Hello,
I’m relatively a newbie in KNIME and ML, however, I have successfully built several workflows now, and understand the basics.
My problem might be a bit more advanced for my level, however, based on what amazing stuff you can do with KNIME, I thought this should be possible.
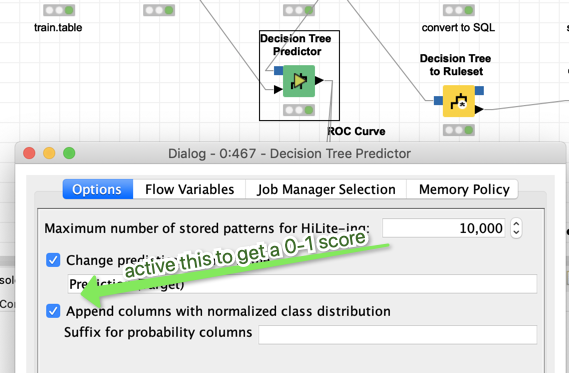
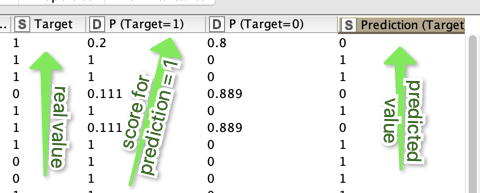
My workflow uses random forest to predict which employees will leave the company. It works as it should with a solid level of accuracy, but it would be even better to include the percentage of how likely an employee will resign. I only have the prediction and the confidence for now and I didn’t find any post or workflow which does this.
Also, I was able to extract the importance of each feature, but somehow still missing why each line has that prediction, so why it’s 1 and why 0.
I would really appreciate if you could help me with this.
Best,
Andras
“prediction” is a relative business. The model basically gives you a rank and out of convenience the group with more % gets the ‘prediction’ especially if your targets are highy imbalanced this might not be a good approach.
You might have to decide yourself where the threshold is. There are measures and statistics that can help you. You can calculate Cohen’s Kappa and F1 score for various score groups and decide which gives the best balance of predictions.
This also depends on your business case. What happens if your model is wrong. Some misplaced marketing calls or someone getting hurt because of the wrong treatment.
Also you might balance your target with SMOTE algorithm.
Also this article might give you further insights.