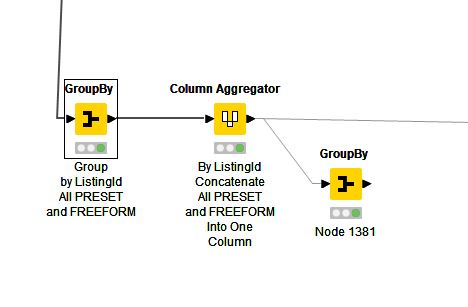
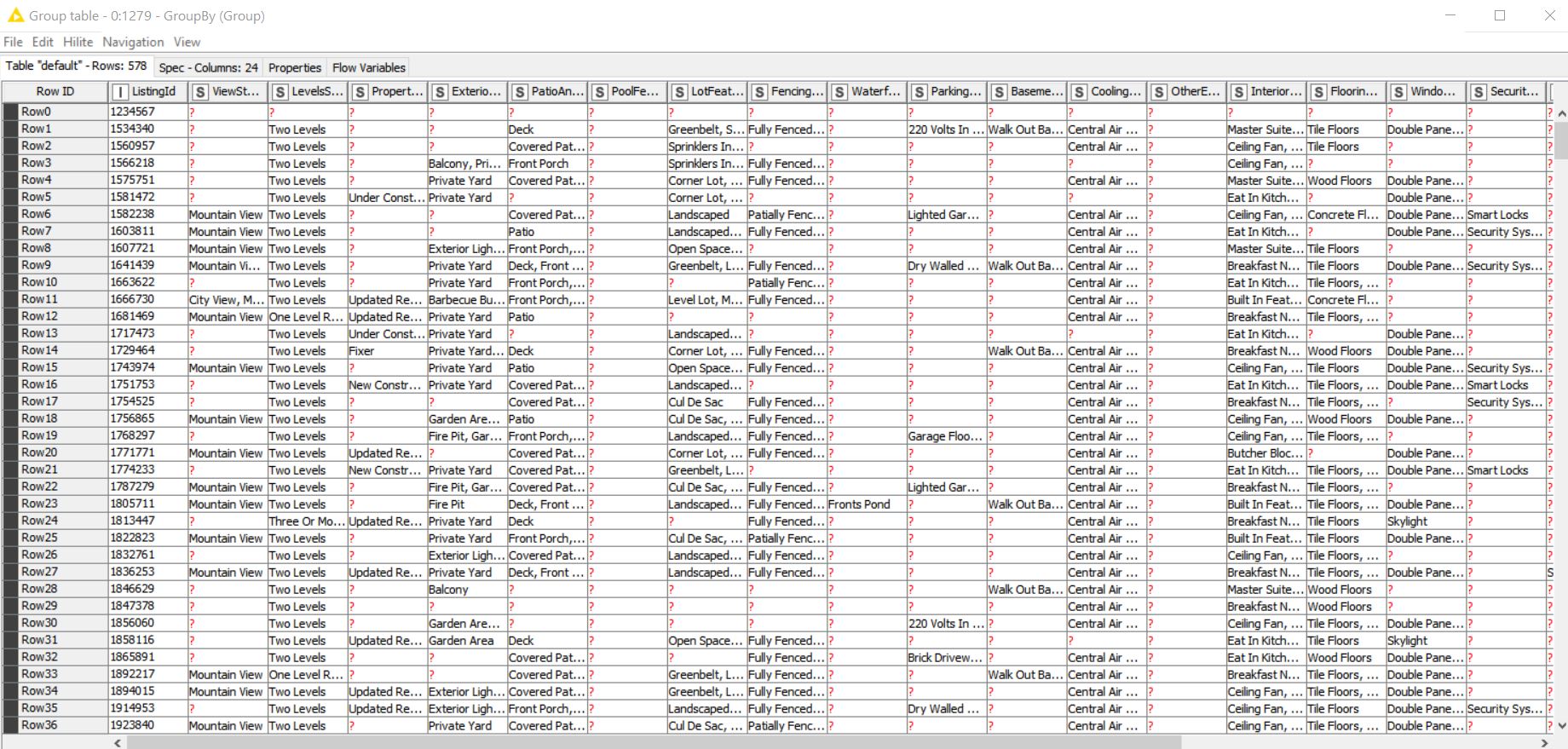
I have a table with many columns filled with text (string) and numeric (integer) data. Each row has a unique ID associated to the series of column data (ListingId).
