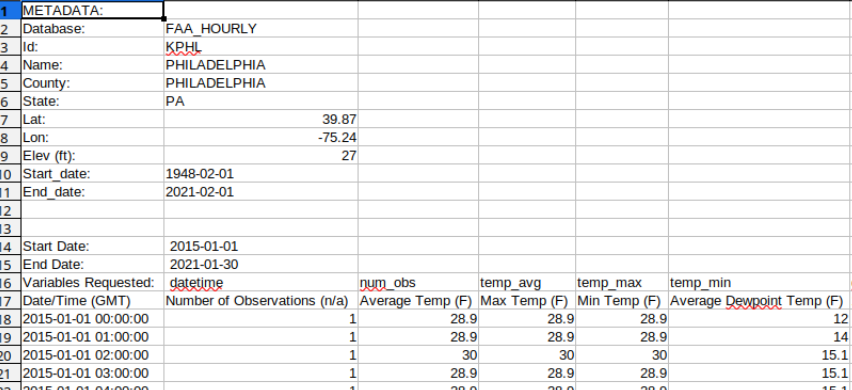
I am loading a .csv file that begins with metadata, then a table. I’m trying to take two fields from the metadata and populate two columns (for all rows).
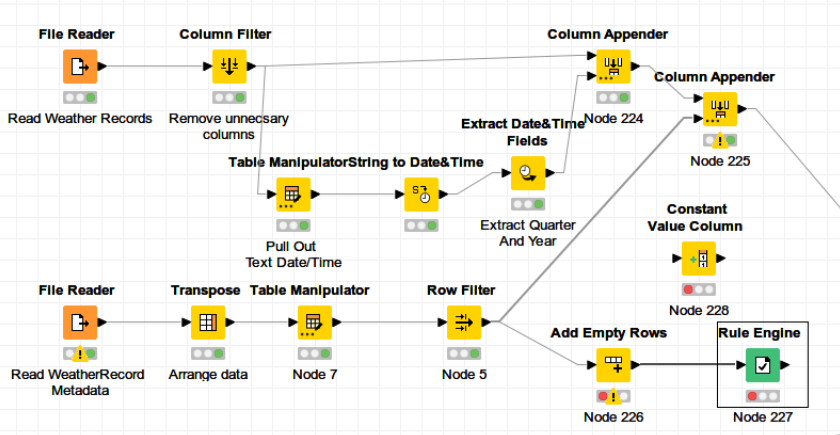
Here is my workflow that successfully grabs the two fields of metadata, and transposes them into 1 row of two columns. I want to append those columns to the weather record columns, and repeat them for all the rows for that particular .csv though I’m stuck on how to do so. I’ve considered adding empty rows for just the two columns, though I can’t see a flow variable that would tell me how many rows of weather record data has been loaded. I’ve also explored Constant Value Column, though that has the same limitation.
I would try using a Table Row to Variable node after your node that has the table of metadata.
Then you can use two Constant Value nodes (one for each item of metadata) to append new columns containing that item of metadata to all the rows in your bigger table.
It would help if you posted a downloadable workflow and/or some example data.
That appears to get me a little farther along, though I’m having a hard time understanding exactly what is going on with the Constant Value Column. It seems to be putting out both columns, but only one row shows up in the output of the appender. Node 225 looks correct for one row, but there are thousands of other rows.
Ok, the text file seems the most understandable at the current time. I’ve had to abbreviate it as it was originally too big to upload. faa_hourly-KPNE_20150101-20210130.txt (1.7 MB)