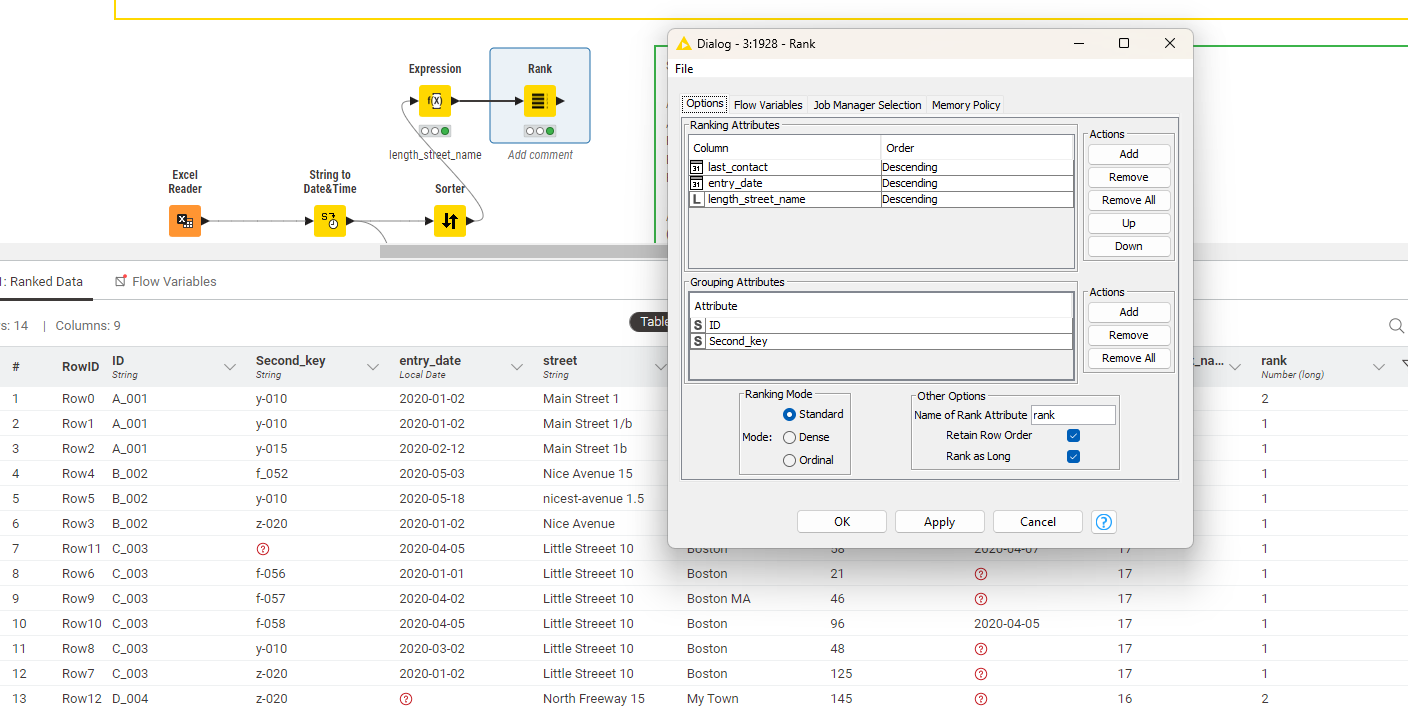
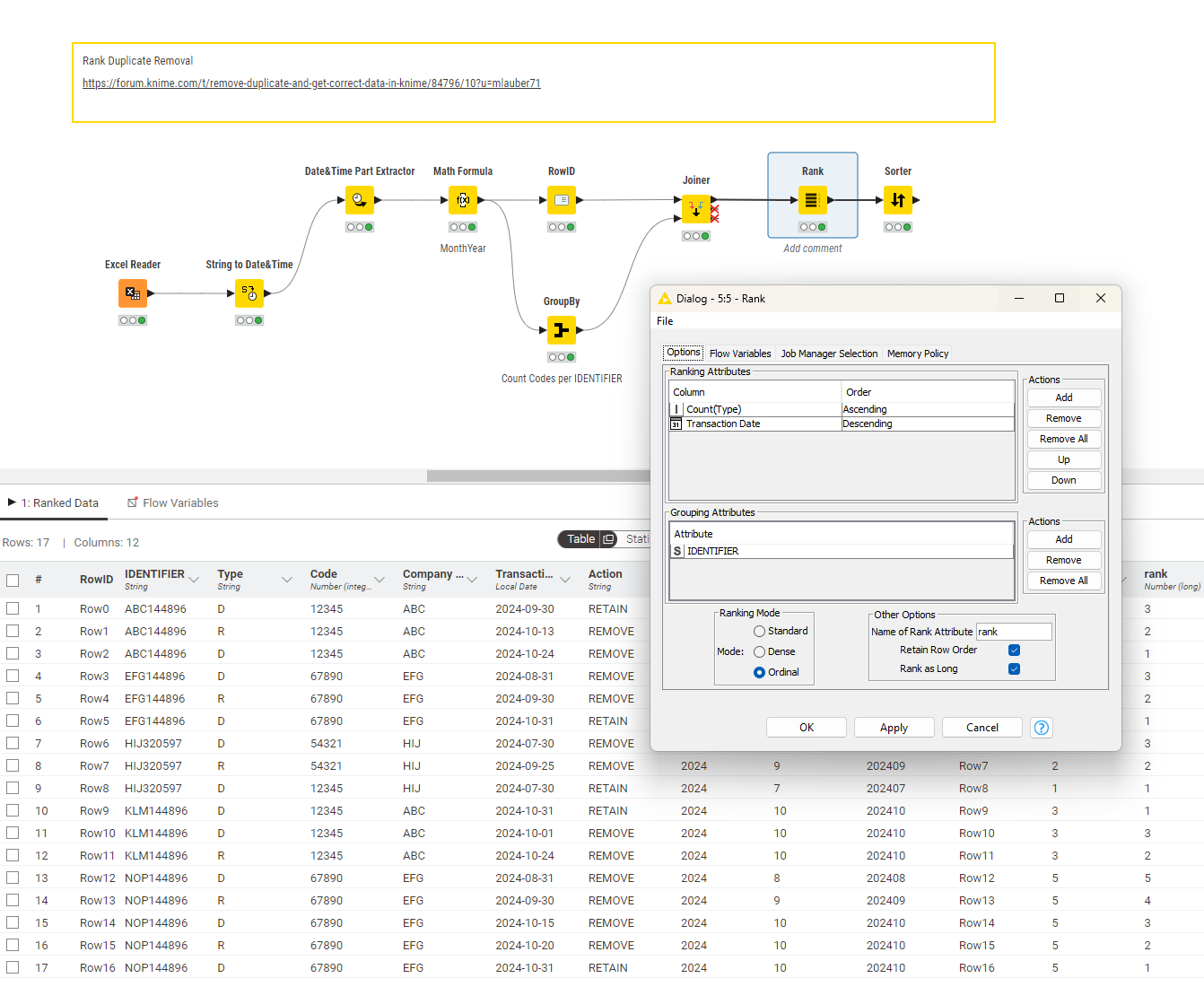
May I ask how can I get the correct line for the 3 cases below with duplicate IDENTIFIER?
In case 1, I need to retain the first line because in transaction date, the other two was posted or reversed last October and unique one is september.
In case 2, different to case 1 wherein there is no same month but the unique one should always be the latest month posted hence need to retain last line.
In case 3, the transaction date has the same month which is July however the one should be retained is the last line because it has the unique code (column code) which is 12345, both lines have 54321 code.
Hope you can help me figure out how to get this and ensure all of these 3 cases will be considered in every run of my workflow. Thank you!
Hi @trafalgarlaw, l will see if I can find some time to think about this later, but I have some questions which others may be wondering too…
In the rows in case 1, you are saying that the reversal cancels the third row because it is in the same month even though the reversal occurs before the transaction you say should be reversed?
Which row would have been kept in the case 1 example of the date of the first row had been October 1st?
Will you ever have more than 3 rows for a given identifier?
Will there every be more than one reversal for an identifier?
