Hello,
Since version 4.6.0, KNIME’s changelog has announced enhancement “AP-17553: Allow keeping RowIDs when joining”. This appears to have been done in the context of this forum topic
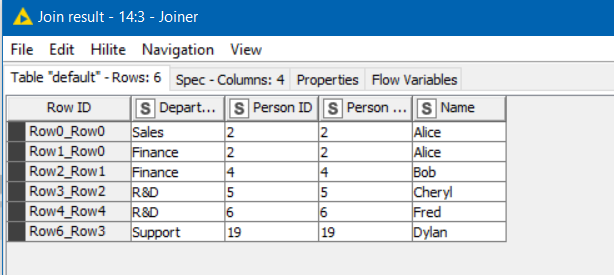
Unfortunately, it appears that, despite the new “Keep row keys” option in the Joiner node, the recent Joiner node still forces you to concatenate row identifiers even if the row identifiers continue to ensure uniqueness in the joined set.
Let’s take an example. You want to add a column from another data set (hereafter named the “right set”) to an original set (hereafter named the “left set”), based on an attribute column in the original set, which happens to uniquely identify the rows in the right set. This join is equivalent to a simple left lookup, which will and should not change the number of rows in the left set.
Let’s also suppose that the cardinality of this attribute column (which allows us to include additional information from the right set) between both sets is “many to one”, in other words, for one row in the right set, you have many rows in the left set.
If you try to perform a LEFT OUTER JOIN using Joiner node (ticking “Matching rows” and “Left unmatched rows”) while matching on the said attribute column, Joiner forces you to tick the “Concatenate original keys” option. If you try to tick the “Keep row keys” option, Joiner refuses to be executed by throwing an error beforehand, such as: “Cannot reuse input row keys for output. The Join criteria do not explicitly ensure the equality of row keys: the output table contains matched rows but row keys are not among the matched the join columns”.
This error message is confusing because when I ask Joiner to split the results into 3 sets (matched, left unmatched, right unmatched), the right unmatched rows set has zero observations. This confirms that what happend was a LEFT OUTER JOIN. Please note that the matching criteria did not actually specify the Row Identifiers in the left set but only an attribute column therein.
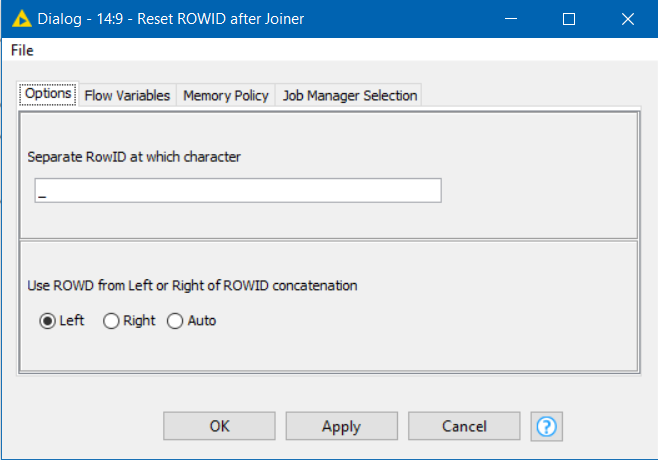
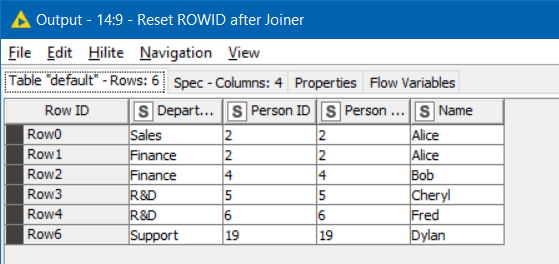
If you use the now deprecated Joiner node to perform the same transaction, the row keys remain indeed unchanged in the joined set and they continue to ensure uniqueness of the rows in that set.
Given the behaviour of the deprecated Joiner node, why does the new Joiner node still force the concatenation of row identifiers ? Could this be due to a bug ?
Kind regards,
Georges