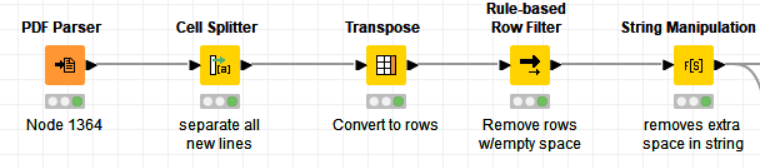
I would like to parse a pdf file that contains data in three different columns. When I use the cell splitter node and split on each line it breaks data that would be “wrapped” in excel into different rows.
For example:
The pdf does not create a perfect table so I cannot split on each new line as seen below
How do I split it so I can get:
I think ideally I would like to split by the section number.
@mmays maybe you can take a look at this entRy and links.
Also could you upload an example to explore? Then I had some Pxthon code trying to extract tables lately but was not satisfied with the result. Might take another look. There are several python packages that can extract tables from pdf.
I took a look at the links but I still cannot seem to get it to work. In the attached workflow I am close with the Regex split but I still run into the issue of the wrapped text.