Hi there!
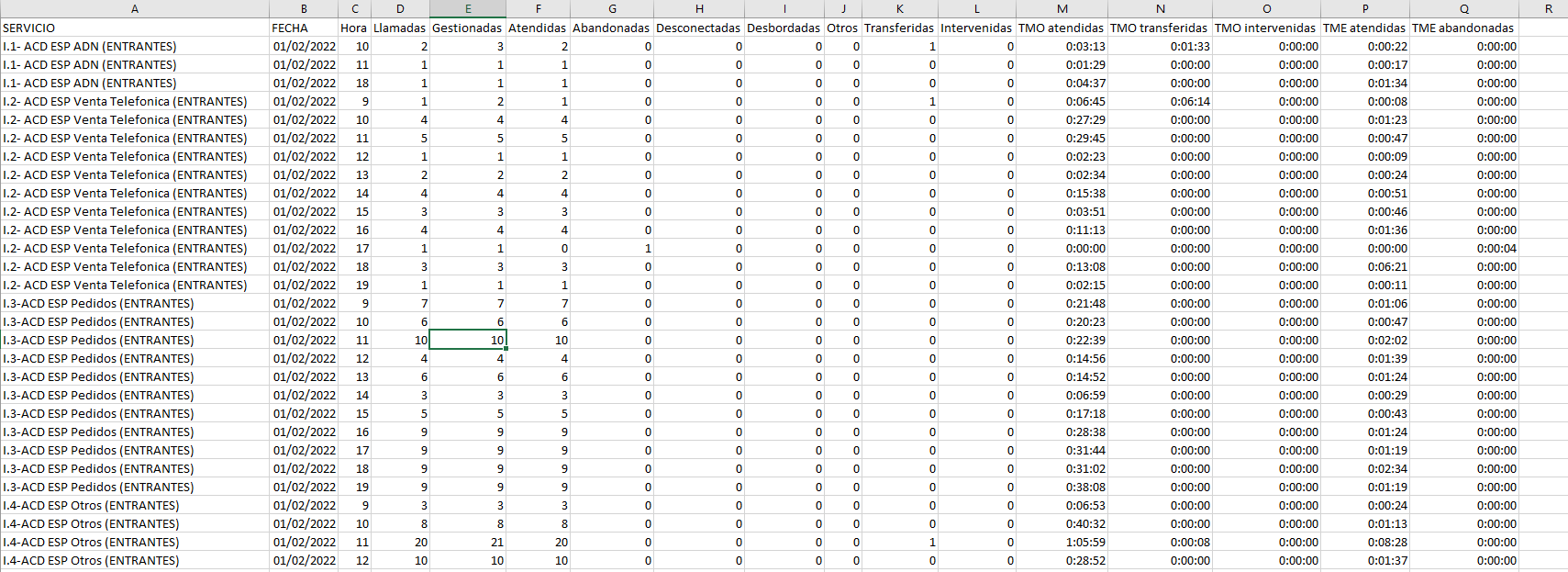
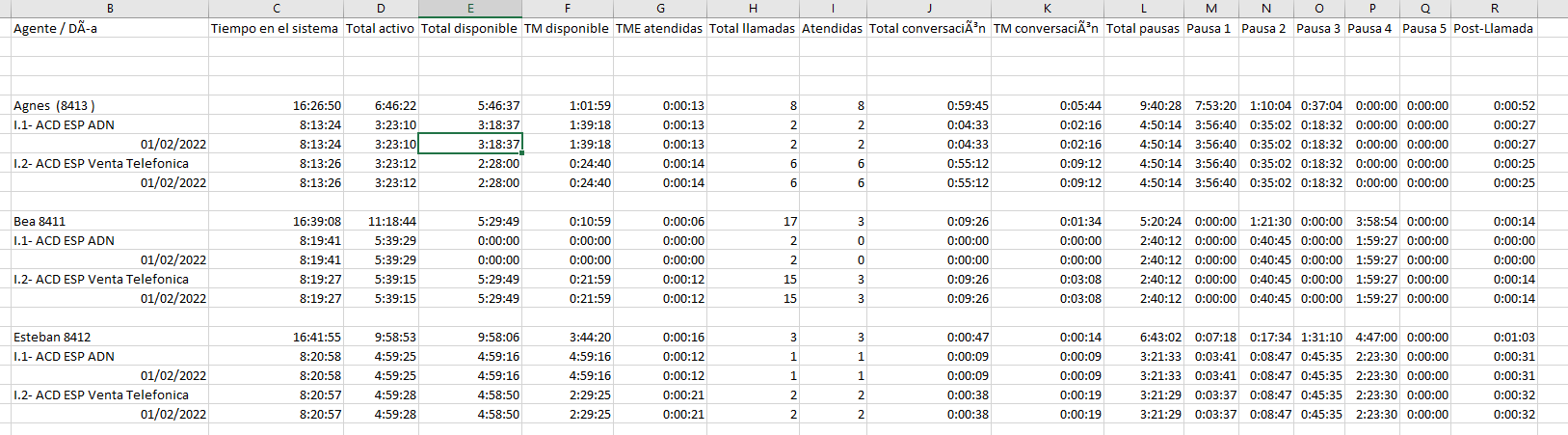
I have a bit of a problem with several csvs. I need to rearrange them. I attach two.csv for comparison and the .xlsx that I wish to achieve. The problem is that I need to rearrange lots of them, theoretically with the same structure and logic.
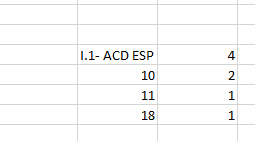
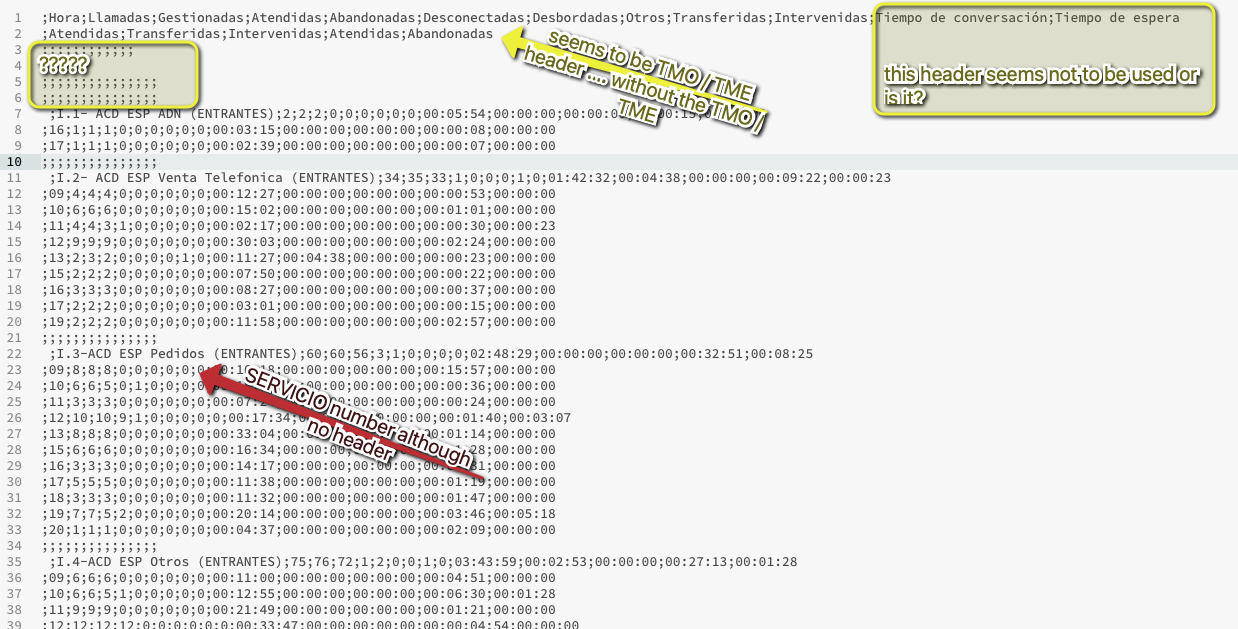
So, for example, the csv I attach (converted to .doc) has three rows in the first Service
but it is possible that instead, it has 2, for example.
Hi @jorgemartcaam , if your problem is only about having to rearrange lots of them, I assume that you do not have a problem rearranging 1 csv. In that case, you can use a loop to do all of them, especially that that they are “theoretically with the same structure” (not sure about the role of the “logic”).
You could use the List Files/Folders node to list your files, and then loop through them one by one, and within the loop you can implement your rearrangement and save rearranged data to where you need them to be.
