First of all, this is a great community!
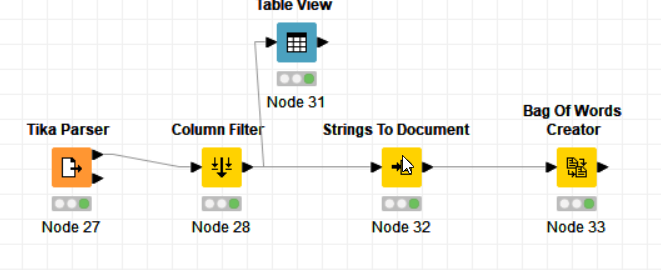
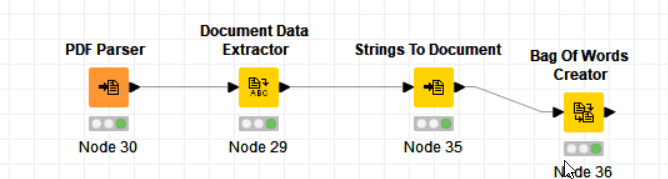
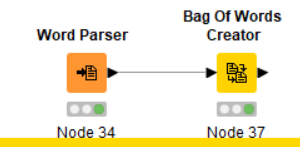
I am looking for help to read a .pdf document (such as Annual reports). I tried Pdf parser and Tika parser and then did a ‘Bag of Words Creator’ to get the total list of words (using which I am required do some further analysis) . But both instances gave different number of total words, which is different from the actual figure. I tried converting the pdf to Word and then used the Word parser. That gave me another different number. I am not so well versed with all this, am I missing something here? Please
help.
If your PDF documents are not confidential, could you please upload here your workflow (does not need to be run) and your documents inside the workflow ? Usually, the best place to store the data is inside the workflow in a directory located at its first level called “data”.
Thank you @aworker and @mlauber71 . I will do that. It will take me a bit of time to comprehend this.
Meanwhile, I think I may have understood something wrongly and am working on it. But thank you again so much! I am afraid I will most probably need further help as I proceed with the data and will need to reach out again.
The PDF Parser and the Tika Parser both use the same library so I would expect the same output as well here. Are you using different tokenizers in the String to Document node? Additionally, you do not need to use the Document Data Extractor and then use the String to Document node again for the output of the PDF Parser as it already converts the data to the Document data type.
To see what is going wrong and which words are different, you can use a Term to String node to turn the Terms into a String column. Afterward, do a full outer join with a Joiner node. This will help to see which words exist in each Bag Of Words and which are missing.
Thank you @julian.bunzel . Sorry for the delay in replying.
I have avoided Document Data Extractor now. I think I understand a bit better now and my workflow seems to be giving much better results overall. Thank you.
I did a full outer join with the terms from the 2 parsers. There are some words which are extra/ missing in both cases but not too many. I am reading an annual report and these ‘extra’ words are some numbers in both cases and a few terms which (are a combination of number and alphabets and) do not make much sense.