The new Joiner seems to concatenate the RowIDs from the two tables, like Row12_Row12. When I want to join the results of the first Joiner to another table with the same RowIDs, it does not work because the joiner output chanced the syntax on the RowIDs.
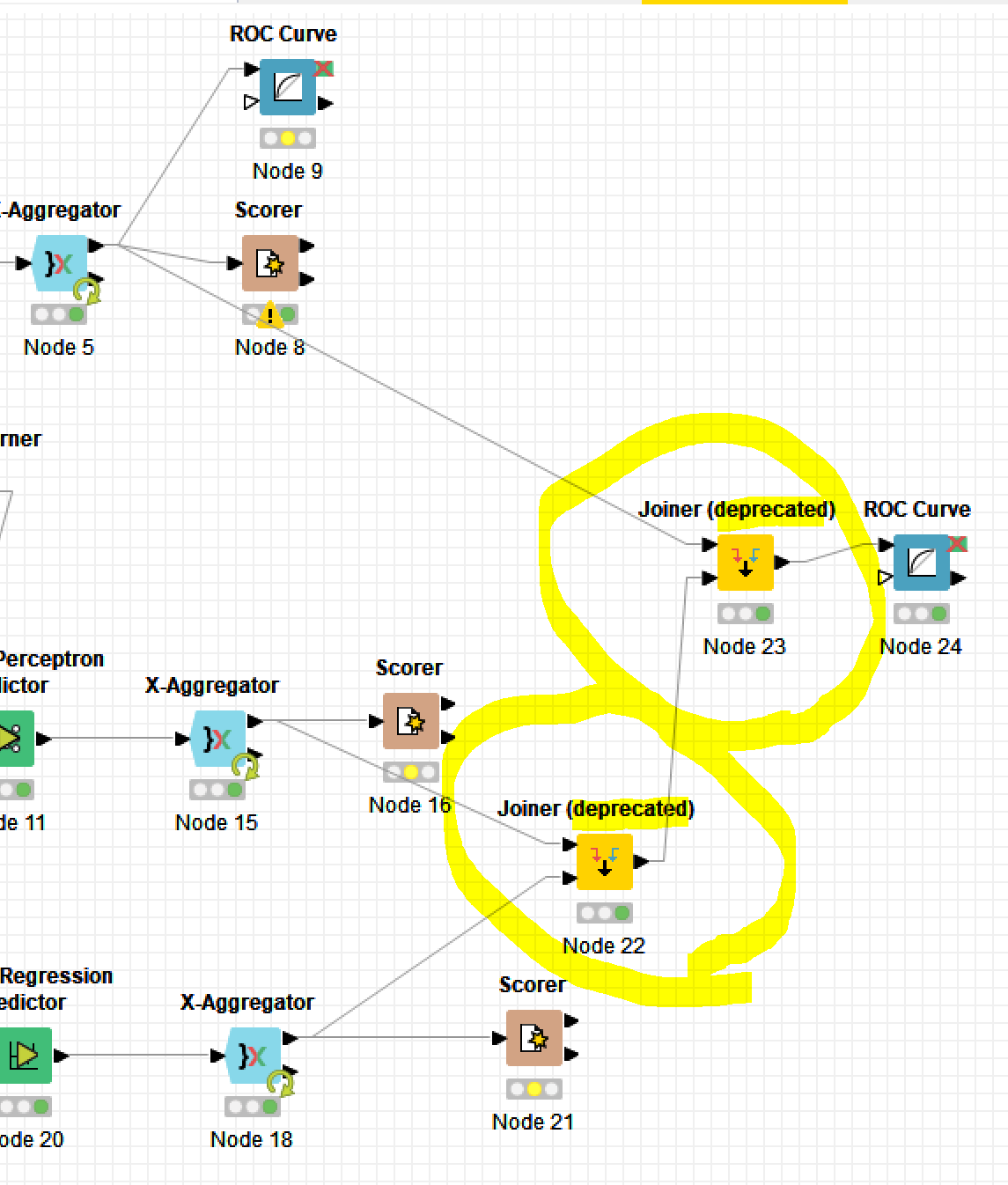
Example: If I am joining the result tables from three prediction models (MLP, DT, LR) using two Joiners, I used to be able to do this with the old joiner, but not, I can’t.
Any practical fix for this? Any insight?