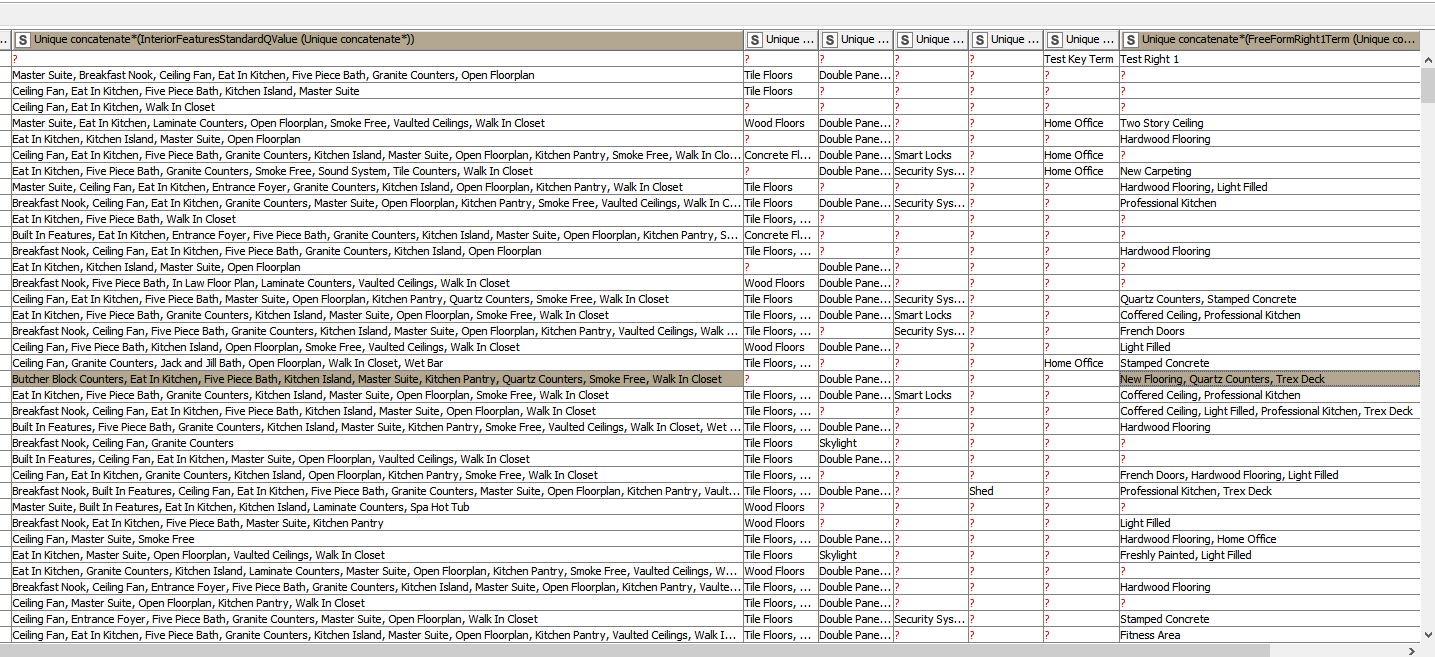
Note the highlighted row and how “Quartz Counters” appears twice in the same column.
