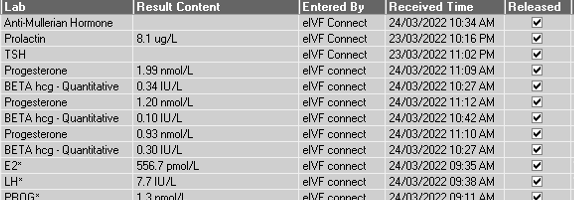
I have a screenshot in PNG format with a clean set of columns and rows of data. A sample row of data would look like:
Schedule Date Facility PatientID Received Time Released Time
24/03/2022 NYC 3423423 24/03/2022 11:12AM 24/03/2022 11:30AM
My current workflow uses the following nodes:
Image Reader
Splitter
Column Filter
Tess4J
Image Viewer
I’d like to be able to get the table that’s in PNG form into an actual, editable table that I can begin to cleanse further. I haven’t done anything with the configuration of the nodes.
I’m still new so trying to work through this. The errors currently are:
WARN Image Reader 3:8 Encountered exception while reading image: 88b81fe263a2334d6e62d850f7f9f0b8e97a9574.png! view log for more info.
WARN Image Reader 3:8 Encountered errors during execution!
WARN Splitter 3:9 Missing cell in row 88b81fe263a2334d6e62d850f7f9f0b8e97a9574.png. Row skipped!
WARN Splitter 3:9 Rows with missing cells have been removed!
WARN Tess4J 3:4 Invalid column selection. All columns are selected!
Thank you so much for reaching out! Is it possible for you to attach the screenshot in PNG format to this post? I’d like to see if I can replicate the errors and work through them on my machine.
Hey Dash - thanks for jumping in. Here’s a portion of the screenshot. I’m unable to share the whole thing due to the sensitivity of the data. However, please imagine the following preceding and succeeding columns:
I’ll be taking over for Dash on helping with this task. Would you be able to also share your workflow so I can see why these errors are being generated (it could be a settings issue)? I will use your png as input.
Also, can I ask why you have images but not csv, etc. files? OCRing tables can quite tricky, so I will assist you with this to the best of my ability.
Hey Victor, a bit embarrassed to say that my workflow only consists of the Read Images → Tess4J node. Not sure what else I needed.
The table is an image as it sits on a very old EMR system with almost non-existent querying & export functionality. Fortunately this will just be a one-time analysis, but would be interesting to learn how OCR might work on a scan of a table.
Even if the data is read in, can it be OCR’ed correctly to transform it into a table?
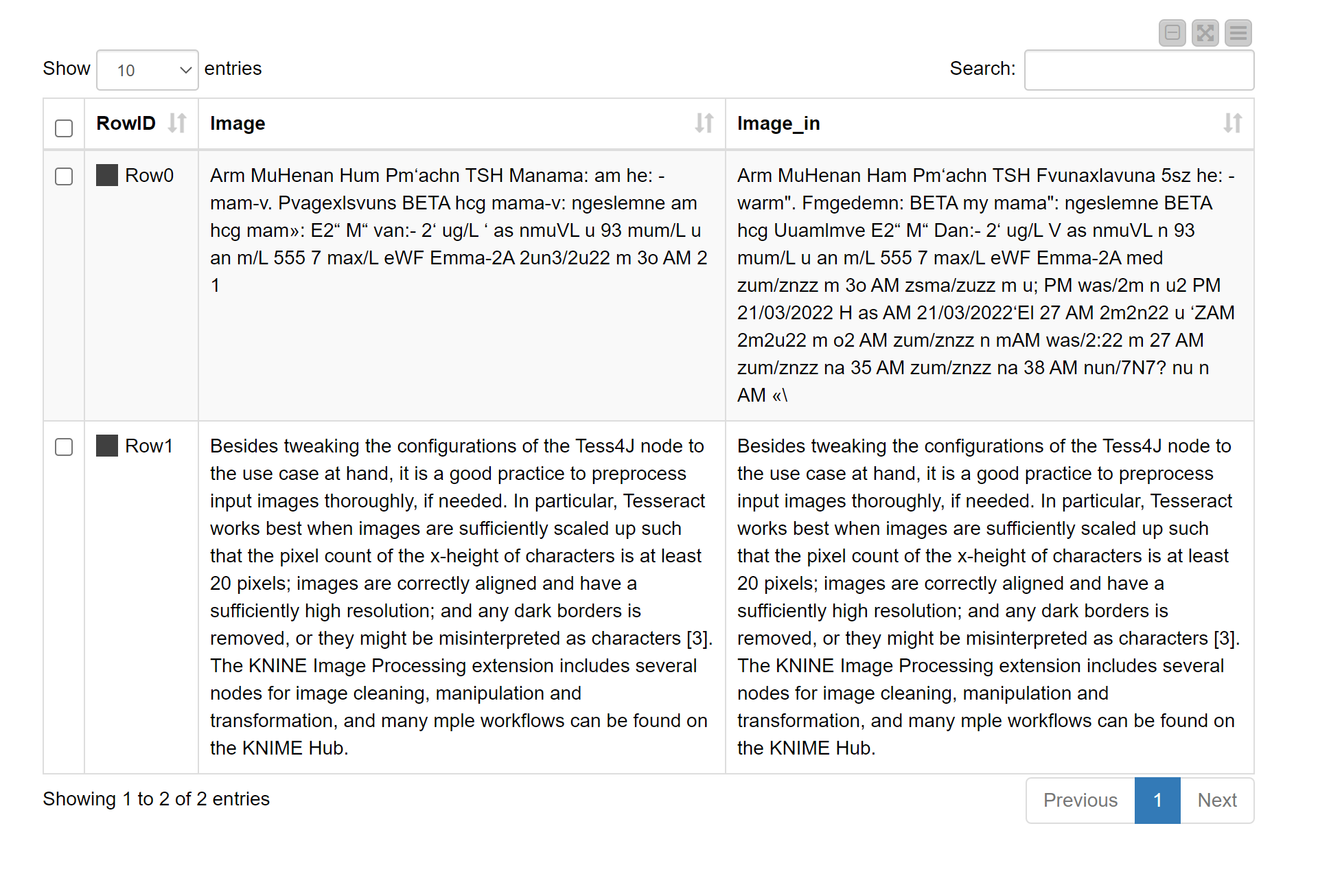
The short answer to 1) is yes, we can read the png. But 2) seems to be no, we cannot OCR this data to get a reasonable output with KNIME.
