Hello,
I have a legacy dat fixed length file that has data field of various length(s) at position based on the fixed length label at the start of the line.
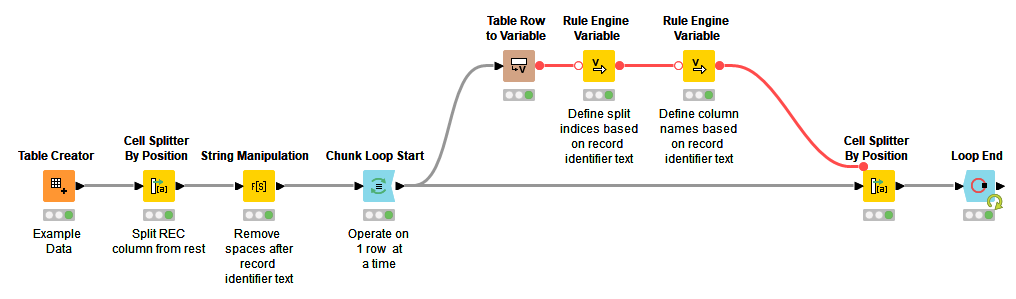
I have split the data into two columns in “Header” and “Data” column. I have filter the Header data and apply “Cell Splitter By Position” node to process the data. This works great but I have to process each set of records separately. I am trying to find a way to dynamically pass the “Cell Splitter By Position” split indices and column name with variable based on Header label but it is not working and I have tried various ways.
Just curious if anybody in the forum has similar situation and has a better solution for these type of files.
It would be helpful if you provided some example data, as well as your desired output. If you shared with us some of what you’ve tried, or even a workflow, this could save us a lot of time as well.
That document doesn’t really help. It just repeats what you said in your original post.
I am trying to find a way to dynamically pass the “Cell Splitter By Position” split indices and column name with variable based on Header label but it is not working and I have tried various ways.
It would be best if you provided a data file that exemplified your specific context. It’d also be helpful if you told us what you tried. What is the logic behind the variable creation? How are are the header labels and split indices and column names related? Give us something to work with.
Thanks for looking into it. I appreciate that. I don’t have a working solution but the idea was to start a loop on set of header values that is passed through a variable and based on that value of variable split indices and column labels would be determined.
Now, is it a best way to parse a fixed length file where you have a varying length of different records but could be identified from starting position of the text or there could be better way of doing that. I am new to Knime and thought maybe someone else has exposure to processing of old “DAT” files.
Example data:
REC1 123 ABC XYX
REC2 ABC 1213 ZZYY
REC3 A abcd zzzdD
I know what sort of data is at what position based on the starting text like REC1, REC2, REC3, etc.
Thanks for the solution. It works but the problem is that I have over 3 million lines to process and I try to execute the workflow but it was running for more than 3 hours and it was still running (the loop) and I have to stop the workflow.