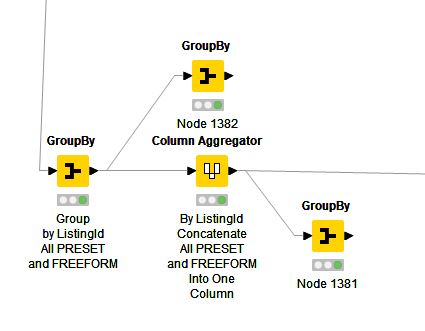
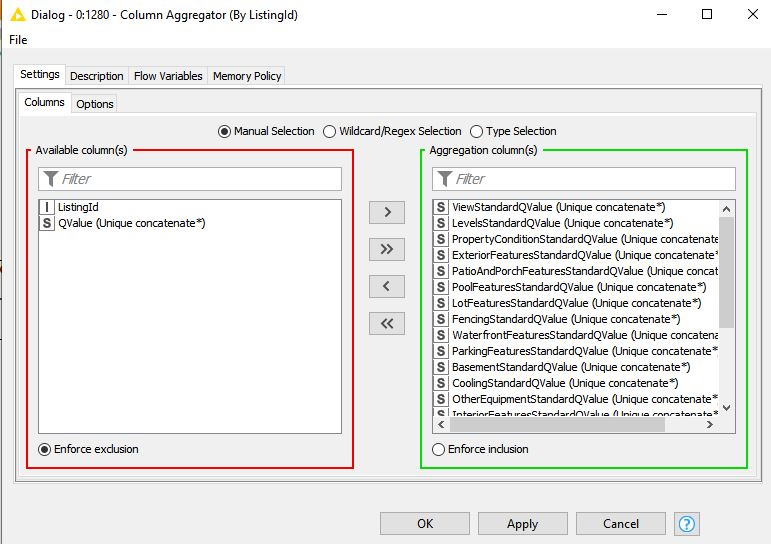
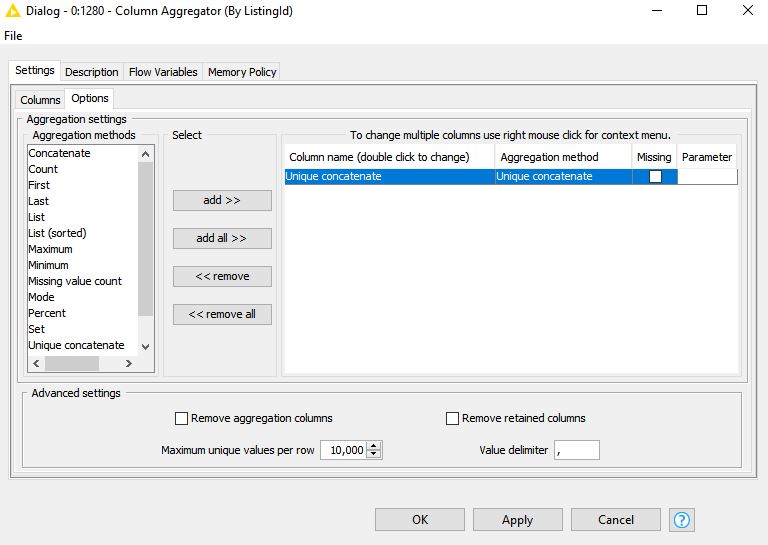
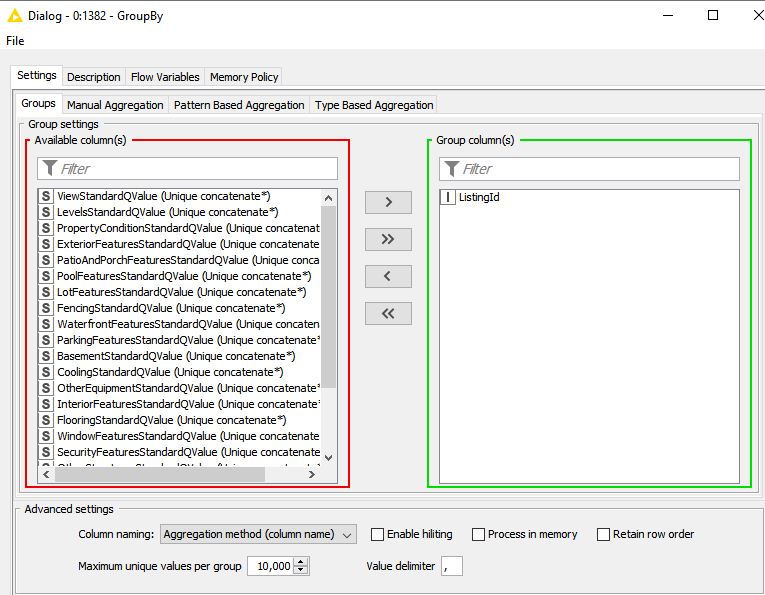
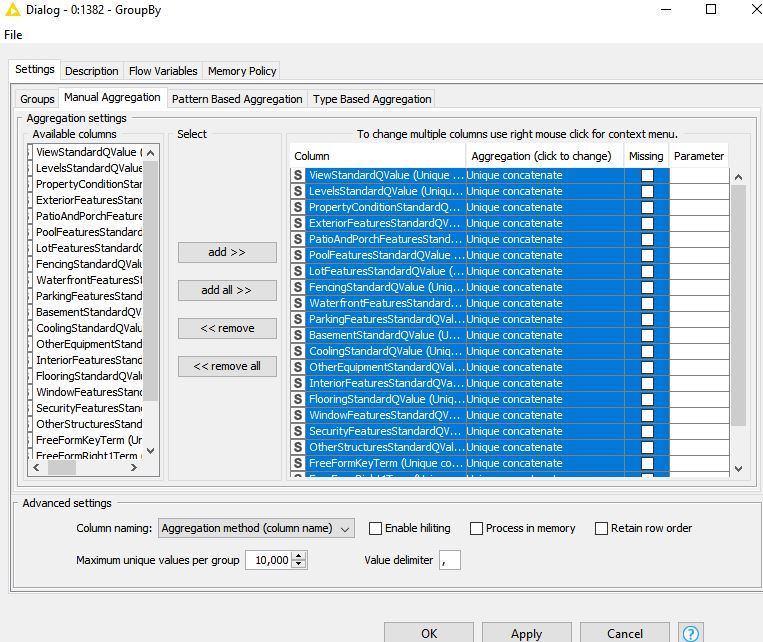
First separating the strings from the integers, I have tried “unique concatenate” on this aggregated string column using both Column Aggregator to remove duplicate data and Groupby using unique concatenate to remove duplicate data–both before and after the Column Aggregator process. Nothing removes the duplicate data in the aggregated column associated with the ListingId.
if I got you right you have value text1, text2, text3 in one column and value text3, text4 in another one. Option Unique concatenate output will not be text1, text2, text3, text4 but text1, text2, text3, text3, text4 as values compared are entire cells. You’ll notice difference if you change separator in Column Aggregator node to something different than comma. To get text1, text2, text3, text4 from above two column you need split your columns and then aggregate them.
Hi @smithcreed,
I can’t follow you. What is your final goal which you want to reach? Having a unique value for each ID or a unique value for each column or what else?
Can you explain it in a more detailed way?
in this case there are 577 unique ListingId’s. That is a constant. I have combined perhaps 30 columns of string (text) data from one analysis. Then a separate 4 columns of string (text) data from a second analysis. Finally, I place all of the text from the two groups into a single cell. At this point I see recurring terms, such as “Quartz Counters”.
When I combine the 34 columns of string data (text) i want to remove any redundant terms overlapping between group 1 and group 4–in this example, “Quartz Counters” which appear in both of the two groups.
I was hoping “unique concatenate” would do this, but it is not. Maybe it’s my misunderstanding of how this functions or maybe the settings or preparation I am using.
Then i suggest to split your combined strings for both analysises unpivot them keeping the ListingIDs, append both unpivoted tables and use groupby node again.
Therefore eache single value could be handled a duplicates removed.