I was trying to create a model for solving the problem “What Causes Heart disease” from the Kaggle community. Using KNIME’s Random forest classification nodes, I got the sensitivity of 79.31 which is actually not bad. But, when I implemented the RF Classifier in Python on the same dataset, The sensitivity shot up to 90.3 (inspired by this solution)
Both of the models are built on the same datasets and I am not sure why SkLearn classifier is giving better results. Moreover, Variable importance is also coming out to be different in both of the models.
I think there are a some reasons why it’s not straight forward to compare the results from KNIME with SKLearn.
I ran your Python code several times and the sensitivity is always between the .8 and .9 . So it’s not always .9
Your KNIME flow always delivers the same confusion matrix as an output. And that is because in the Partioning node, you use a random seed. So every time you run the flow, you get the same result. If you don’t use a random seed, you will see different outcomes and therefore some times a higher sensitivity than .79.
Another reason maybe that the parameters of the RF in SKLearn do not match those in KNIME
Thanks for looking into it. For the sake of discussion, let me provide my perspective on your points.
I forgot to add this line into the start of the code that I shared “np.random.seed(123)” . Please add this line and run the python code again - you will see that results will not change and sensitivity will be 0.90~ . However, this opens up a new question - What is so special about the value of Random seed as ‘123’ - If you will replace this value with any other value - Sensitivity of the model will further go down and hover between 0.8 to 0.9. What could be the reason and how do we know that it is the ‘best’ random seed to be used ?
I have fixed my Partitioning in the KNIME with Random Seed value as 10 and hence my results are not changing. If you look at the ‘Python’ code, I have also used the same Random seed value while splitting the data in function “train_test_split”. So, In an ideal world, Both platform should provide the same partiioning and same set of test and train datasets.
I am in complete agreement with you that Parameters of the RF In SKLearn ‘might’ not match with those in KNIME. However, if you look closely at the ‘default’ Parameters value of the RF classifer - those are as follow.
Few of these parameters exist in the KNIME for tweaking and few of them don’t - so we don’t know what values KNIME would be using in its RF algo. However, I have tried to match wherever in both of the places in a hope that I get similar results…But couldn’t
Don’t you think if data is same; Random seeds are same; models are same; results should be same irrespective of the technology used?
It leads to a question that how can I trust my KNIME results when I can see that I am getting a better prediction model in Python? Or, what else I could do in my KNIME classifier that makes my model better or equal to my Python result?
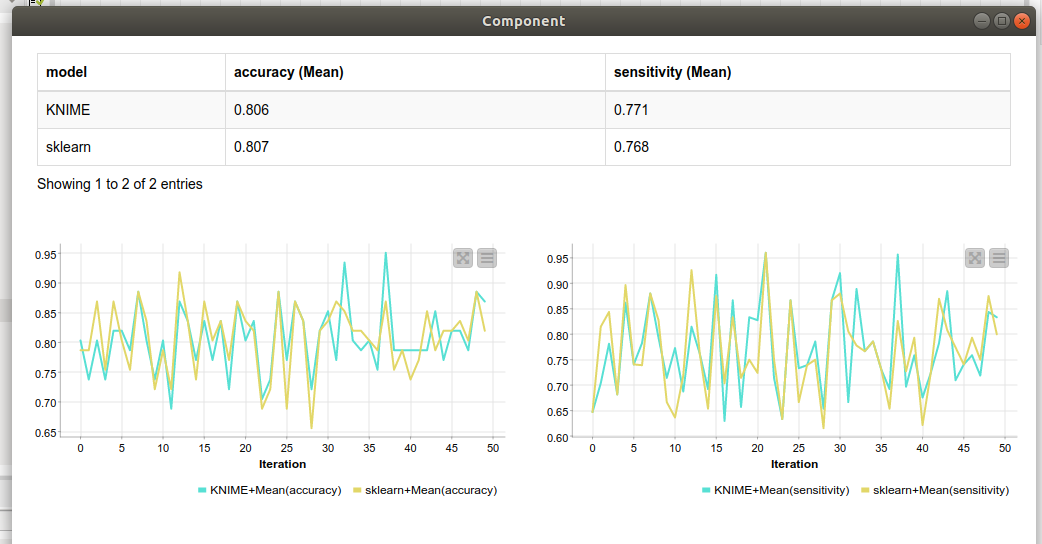
In this wf your RF model runs both in KNIME nodes and in a python code (code and wf from the post above). I executed the models on the same samples. So in the Python node there is no partitioning anymore. Further more I did not modify any model-parameter. For the KNIME en SKlearn model I compared the accuracy and sensitivities. And as you can see, after 50 runs of the flow, there is on average no big difference between the performance of the KNIME and SKlearn RF model.
I think partitioning the data of a relatively small data set has a significant effect on the model-performance. And also a set_seed of 10 in KNIME leads not to the same results as a set_seed of 10 in SKlearn.