I’m attempting to update a google sheet with a table that’s roughly 80k rows and 29 columns, using the Google Sheets Appender node. I’m just adding a new tab to the sheet and writing out the data. This is consistently erroring with the following error message:
ERROR Google Sheets Appender 0:572:567 Execute failed: Read timed out
In the same workflow, I am also attempting to update an existing tab in the same sheet where it clears out and replaces the records each time it runs. Similar volume, and it is also getting this time out error.
Occasionally, I find that the updates to the sheet happen even though the process errored out, so this really seems to be a matter of just needing the process to wait a bit longer for this action to complete.
Can someone point me to how this timeout setting can be increased? (This is on Knime desktop, not server.)
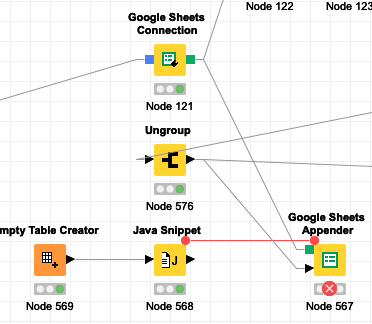
Hi @bruno29a - much appreciated, and I will share what I can via screenshots. The problem is pretty well contained to the one node - everything upstream executes fine, and the problem is replicable just executing the Google Sheets Appender node.
Feeding into that node are 3 items:
Google Sheets Connection
The data itself (a 79,199 by 29 table)
A Flow Variable used to specify the new tab name
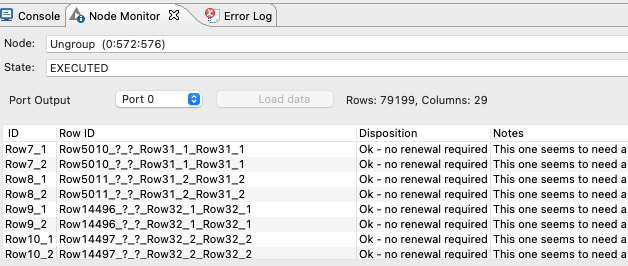
Here’s a screenshot of the data coming in from the “Ungroup” node right before:
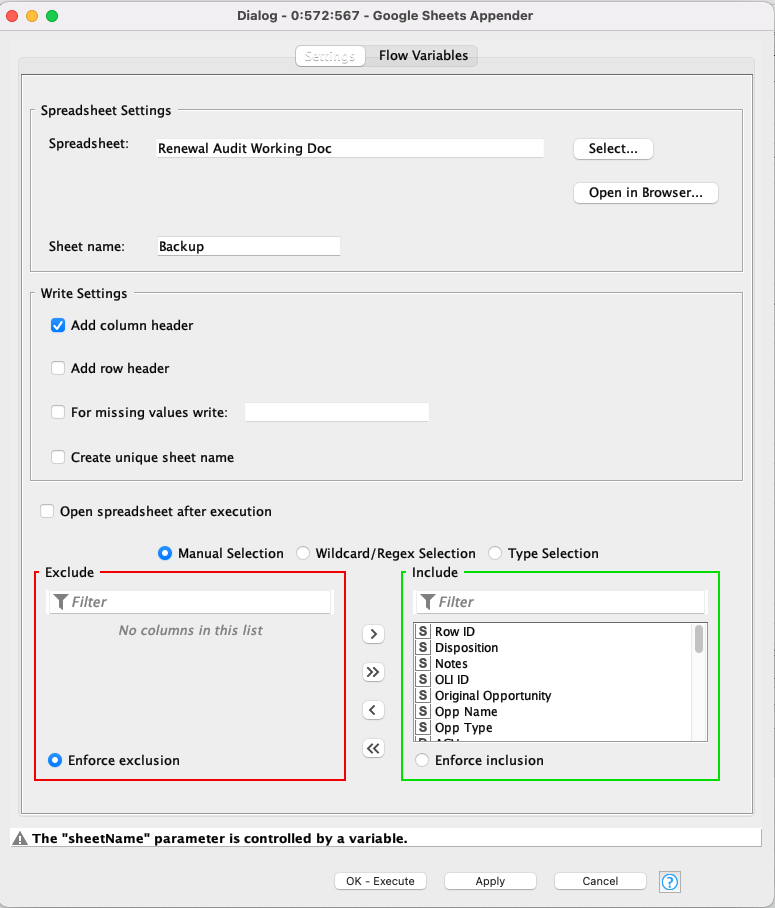
Here are the configuration screen for the Google Sheets Appender:
Hi @scottb , thanks for sharing the workflow. One of the advice I always give when dealing with connection is to establish the connection only just before the operation. In your case, it looks like the Google Sheets Connection is established way before, and remains idle while other processes are running (Java Snippet, Ungroup, and other processes that I cannot see from the screenshot), to then eventually try to use the connection.
