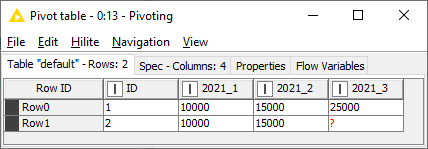
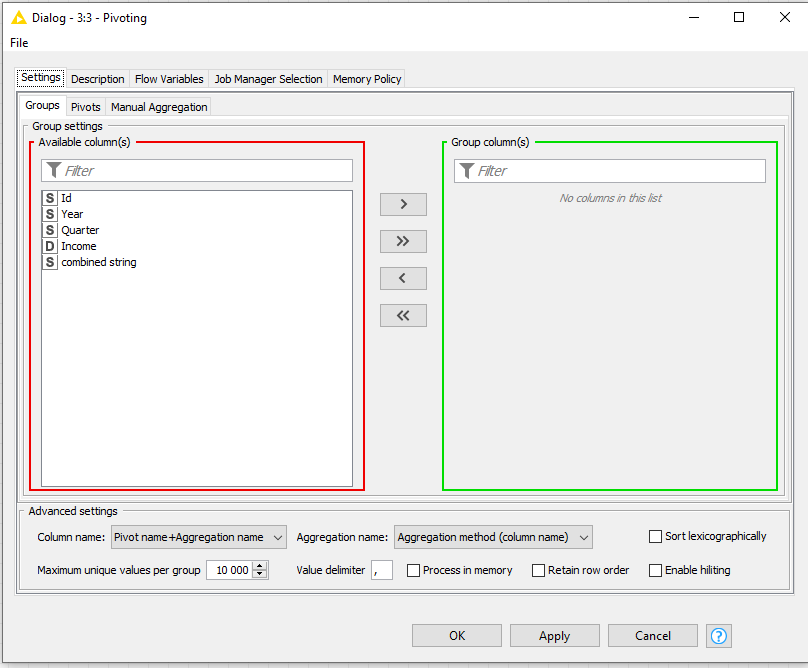
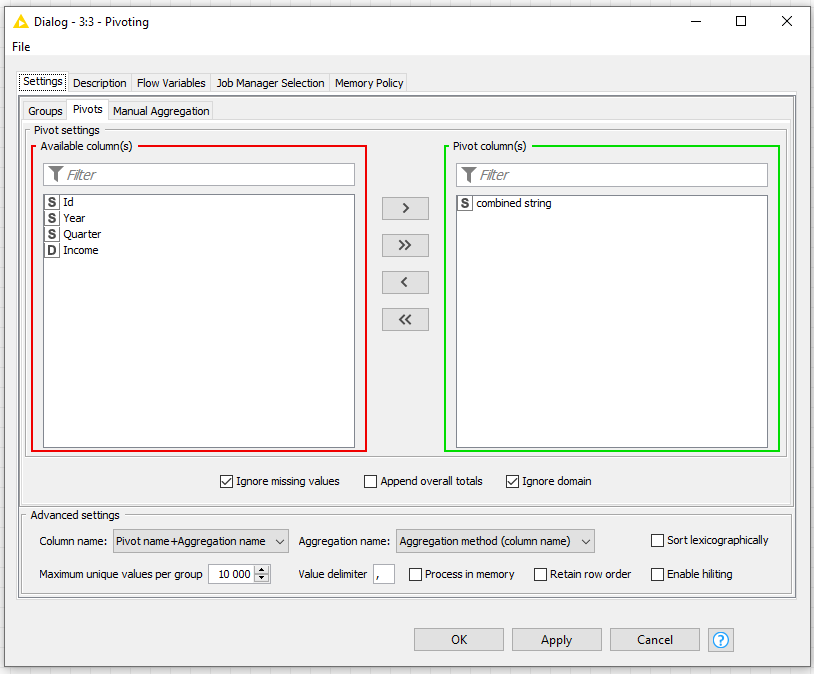
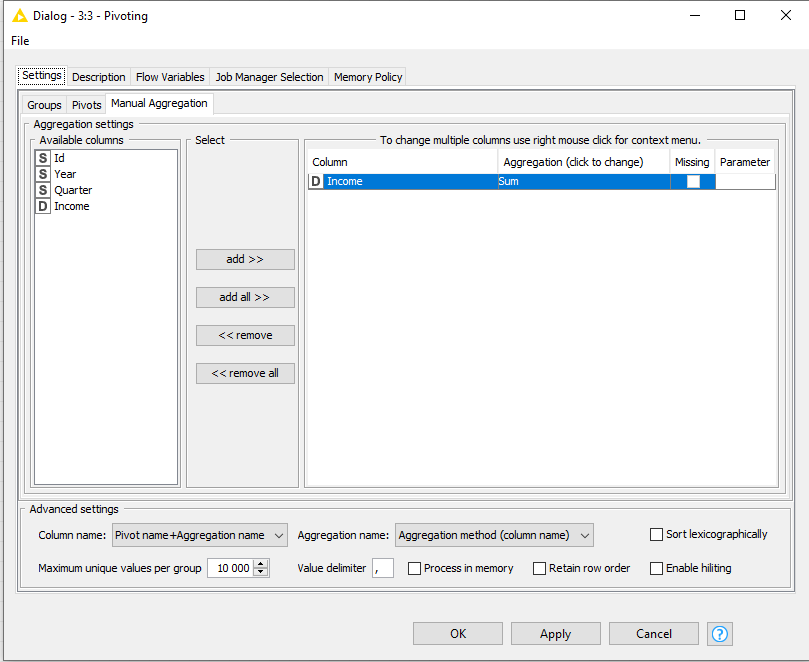
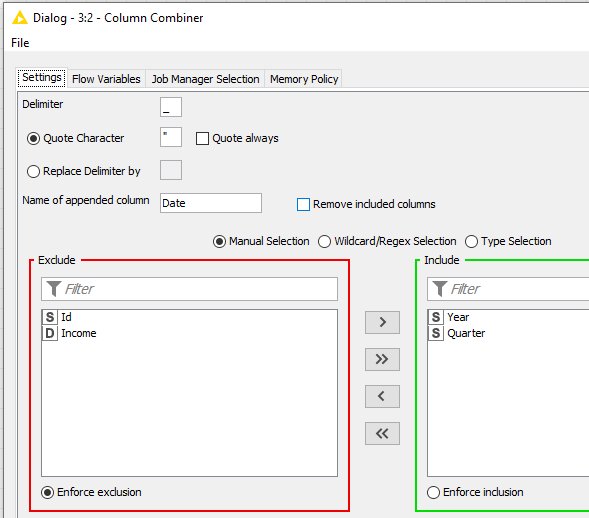
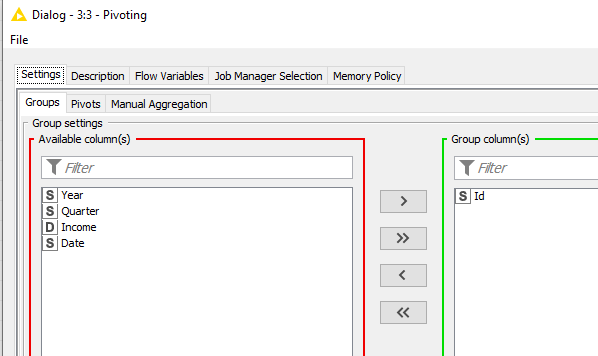
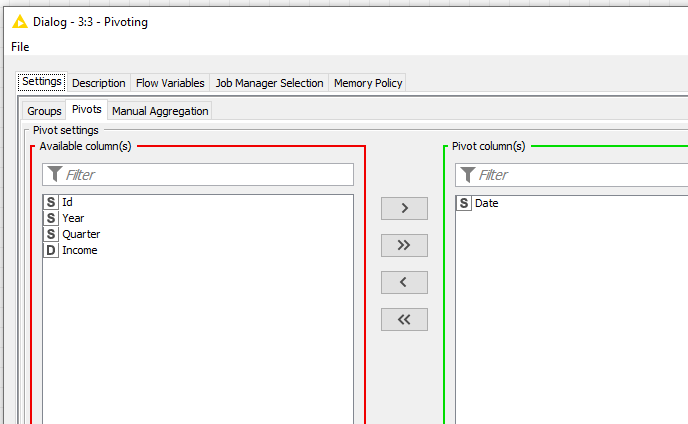
