I have a question regarding the approach that was mentioned in the workflow shared in the link above.
The part where the columns where combined is really helpful, but I have troubles regarding the positive. @mlauber71 mentioned some ways to do so, but could you help me out by doing this without a positive list, because my dataset is to big so therefore it is impossible to create a positive list manually. Which nodes can I use to take all patterns which were combined as a positive list. But it should only take the patterns which occurs more than three times.i think i can find out the number of individual patterns with the help of node Extract table Dimension, or? after that I can use the java edit variable node to filter out the patterns where the number of occurrence is under 3. After that I can use the group by node to bring the patterns together to have just unique patterns. Does this make sense?
One more question regarding the prediction if it is a repeating business or not: When the occurrence of a transaction (pattern) is more than three times, it is a repeating business, if not than it is not a repeating business. this would be the classification. But how can I use these created patterns to build a predictive model, I mean how can I connect it?.
For me this sounds like you have various data and business questions that are connected and there is not just one (or two= algorithm solutions that can give you ‘answers’. You have to take into account with what kind of data you are dealing and what the process is:
can you create a positive list or do you have some historical data that is considered ‘correct’
could you use the logic of if a pattern occurs more than 3 times it is considered correct
with what degree of ‘cleaning’ and preprocessing of data combinations do you feel comfortable with to still answer your questions
if you have established a rule/model at the beginning you may need a process to handle incoming new patterns - would you check a list of new occurrences and flag them as correct or incorrect or would you use a pattern like (if it is three occurrences it is correct)
It is very difficult to give abstract recommendations and then come along a new ‘condition’ (can you list them in a systematic way that could be put into code or rules). Best way would be to have a meaningful sample file that represents your actual problem. A few lines may not be enough.
- can you create a positive list or do you have some historical data that is considered “correct”? Although I have historical data but they are not marked as correct. -Could you use the logic that if a pattern is more than 3 times, it is considered correct?
Yes, from three I can say that it is a repeated business so correct. -whit what degree of “cleaning” and pre-processing of data combinations do you feel comfortable with to still answer your questions
It is very important to me that the misspelled company names are assigned correctly. Since I am just with Fuzzy matching off. -if you have established a rule/model at the beginning you may need a process to handle incoming new patterns - would you check a list of new occurrences and flag them as correct or incorrect or would you use a pattern like (if it is three occurrences it is correct)
Of course, it would be best if my model already knows certain patterns and can say that it is correct in more than three transactions, but it would also be important to include new incoming transactions or patterns. For example, my model includes the patterns “ABC LTD. | XYZ PLC | | Germany | Thailand” and “Cap LTD. | TRF Limited | Croatia | China”. Pattern 1 (ABC LTD. | XYZ PLC. | Germany | Thailand) is featured 20 times in the model, and Pattern 2 (Cap LTD. | TRF Limited | Croatia | China) only appears 2 times in my model. Now, if a new transaction is checked that has the following constellation “ABC LTD. | XYZ PLC | | Germany | Thailand”, then it should be identified as “repeated business” as correct and the model then know that the pattern is 21 times instead 20 times available. Now, if a second transaction is to be checked with the constellation “Cap Ltd. | TRF Limited | Croatia | China” then the model should be able to recognize that the pattern occurs only twice and therefore it should be considered "not repeated business "and thus be classified as incorrect. But the model should include this business in the model and then know in the next transaction that it happens 3 times instead of 2 times. In the next transaction, it should then be identified as a “repeated business” since it is now three times available.
The problem with the data is that I have to keep it confidential and for that reason can not upload, otherwise I would have done it already. But I will in the next few days an anonymous file with my current workflow to make it easier for you to understand me.
Thank you so much.
yes i have tried this workflow for my fuzzy matching Problem, but my Question here was more regarding the Patterns without a positive list.
But also the workflow that @corey was uploaded isnt working for me because i have a big data set and the node “Hierarchical Clustering” is just used for small data sets.
Is there any other way to build the same workflow as @corey has uploaded or another node that i can use for larger data sets?
apart from fuzzy matching, i still ask myself how i can build a model that takes new incoming transactions into the model and then works based on them as mentioned above.