Connections do not last forever, and as a security precautions, are cut after a certain time by the server/host, especially after a certain idle time. Could it be that your connection has expired by the time you want to run the Google Sheets Appender?
The best way to avoid this from happening is to link your Ungroup node to the Google Sheets Connection, that way it will establish only after the Ungroup is executed, and just before the Google Sheets Appender is run.
You may have to separate the connection, as I see it being used for other nodes that I cannot see in the screenshot.
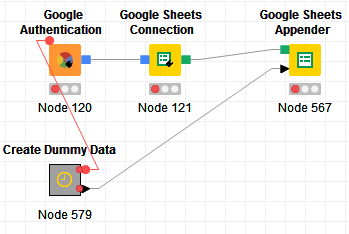
Here’s a much simplified sample workflow that replicates the issue much more directly, and has essentially nothing between the connection and the google sheet node. Hopefully this helps narrow this down. Appreciate the brain power on this one!
Hi @scottb , unfortunately I cannot test this on my side as it requires some authentication. I’ll take this opportunity though to show you what I meant by linking certain nodes to connection nodes that minimize the risk of running into expired connections:
Yep- that totally makes sense, and I have hit the timed out connection before. That’s not what I’m hitting here however, given that the dummy data generator runs in just a few seconds. It is acting like it’s trying to process the entire transaction in a single api call, and Knime is just not waiting long enough - hence my question about whether we can increase the timeout.
Tomorrow I will try to investigate whether it is possible to break up the output into a loop that only attempts to write x rows to google at a time. I am more than open to any other ideas here though!
Thanks @ipazin - for the google sheets appender node, because it is totally self-contained I don’t see that there’s an opportunity to add a wait between the start of the operation and waiting for google to process the results in this case, so not sure that I can apply the workaround to this example.
Do let me know if I have totally missed the idea here!
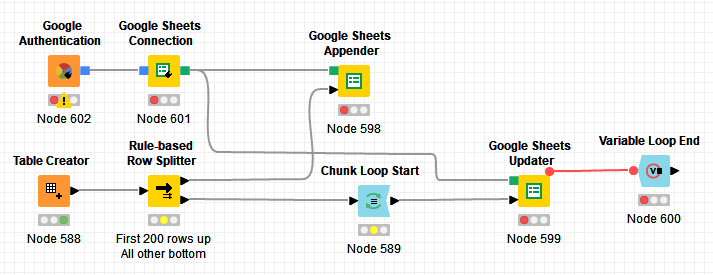
There’s almost certainly a more elegant way of doing this, but this was what I was able to quickly throw together as a potentially viable workaround for this issue. In this case, I need to use the Google Sheets Appender node for the first set of records to establish the new tab, and the Google Sheets Updater node for all subsequent writes. I used a “Java If” node to drive this, though not sure if that’s the best approach. I used breakpoint nodes after the Google nodes just as a way to tie them into the flow of the loop.
At 200 records per chunk, each write takes about 1 second and has no problem completing within the timeout period.
glad you found a way. Idea is to use Try/Catch nodes but your approach seems fine as well. Personally wouldn’t use Breakpoint node as it’s a bit confusing but don’t think it will do any harm.
Hi @ipazin - thanks for the feedback. I’m definitely trying to learn and adopt best practices here, and I fully acknowledge that just because I found “a way” that doesn’t mean there’s not a better, more efficient/scalable (or just less convoluted) way.
In that spirit, let me ask a couple of follow up questions.
With the Try/Catch approach, I understand how that would help me gracefully proceed if I hit the error, such as putting in a retry, a delay, etc., and I see how that would be great if your API request is requires polling until a result is available. Since the Google Sheets error I’m getting is the timeout of a single node (which is both making the API request to write all of the data as well as waiting for the reply), I’m not clear on the action I would take if it encounters an exception?
For the breakpoint node, out of curiosity, what would you choose in this case? I don’t see that there’s a generic “no-op” or “pass through” node - that would be ideal in this type of situation, but I may just be looking for the wrong thing…
Many thanks for all you’re contributing to this forum!
Simply re-execute. Of course this doesn’t make sense if you are constantly (every time) hitting this error (which seems you do from your original post). Check this topic for more on this approach:
Think I used Column Rename node first time. But whatever node is used I would make sure to document it with “Dummy” or “pass through” node for example. You are right, there is no such node (see here). This would be my approach:
@ipazin - Thanks so much for the response here! One (hopefully) last question… How would you ensure that the Google Sheets Updater doesn’t start before the first call to the Appender is completed? Is it enough to just connect the variable output from the Appender to the variable input of the Chunk Loop Start?