So firslty, i’m new to Knime, and i am coming form teh perspective of an Alteryx power user.
So i while on teh face of it, it appears Knime can do most of what Alteryx can do, certain really simple things are very difficult. Whether this is a nomenclature issue (node naming etc…) or simply missing features i am as yet unsure. I’m hoping that the good people in here can help point me in the right direction and help me get over my learning curve.
I am trying to do something simple.
I have a file full or urls and i need to extract a list of all the query keys found.
I am using the regex split node to extract the query keys using regex tried and tested on regex101
Now in Alteryx i simply use a regex tool set to parse, enter the string below and it automatically parses each capture group into a column.
(?[^=]+)(&[^=]+)
In knime i get a mysterious warning message: 1589 input string(s) did not match the pattern or contained more groups than expected
Can anyone decipher or point me in the right direction?
which node you are using with your regex?
could you provide an example Workflow with the regex and node configuration you are using including an url which results in this error?
The URL does not have to be real
Thanks, i’ll have a look at the book.
Checked out the other topic link too. The whole point of tools like this is that they should offer uncomplicated ways to carry out this sort of thing, to have to learn Ruby to do a simple regex to column parse seems to defeat the point.
Thanks @qqilihq for setting me on teh path to success.
Ok So here is what i learnt.
Out of the box Knime does not have the tool that can adequately carry out this processing.
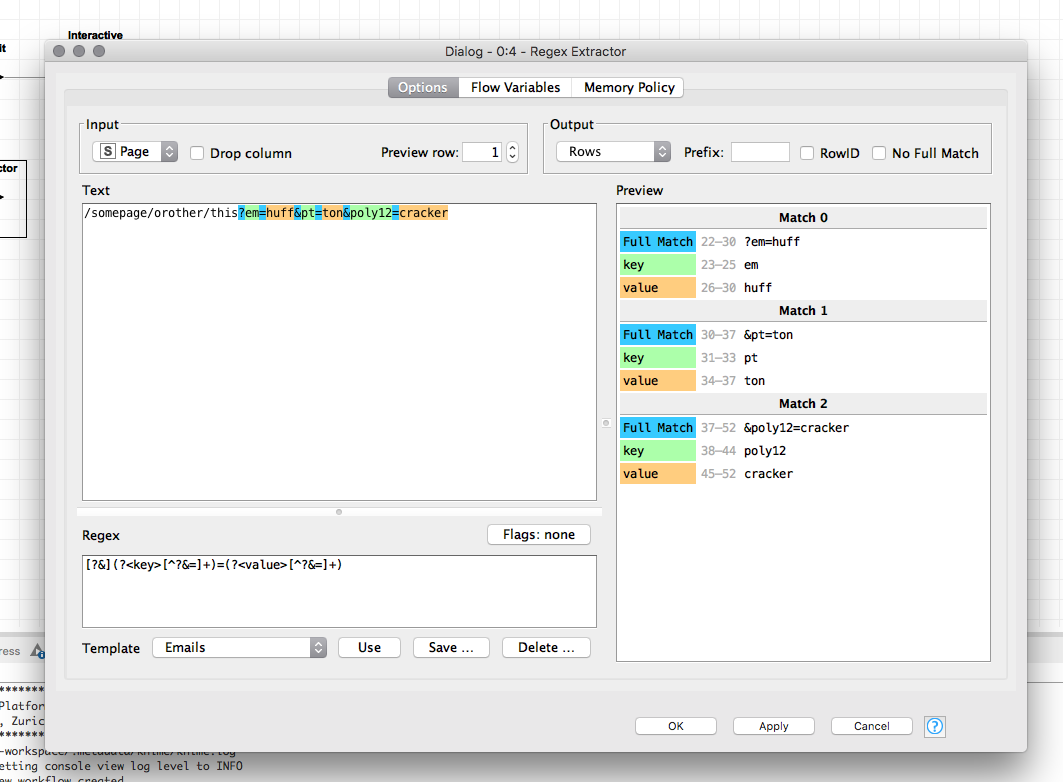
However there is an extension pack you can download which has loads of useful nodes, in particular a regular expression node that does exactly what you would expect and also has a built in preview function.
The extension is Palladian - Highly recommed you install this.
As far as I understand your problem this is what you want?
Basically I think the regex split node expects you to give a group for every parameter you expect (if a group returns more than 1 match you get your error :))
As well to successfully split your regex has to match the whole url
Attached an example how to solve this within the regex split node or with the string replacer node - combined with the cell splitter (which i prefer)
*however qqilihq solution seems to fit your needs quite well as it actually gets the matches for each group - not quite sure why KNIME does not consider the matches from groups - would make it easier if it did