In the rows in case 1, you are saying that the reversal cancels the third row because it is in the same month even though the reversal occurs before the transaction you say should be reversed?
Answer - I have changed the Type to avoid confusion. See above updated data. So for Case 1, duplicate lines with the same month, should be removed and the one with different month should be retained.
Which row would have been kept in the case 1 example of the date of the first row had been October 1st?
Answer - I have added Case 4 in which if same month for all, the latest date will be retained.
Will you ever have more than 3 rows for a given identifier?
Answer - Yes, thanks for your question, I have added Case 5. But still it should get the latest date.
Will there every be more than one reversal for an identifier?
Answer - Yes there will be though I am planning to do a filtering of R after getting the results for all cases so if the retained lines contain a type R, I will remove or filter it and get only with type D.
Hope I answered all your questions. Let me know if I have missed anything. Thank you!
@trafalgarlaw you can use H2 local database and define rules which item per group will remain by sorting within this group. If you have string variables you could assign numbers that would determine the rank of the item.
@trafalgarlaw What you can do is make a Group By your IDENTIFIER and then count the number of Codes per this group and then join that back to your data and then use the number of these codes per IDENTIFIER as an additional sorting item
@trafalgarlaw BTW your examples do have some duplicates in the IDs - is that deliberate? Maybe you can clear them up and provide us with a consistent set of data?
@mlauber71 - Actually, these are the cases I can’t figure out. Hence, putting all cases here because in usual data, possible only one here will be in the report. Let me know what exact or consistent data are you referring to so I can provide as well. Thank you!
what constitutes a group where you would like to retain only one line
what is the order of rules to consider when ranking them
ABC144896 and EFG144896 are there two times. What is it that constitutes a group where you want to retain one line. In the examples you are retaining two lines. What would be the rule for that.
Rules can be complicated: ID with the least amount of unique codes in one month or so. But the rules will have to be precise.
That’s a great catch, @mlauber71. Sorry I just put the Case 4 and Case 5 with same IDs in Case 1 and Case 2. But it should never happened to have two different cases with same IDs. It will always be unique.
Hi @trafalgarlaw , I’ve been watching the thread but not had much time to devote to it. I’m trying to determine if the different cases that you have fit any simple patterns, but at the same time consider whether patterns would still hold if you had additional rows in any of the scenarios.
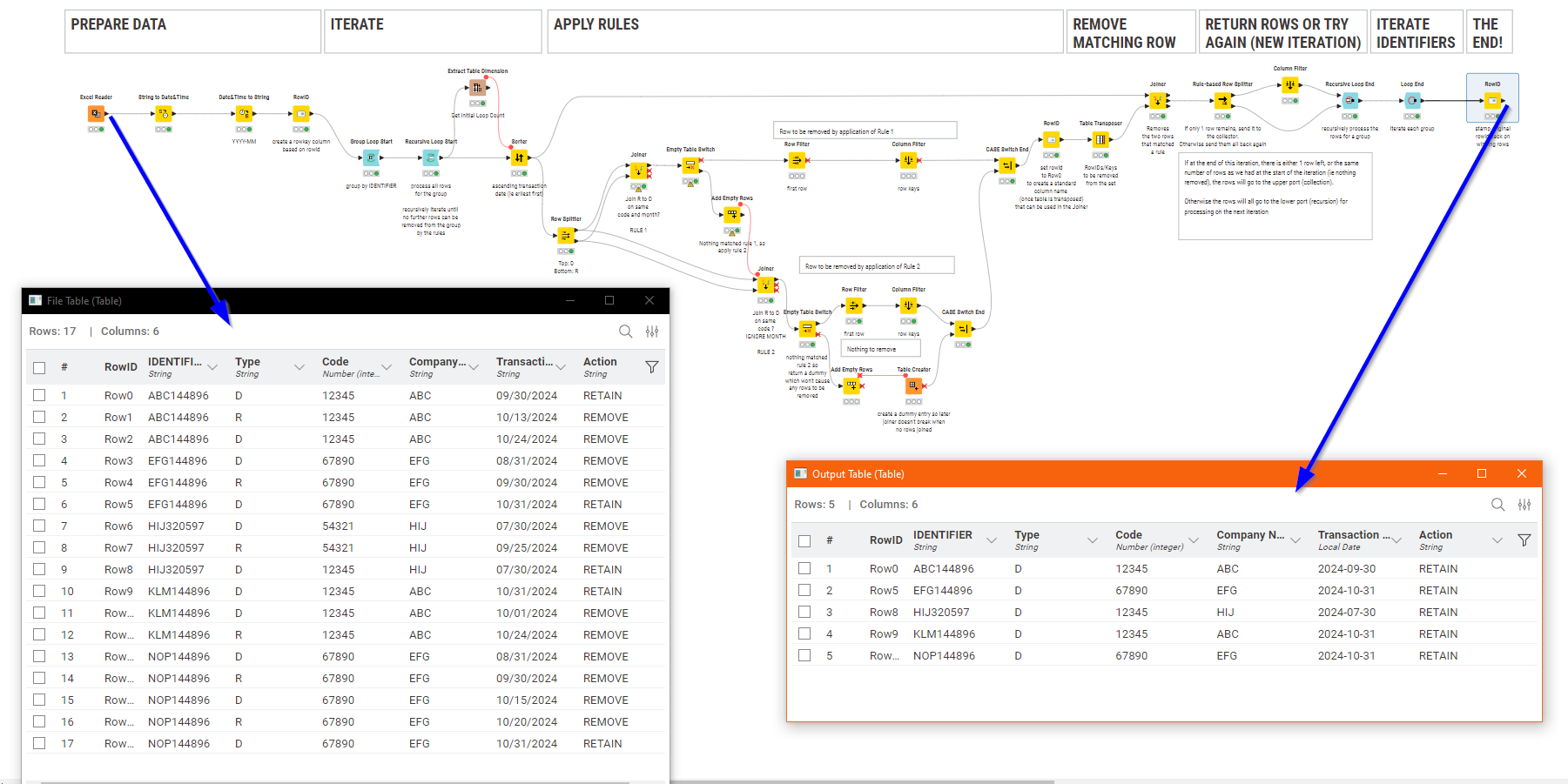
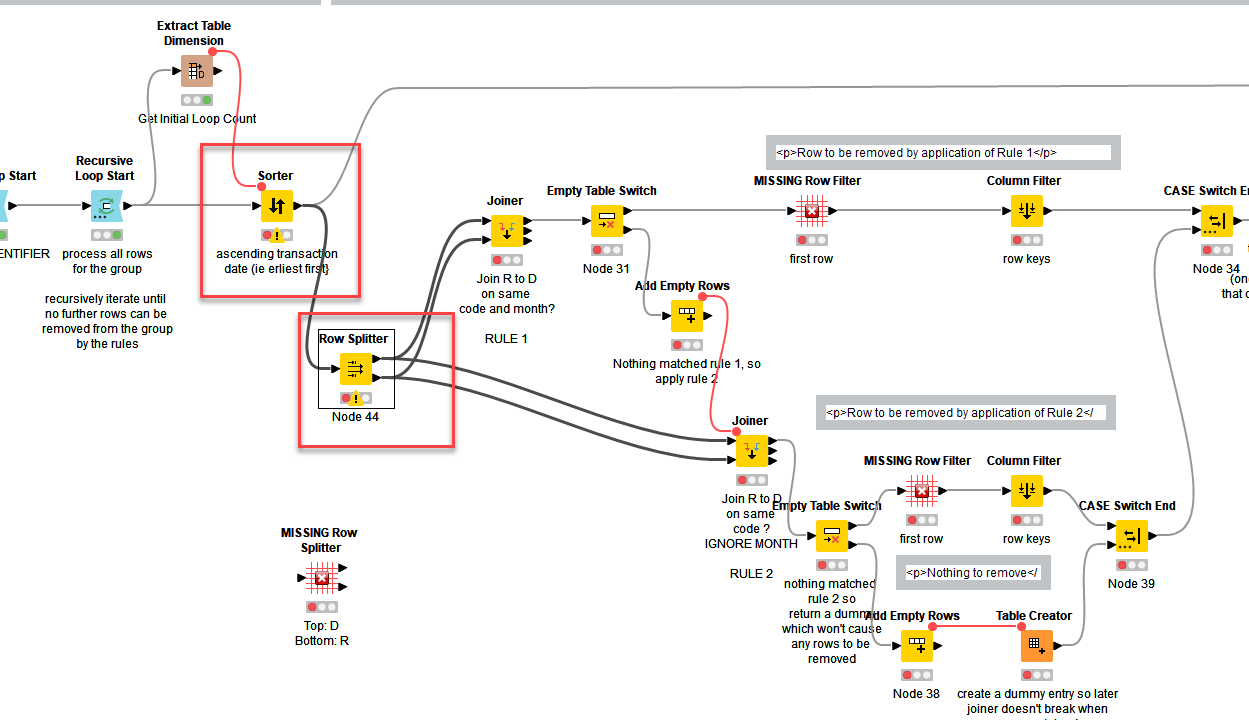
At the momentI’m tending to think that a Group Loop (grouped on IDENTIFIER) with an inner Recursive Loop to attempt to reduce down the group to a single row, based on the application of a set of rules might be the way forward.
