I’m trying to create a Random Forest classifier that classifies records with 9 categorical features into 8 classifications. However, in the case that the classifier encounters a combination of the 9 features not contained in the training set, or in the case that the classifier cannot correctly classify a record or records, instead of misclassifying the record, I need the classifier to classify those records as “other” or “unknown”.
I’m currently using the builtin Random Forest Learner and Predictor nodes.
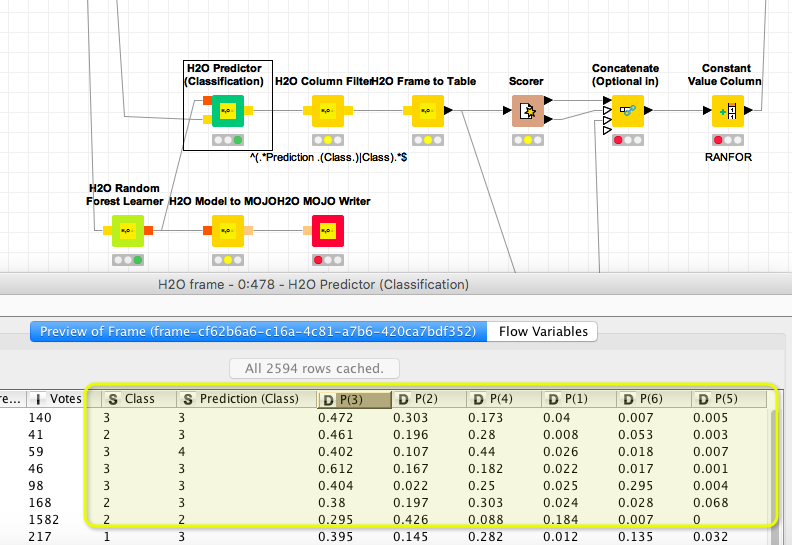
A thought I had initially was to create artificial data for the training set to create this “other” bucket, or to use the confidence rating to make the classification.
How would I go about this?
Maybe you could have a look at this example and test what it would do with your data. You might write your own rule about the Prediction based on the P(x) values. And also see how the Random Forest handles your missing values. You might skip the Python thing in the evaluation.
I am always a little bit reluctant with multiple target classifications.
Given you question I have a feeling you lack the understanding what machine learning is and what a Random Forest does.
[quote=“rsel99, post:1, topic:11480, full:true”]or in the case that the classifier cannot correctly classify a record or records, instead of misclassifying the record, I need the classifier to classify those records as “other” or “unknown”.
[/quote]
How to you imagine the classifier would know what the right class is? The whole point of creating it, is that it is unknown and you are making a prediction for which you should know the error rates / performance measures important for your specific application. eg. this is simply not possible and hints that you have some serious misunderstanding going on. (or I completely missed the point).
what you try to do sounds a little bit like Event or Anomaly detection?
If yes, using a Random Forest for it might fail, because the random forest is too good in always finding an answer.
A single decision tree however quite often does not know what to do.
So one idea I had would be too learn one decision tree per class doing a binary classification into True = Thisclass and Negative = any of the others 8.
And if all of them say it is not the true class, it should be unknown. Might be worth a try.