I tried using the RowID node to extract and use the newly created column for joining, but then the column becomes an issue to deal with for each prediction model type. I wish they would place a CheckBox to optionally avoid the RowID concatenation.
Hi @dursundelen , as I said in other posts, I try to avoid using the RowID as you don’t have control on it.
So, I don’t even look at that column, nor do I store my values in that column.
If somehow you ended up storing your values there, you can extract them via the RowID node. I did read that you tried that, but you said that the column became an issue? Can you show us what you did and how it’s an issue?
I agree, using RowID is not ideal in most cases, especially is you have a natural primary key field in the dataset. However, for a dataset that does not have a natural primary key, to join the output tables of several predictive models (the test data with results column included) for a combined ROC curve, I usually use RowID with Joiner nodes. It seems to be the most intuitive way to handle it.
Again, I wish we had the option to omit the concatenation of the RowIDs, just he way it was in the previous version. That would have solved this issue.
Hi @dursundelen , I’m not sure how this option (omit the concatenation of the RowIDs) would work.
The 2 tables that you are joining each have their own respective RowID, so both can have RowIDs Row0, Row1, Row2, etc…, and when joining, you are taking the records with their own respective RowIDs from their respective tables. If you want to omit the concatenation, which RowIDs would you omit and which ones not? Should it be only the RowIDs from the 1st table?
The way the current RowIDs work after the join is that it shows you which RowID from table1 matched with which RowID from table2.
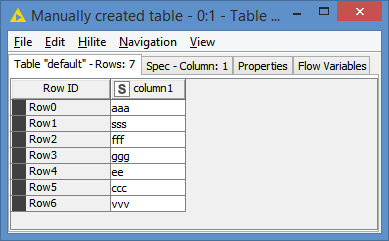
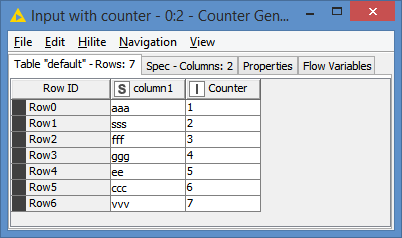
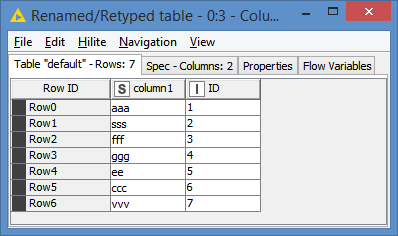
For dataset that does not have a natural primary key, you can just add an auto increment column to your data set. You can use the Counter Generation node for that - and that’s how I avoid using knime’s embedded RowID column. Something like this:
I hear what you are saying. Thank you for your suggestion, I think it would would. I also tried teh following method: I extracted the RowIDs using RowID node, right before the Joiner node, and then joined on this new field (I called, ID) in both tables, and that worked fine. The only thing here is that I have to do some additional work before I can join three or more result tables for a combined ROC curve. I wonder if anyone had done this with a more efficient way?
In this example, I used to use the old Joiner node with RowID as the join field, and worked fine. Now, with the new and improved Joiner, I need to do some extra work for this to work properly.
No, it does not. It concatenate the RowID into the resultant/joined table. If I were to join another table to the mix with the original RowIDs, I can’t, because the joined table changes the content of teh RowID.
indeed the old Joiner did not perform concatenation of RowIDs when joining upon RowID values. Let me check on that one a bit more and come back to you.
Assign unique ID (as suggested by @bruno29a using Counter Generation node) at the beginning of the process (before shuffling) and if I got it right that should do it later on as you already got your joining column.
Matching on RowID used to have the advantage over individual columns that you could quickly identify situations in which the rows would no longer match properly (missing row IDs), because only in those cases RowID concatenation would kick in.
The generalised RowID concatenation after joining in KNIME 4.4. is therefore surprising. Regarding the workaround: having to extract RowID prior to Joiner only to put it back thereafter is burdensome and defeats the purpose of RowID.
Beyond matching, RowID provides the advantage of explicit documentation of the row identifier.
It also allows to test for unwanted duplicates or to analyse them afterwards - a less obscure approach than duplicate filtering. In addition, the identifier generated by RowID provides type safety, does it not ? In any case, type stability is difficult to maintain with individual columns (in particular when they are numbers and not strings), unless you can avoid any nodes which perform any type guessing.