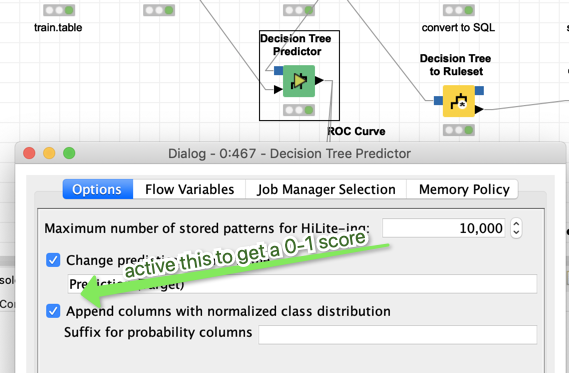
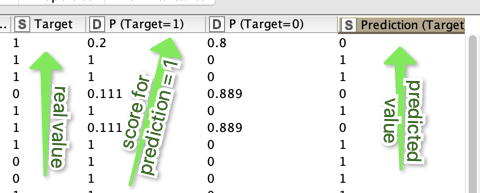
You can get a 0-1 score typically by activating an additional setting in most predictor nodes.
If you are interested in interpreting model performances beyond the true/false prediction you can find an example here: