@gonhaddock
update. so i got your workflow to work the latest one… exactly how you uploaded it but when i used multiple files with different names it did not capture the last name that was one line under the first name. So for example in the dummy file v1
the first name is presented exactly like
Patient: SALIMAH M
MUHAMMAD.
YOUR WORKFLOW CAPTURED THAT, BUT when i added more files to the workflow with the exact same format just different names like for example
Patient: JOHN R
SMITH
THE WORKFLOW ONLY CAPTURED “JOHN R” AND NOT THE FULL “JOHN R SMITH”
Hello @NabilEnn
That’s good news that you can use the workflow.
I’ve revisited the workflow. And disclosed the Dummy Filev1.pdf’s regex code out from the Column Expressions node, into a String Manipulation one. I added a CASE Switch nodes set too, aiming to configure the desired port:

I also did some regex code revision (the code is almost new) making it more robust, and easier to use; so this workflow may fit to work with your pdf dataset.
The workflow has been updated in KNIME Hub
BR
1 Like
@gonhaddock is there anyway your workflow can include the page numbers of the pdf
basically output the page numbers of what data was extracted from
Hello @NabilEnn
About the page# numbers ![]() … “Let’s go in parts! as Jack the Ripper said.”
… “Let’s go in parts! as Jack the Ripper said.”
-
You aren’t currently giving too much feedback. Like if the workflow’s latest update is currently working for you, or if it’s somehow satisfying your expected output.
-
Matching the page with regex needs some context together with the name/patient extract. Then, if its related to this particular pdf sample; you shouldn’t split your solution in more than one topic. Because you will have to integrate the solution at some point.
-
Working with regex requires a representative sample and use context. The current ‘Dummy Filev1.pdf’ is a one page pdf, then it will be hard to test multi-pages.
Furthermore, the solution has different non functional requirements depending on page distribution: one pdf per page, or multipage pdf…
I think that I can deliver any of these outputs, even with this non representative sample. I have previous developments deployed with similar requirements… so I can figure out how it will perform on different functional requirements. But my dedicated time is limited too; so working without a clear target is not good for both of us either.
Please comment.
BR
4 Likes
okay i completely understand. so from what i see the workflow you last updated is basically removing all line breaks and blank lines in the file and making the whole text or content of the file one line of text so its easy to extract text if its one line above or under the keyword. so far it has been working good. now i will create a multipage dummy file and see if you can use that along with the single page dummy file and get it to generate a page number column. honestly even if the output would just generate every page number in the output that would work too. for example one row id #1 could be a blank line and then #2row id could have text iam extracting and can both upload the blank lines and the extracted text to excel. If it makes it easier…
Im attaching a workflow here that has the dummy files in the table. If you could modify this workflow to output page numbers as well, the dummy files all have different page numbers. Please make sure the workflow is still able to work as in output page numbers if there is multiple extractions and not just “Name”
page number.knwf (33.1 KB)
@gonhaddock When you get a chance^ Thank you for all your help so far!
Hello @NabilEnn
This description was from previous version. Latest update and due to the bug you reported, I wrote the code back, aiming to work with multiline text. Right now we are removing the line breaks after the extract, for result displays.
I currently can’t see the pdf from your workflow. The PDF is not included within the workflow data area, and I need the document to work with.
Can you please post the pdf in the chat straight away?
All this is relevant in terms of work load and efficiency because:
- one pdf per page.- it is easier, just extract the ‘page event’ from the pdf and send to constant column
- multipage pdf.- requires a parallel extraction of the page trailing text (as page# is at the beginning of text),and a later a wildcard validation using patient/name.
BR
I thought i included the pdf’s in the table creator node of my workflow. @gonhaddock
New Dummyv1.pdf (13.1 KB)
New Dummy v2.pdf (11.3 KB)
Here you go @gonhaddock
Hello @NabilEnn
These new files are blank pages… there’s no page number to extract. In the capture you can see the whole content of the new dummy files.
The first file is the previous dummy, and this is a one page pdf. There was a page number to extract, highlighted in yellow.
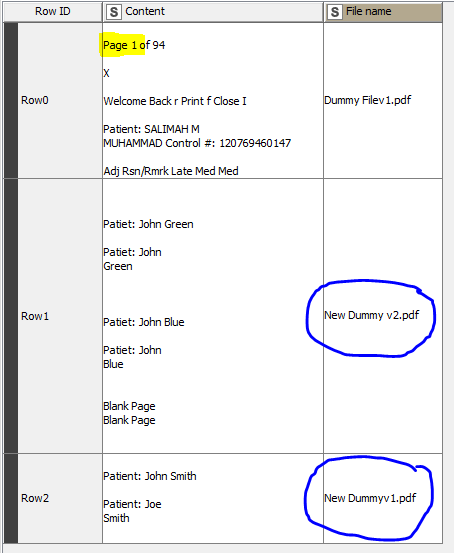
BR
Right, im trying to to have the workflow output page numbers without there being a page there… Wouldnt the row ID# basically be the page numbers of a file. If we could output row id and i can just change row id to page number in excel that would be great.
@gonhaddock
Hello @NabilEnn
I’ve added a column with the pages_extract. This is all I can offer with the sample data provided.

If there are more than one page in a single pdf; you would see the all the file pages listed in the cell. The workflow has been updated.
BR
This topic was automatically closed 90 days after the last reply. New replies are no longer allowed.