I’d favour the type of approach in the direction I think @mlauber71 is headed, involving ranking and sorting to determine the “winner” in each case, but I haven’t got there with this one yet, as the different rows in each group need to be played off against each other.
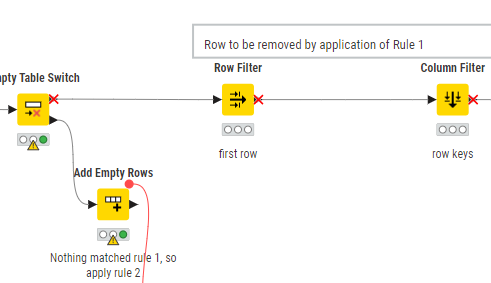
The basic “rules” appear to be:
If there is a D and an R of the same Identifier and Code in the same month, then the earliest D and R for that month for that Identifier and Code are both removed
If there is a D and an R with the same Identifier and Code in different months then the earliest D and R for that Identifier and Code are both removed.
I believe that these two rules if recursively executed in that order until no further rows can be removed will resolve all of the cases you have listed. I’ve yet to see if that’s right though… so still a work in progress
Thank you @takbb. I am still in 4.7.8 KNIME version. Would you mind sharing the configuration of your Row Splitter and other two Row Filter? Thank you so much!!
Here also @takbb, just want to know the config of row splitter and row filter. I have row splitter and row filter in my node repository it is just that the one you use is the updated one.
I think just a screenshot of the configuration will do.
But once I come to know your config, it will run perfectly. Thank you in advance!