The long answers:
–1–
For the image reader throwing errors, I also had the Image Reader behave unexpectedly (sometimes throwing errors, sometimes not). Instead Iet’s use the Image Reader (Table) node. You can see a sample workflow (you may be able to remove the path to string and tika parser node - I was experimenting).
Notice that the PNG I supplied worked well but your PNG was not able to be OCR’ed. I suspect there are several issues with that PNG:
Low Resolution
Not enough contrast (although I tried to fix that with the Image Normalizer node with little success)
KNIME’s OCR engine is not powerful enough to deal with this type of image
The table format here is too difficult to parse correctly
I noticed you said there is almost non-existent querying & export functionality - so is there any export format you could get the data in? We might be able to reproduce a table if we can get the raw data in some other format for instance. As well, you can make changes to the data before you take a picture which may improve the OCR step. For instance, make sure there are only two colors present - black and white - which will give you the highest level of contrast.
To end, I would say you can go the OCR route and try out all of the options KNIME has and see if one helps but there are myriad reasons this task will only deliver suboptimal results. I personally would output in any format and data wrangle into a table. If copy/paste is also possible (on some EMR systems this is possible) then that may also be an alternative. I’ve worked with medical data before as well and understand the headaches and creativity that such data brings.
Hope that helps. And feel free to ask more questions if anything isn’t clear.
Thanks Victor. Looks like I’m going to have a business meeting with the EMR provider about this as their system is quite walled off.
Much appreciated on the workflow - I will treat this as the solution for now and try different snapshots of the table while also pushing the provider on enabling some form of querying or exports.
Side note - I’ve had some success before OCR’ing a vendor quote. I have to dig out the workflow, but it was a PDF so I presume the resolution must have been much better.
Yes, I’ve also worked with medical PDFs and the OCR process was quite good. Tables (I assume because of the coloring and lines) are almost always an OCR nightmare.