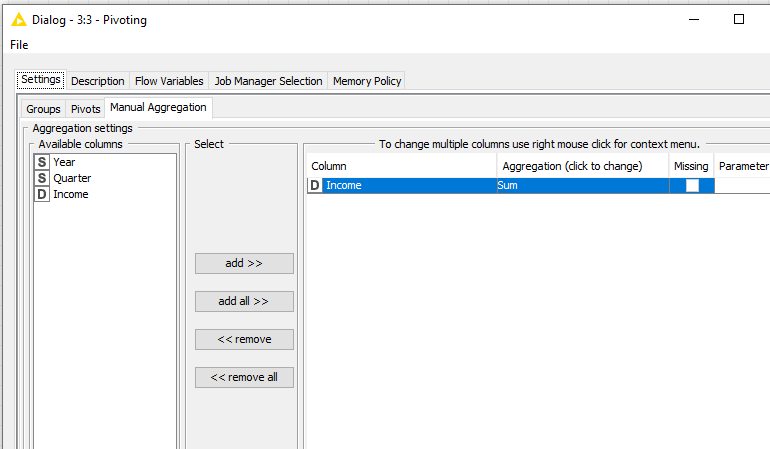
Regarding the pivoting node. I make a pivot on year and quarter and then an aggregation on income, however I want the value of the aggregation to appear in the pivot year and quarter column and not in an extra income column. How can I define this?
