will be transferred to a designated SQL Server table, with a different table assigned to each sheet. For instance, if there are three Excel files in the folder, the data from the first Excel file will be loaded into Table1, the second file’s data into Table2, and the third file’s data into Table3. This process should run in parallel for efficiency.