It is not clear why big data is a restriction. KNIME after reading data internally makes no difference to the table sources. Also, you can use any clustering algorithm to break your data set for groups and then use @Corey WF for those parts of smaller size.
In the node description there is the Note: This node works only on small data sets, because it has cubic complexity.
I have used it for my workflow and after 2 Hours it is 48 % completed. Which clustering algorithm caan i use to break my data set for Groups? or is there any other node which i can use instead of the node “Hierarchical Clustering”?
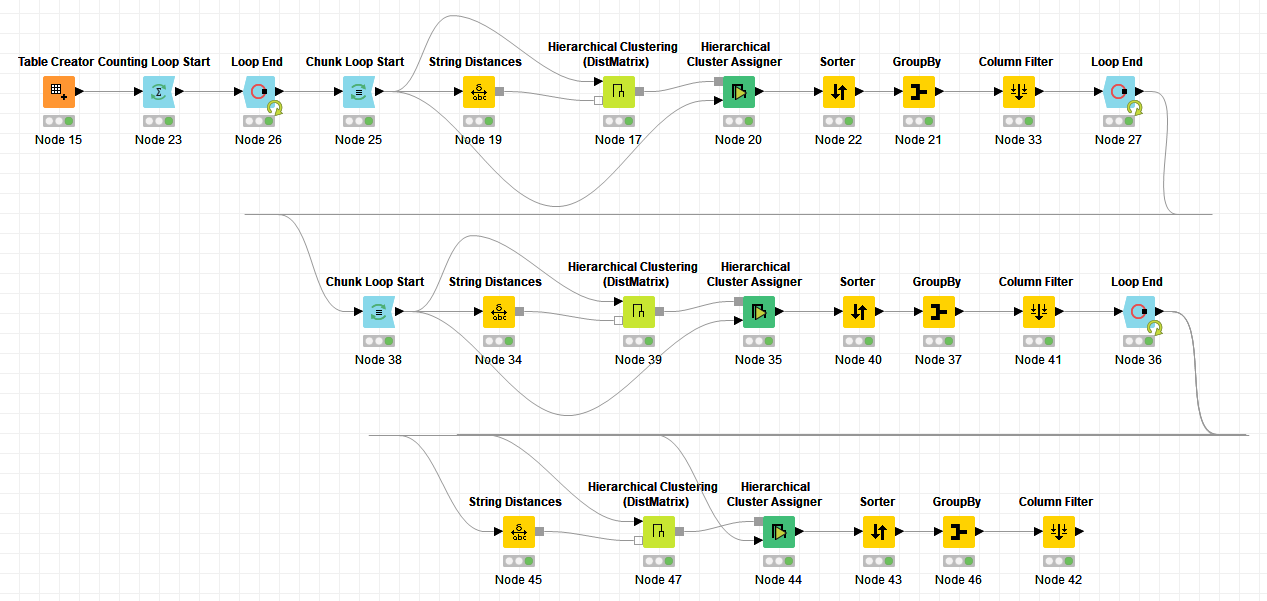
Here’s a way to process 100,000 records in just under 2 minutes. I’m not sure what ball park your data set is in but maybe this will give a new direction to explore at least.
The idea is that I’m applying the clustering, as @izaychik63 suggested, on partitions of the entire data set. The partitions are clustered and grouped by the most common name, and then run through another round of partitioning and clustering. This gets us, sort of, around the issue with the cubic complexity.
It works really well on my example data because there’s only 3 categories, so it reduces the size of the data set very quickly, you may need to add processing layers, or increase the number of data points run through each clustering algorithm if you try it. The later especially if you expect well over 100 unique classes.
Let me know what you guys think. I’m sure we can find a solution that works.
Got this problem was stuck in my head this morning. I don’t think my solution would be practical with real world data so I tweaked it a little.