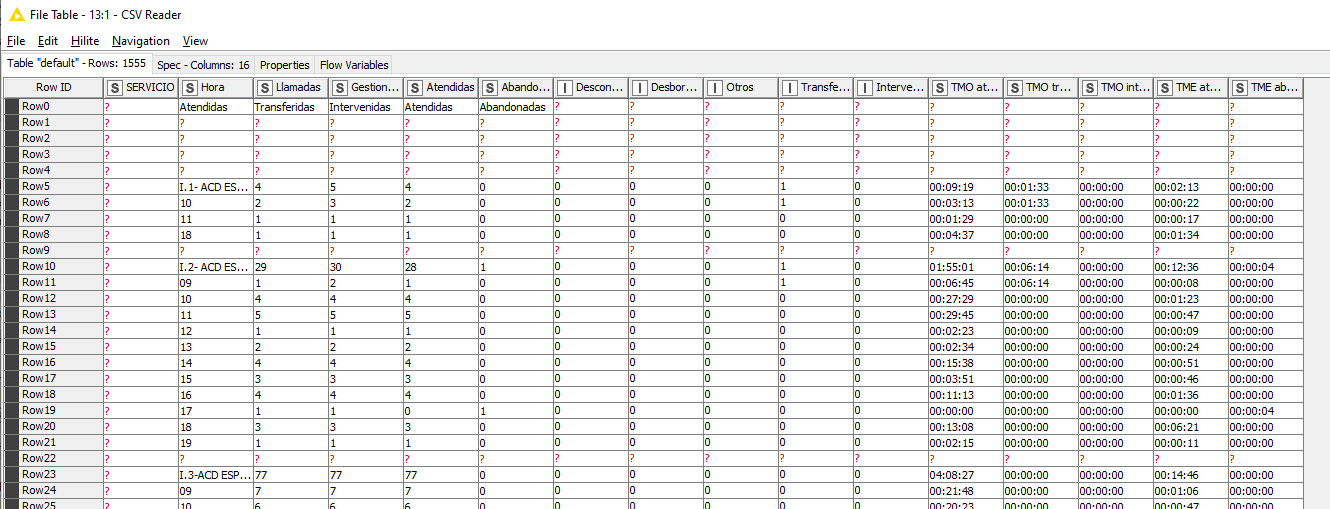
Sorry I did not explain myself. The problem is the rearrangement in itself. I don’t know how to convert the .csv, which does not have a data table structure, into a proper data table.
The csv looks like this:
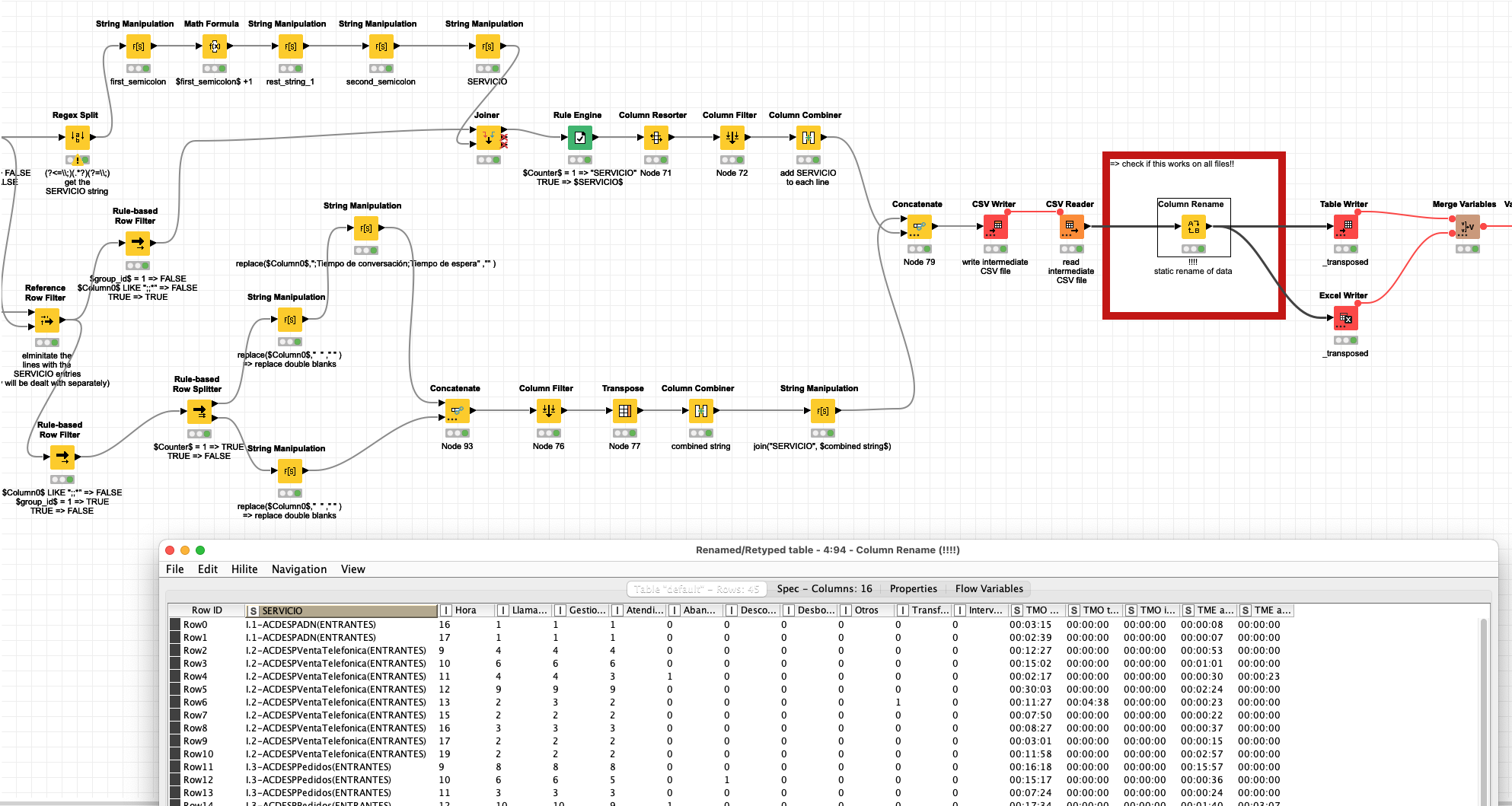
@jorgemartcaam you might need a more complex import structure like this:
What you could do is explain what characteristics and restrictions your data will have and if your example will represent the whole challenge. Especially how anew block of data would be identified.
it seems one entry can strech over several lines. Will there always be the same number of lines or might this vary?
@jorgemartcaam OK … I put something together that would try to get your results but I have to warn you: it ain’t pretty and the CSV (?) format is as strange as it can be.
I had to make a lot of assumptions and clear data based on your result and I must admit: seldom have I seen a stranger ‘format’. If at all you might consider going back to the source and asking for a better format.
The idea is to put together the strings with the semicolon separators in one line. Export that as a CSV in one step and then import it back with the “;” as column separators. It does work for your two sample files. Question is will they all be like that or can the format change.