Hi, yes it’s using the updated one because it was written in using KNIME 5.3.3. It would be nice to be able to choose to use an older version but sadly that option isn’t available.
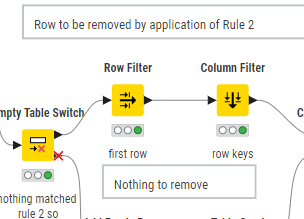
The comments on the workflow for the filters and splitters should be reasonably self-explanatory, but here is the detail:
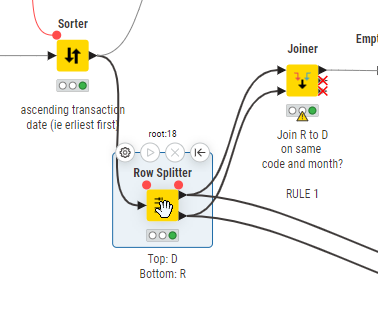
Row Splitter :
Top output port condition is: Type = D
Both Row Filters:
Output is Row Number = 1 (first row)
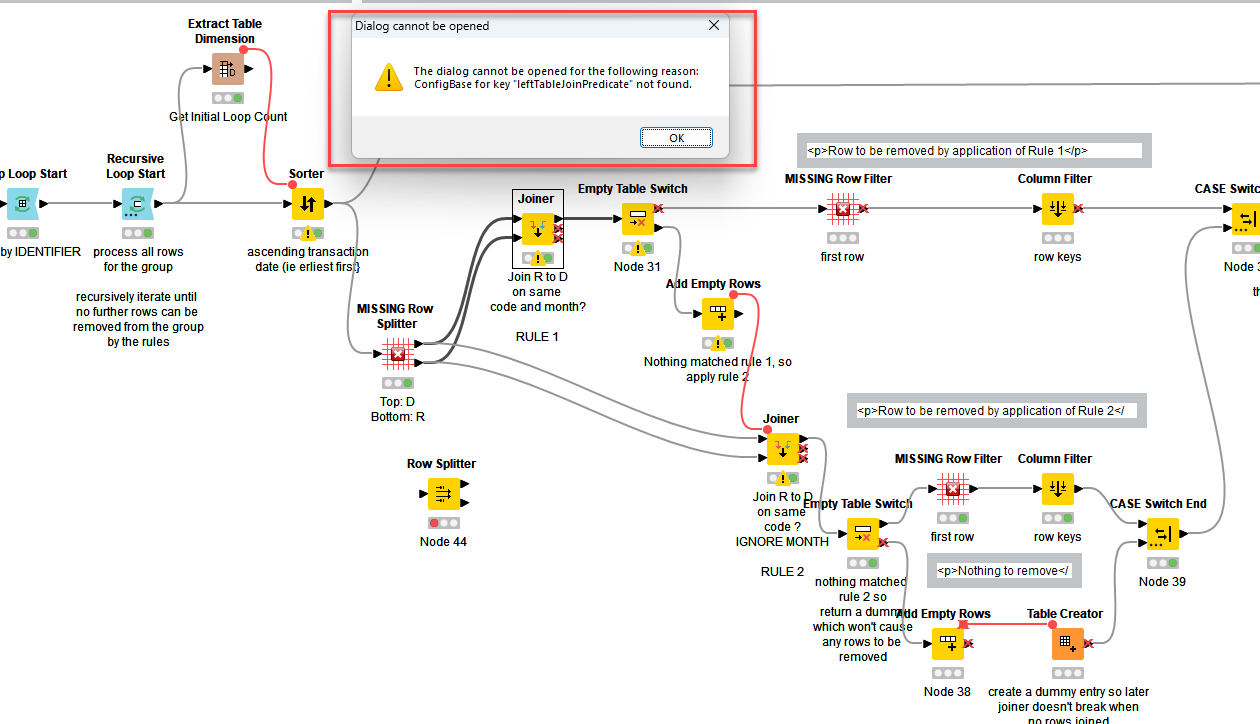
Thank you @takbb! I was able to do the editing or updating in Row Splitter however the sorter is kinda asking of the variable. Would you know what should I put in the flow variables inside joiner?
I think the joiner config can’t be opened, simply because the flow isn’t valid prior to the joiner. With the Row Splitter fixed, and executed, the joiner config should open. The joiners in this flow aren’t using flow variables.
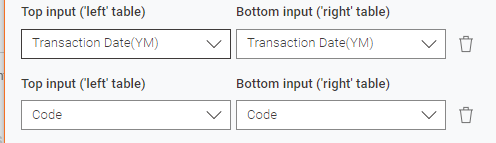
The joiner annotated “Join R to D on same code and month” is configured to join on these columns (images from Modern UI node config):
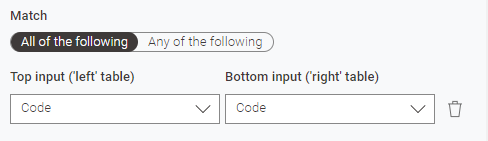
The second joiner annotated “Join R to D on same code IGNORE MONTH” is configured to join on just the code column:
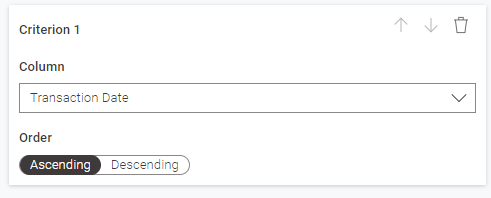
I don’t know why your Sorter is complaining. I suspect it just needs resetting. Open the configuration and ensure it is set to Ascending Transaction Date.
That is all it does.