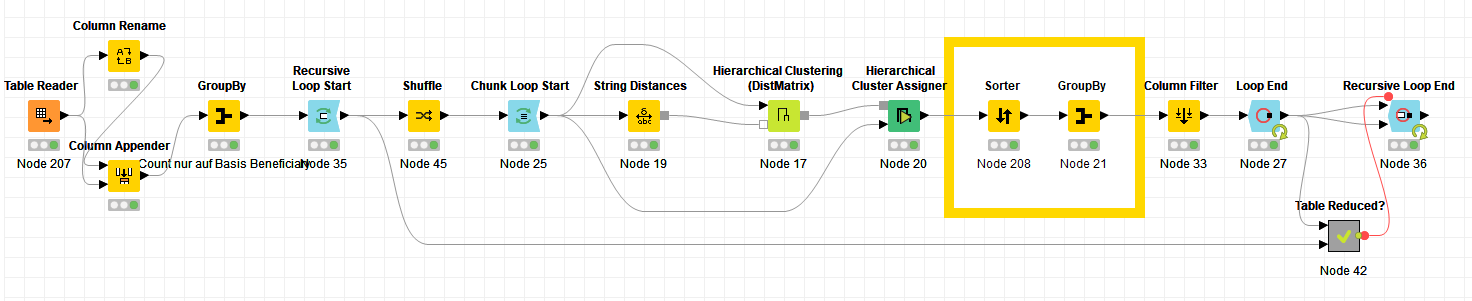
Found some more realistic data, list of words and common spelling errors, and slapped the chunking loop in a recursive loops that ends when the table is no longer shrinking. Also added a shuffling node to make sure clustering doesn’t just wind up ending early when each partition itself happens to be filled with unique classes.
That’s the right spot, in my workflow the cluster number is filtered out just before the end of the chunk loop.
Given that we’re recursively running a bunch of cluster assigners that number kind of loses it’s meaning for us and we just use it for the group by.
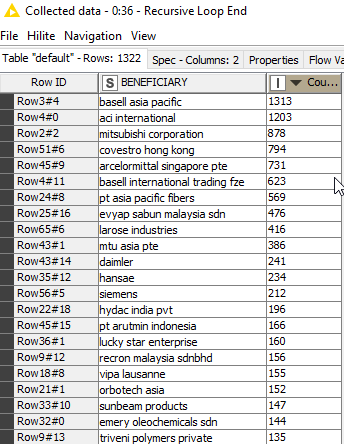
We can add in a count of how many strings were clustered into these final business names at the output though by modifying the group by node after the cluster assigner like below:
The nodes in the box are the changed portion. The sorter comes in to sort by the count of string occurrences. That way when we grab first string from a cluster in the next node we’re grabbing a better one. That group by node also can be changed to aggregate the count as a sum.
this is excactly what I was searching for, thank you so so much for your help, really I appreciate that
I am so happy that it works now
But one more Question regarding this. For the Problem that i mentioned above we assigned all names in one cluster to the Name which occurs the most Right?
And when I would do the same for Country names where I have the Right Name to assign, how am I have to do this? Is it also hierarchical clustering or something else?
This Country names should be the Right names. KNIME_CountryNames.xlsx (14.5 KB)
The following document contains spelling mistakes e.g. German instead of Germany. It should now be possible to recognize this and to assign the correct name (the correct name is given in the document above). PortofOriginAndDestination.xlsx (630.2 KB)
I have tried to use the same workflow but I dont know where i can put the List with the Right names.
Correct, then the count is updated to include the strings added to the cluster and the clustering is repeated.
Clustering is something you’ll do when you have no list of “correct” values to match to. In your Country names example here you may want to play around with the similarity search node using a Levenshtein Distance (it’s for strings).
One other general note that I don’t think we addressed in the thread, it’s probably a good choice to lower or uppercase all your strings before getting to into the processing, a =/= A unfortunately!
For the Yellow part of the workflow i have used this file KNIME_CountryNames.xlsx (14.5 KB). The yellow area serves to assign the correct name to the country names existing in the blue area and possibly misspelled. if, for example, Thailand was written as “Tailand” in the blue area, reference should be made to the list added in the yellow area, since it contains the correct name, i.e. “Thailand”. Tailand is to become Thailand.
Do you know how to go on with this? I have tried the similarity search but it doesnt give me the new Name.