In the folder /data/ there is a sub-folder /result/ where there are the transposed files as Excel and KNIME .table:
Hi @mlauber71!
Sorry I could not reply. I have a lot of work lately and I still could not give time to this task. The moment I can I will answer you in detail about your questions and letting you know if your “best guess approach” works.
Thank you for the effort!
Best regards.
PSD.: Yep. I think they are reconsidering the CRM already
Hi @mlauber71,
Just amazing. I implemented your “best guess” and took a look to a couple of files. I could not find any difference between the original and your approach.
About your doubts:
1: About the headers. What we have here is what in Excel would be something like a grouped cell. That is why it looks like the headers are not used in the csv. Plus, I changed the header names in the “ACD” file.
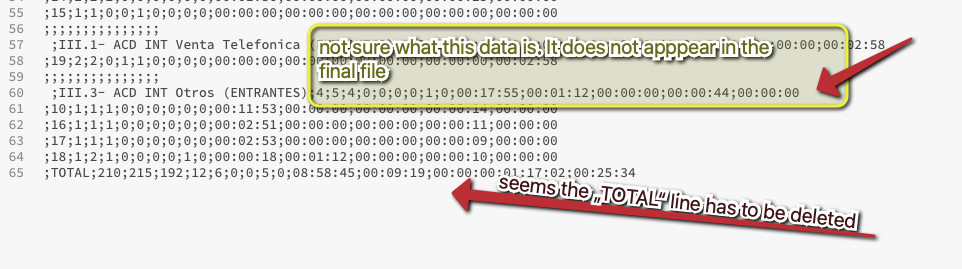
2: About the “Total” line, you were right. It is useless for me.
3: Yep, the results are always like this.
4: The number of lines per entry might be different.
5: Each block of data comes with the “service”. I.e, I.1- ACD ESP ADN (ENTRANTES), etc.
It works really well. I will take a deeper look to see if I can find any problem but I think it is perfect.
Let me tell you, I have another file with even a weirder format. The headers are nicer but it is equally strange. If you want to practice more just let me know and I will upload one file for you