You’ve written your post as if we all know what you’re talking about and what your data table looks like.
We don’t, and just from your description it’s difficult (at least for me) to imagine/recreate what your data must look like in order to get an answer that helps you solve your problem.
It’d be much easier for everyone if you provided the workflow you’ve completed so far, or at least some data and your desired outcome so that we can help.
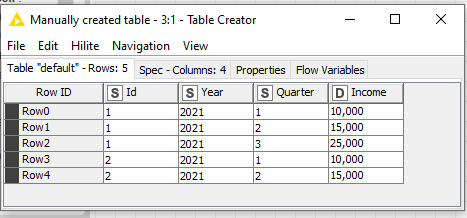
ID YEAR QUARTER INCOME
1 2021 1 10000
1 2021 2 15000
1 2021 3 25000
2 2021 1 10000
2 2021 2 15000
Now I want to create a pivot on YEAR-QUARTER holding the aggregated value:
so I would like to get the following result
ID 2021-1 2021-2 2021-3
1 10.000 15.000 25.000
However knime creates 1 column for the pivot but also one extra column for the aggregation so I get the following result, but I want to have only the pivot column with the aggregated value and no extra aggregated columns. Removing the columns afterwards is not a solution cause I don’t know in advance how many columns were created
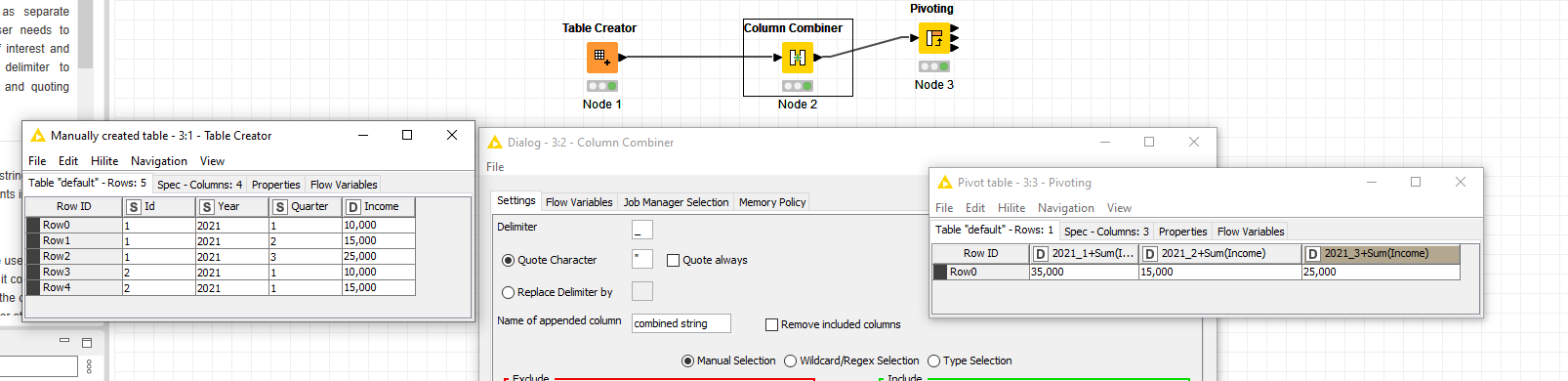
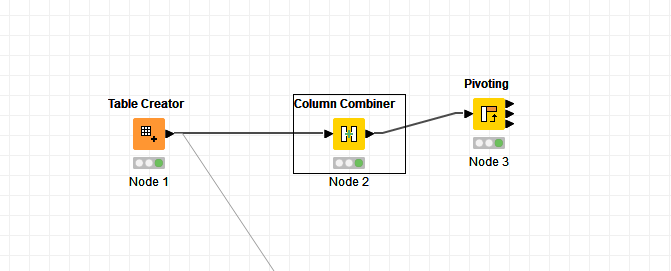
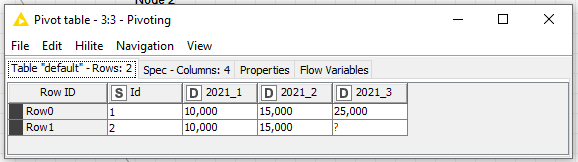
When I take your data and use the Pivoting node to group by ID, pivot on Year and Quarter, then aggregate on Income using First, I get the following result:
I do the same (but with additional columns). However I get these extra columns in the result.
My question is the pivot part generates new columns, however the aggregation part also generates new columns, how did you combine these 2 parts, because on my case it generates separates columns and not combined ones.
for data example you shared @elsamuel solution (usage of one Pivoting node) works just fine to get your desired output. Seems to me you are saying that you have some additional columns. Can you maybe share workflow example so we can take a look at what is troubling you? See here how to create reproducible workflow examples: