I have uploaded here a file that contains 5 information about a transaction of our client (my client is the Beneficiary). Is there an algorithm that can detect patterns when our customer Canan AG suddenly does not use the same port of origin and port of destination for Applicant Aksu GmbH anymore, i.e. when it leaves the usual pattern? but it should not be suspicious if our customer has a different port of origin or port of destination for another applicant. Are there any similar sample workflows that would help me to solve this problem?
I thank you very much in advance and hope for your help.
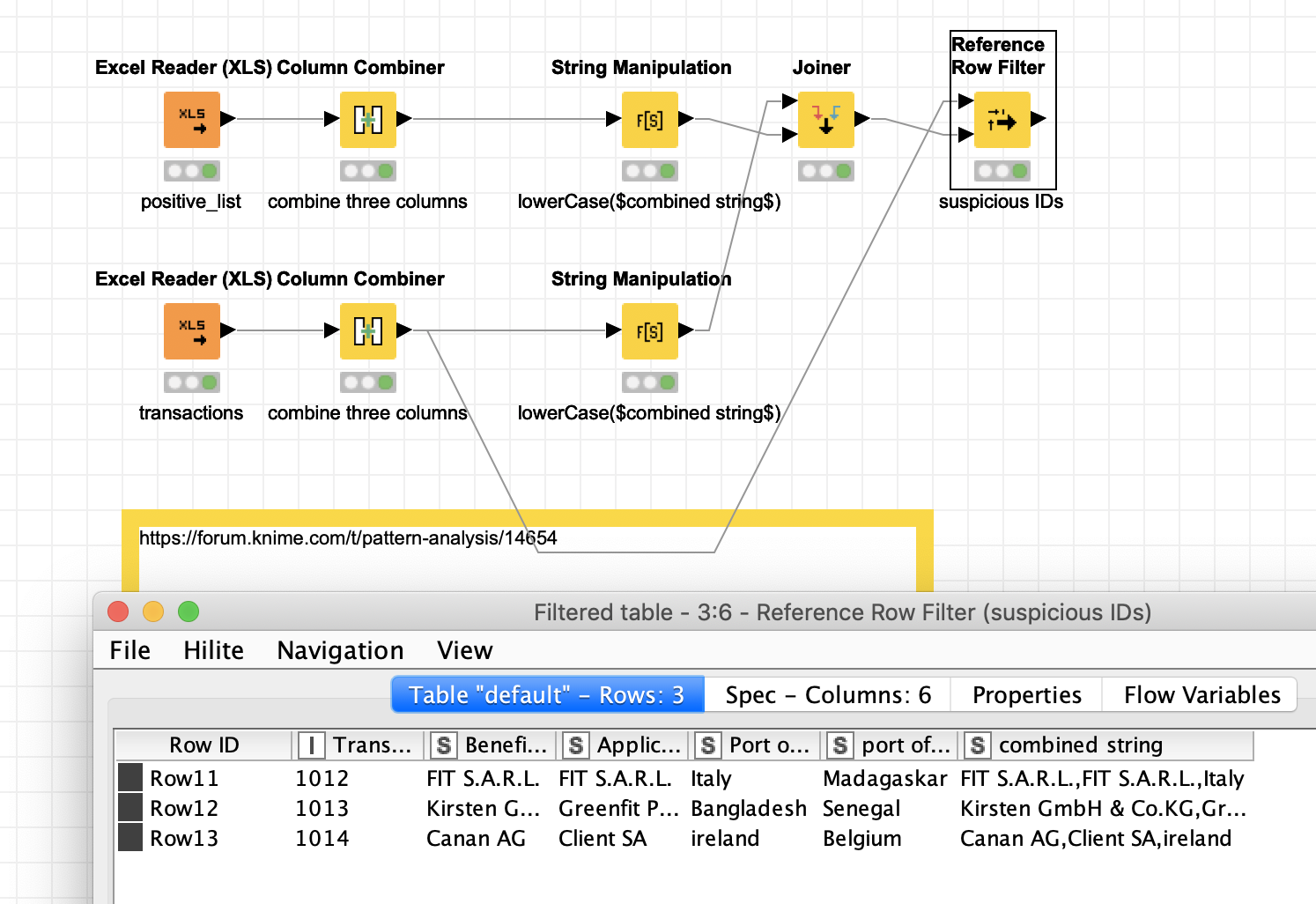
Question is what constitutes an ID to filter? If you use the combination of Beneficiary, Applicant and Port of origin you could create a ‘positive list’ of acceptable combinations and then filter out all transactions that do not fit into that (be aware of typos etc.).
If you think about more complicated rules you might have to tell us.
Hi MLauber71,
so the point is that i would like to train a model that already knows exactly these patterns and gives me a message in future business that it could be a suspicious business because it does not correspond to the previously known pattern.
if i then deliberately give the model a false example, he should tell me that this is a business that did not exist in the past.
What you did wasn’t a model, was it? Because there is no algorithm that you have used or?
One way or another you would have to constitute what an acceptable pattern is. I see this paths:
you could use a fixed pattern like in my model but that would mean you have to take care of typos and stuff like that
you could try and clean the texts though KNIME’s text mining methods so you will get back the ‘essence’ of the nouns. That would make the pattern more robust, but you might lose subtle changes that might be important (I am not an expert in text mining - there are several examples on the web also of address matching in Python mainly - it should be possible to adapt one of those - have not seen a specific address matching workflow in contrast to deduplication workflows - maybe someone with more experience can give a hint)
you could to the same and try to do some fuzzy matching of new values towards your standard set of acceptable terms - and if an entry does not match it gets flagged
if you have really large numbers of transactions and lots of historic data and you would only seldom get a new combination you could try a ‘numeric’ approach. If an order does not at least fit a pattern that has an 0.5% coverage it gets flagged (that only would work if your standard combinations are relatively stable)
I am also thinking about another approach but I am not sure yet if it is feasible. You could try and assign every ‘legitimate’ cleaned and prepared entry an ID like A, B, C or 1,2,3. Then you train an ‘excessive’ model like a random forest that is allowed to massively overfit so to build a perfect model.
You then use this model that should give you a perfect probability on new data. And if the probability goes beneath a threshold of say 0.85 the model is not sure how to handle and example because it does not fit a previous pattern. But that very much depends on the data as a whole and if such a multi class model could be computed in the first place. I have to think about the last one.