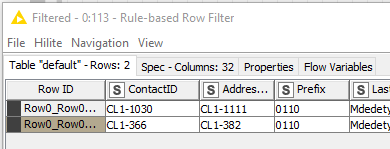
I have a table that has duplicate rows that I need to sort out. I cannot use the duplicate filter because there is another field that is linked to it so this is part of a much bigger KNIME flow. Below is an image of what I need to fix…
What I need to do is make sure that both rows have the same [ContactID] and [AddressID]. It does not matter which, but I have to make sure that both have the same ID fields. I will have to apply the same method in other parts of the flow as well to clean up other fields
Thanks for your responses. I have tried using RowId node suggestion but I should have included 2 extra factors that I have to take into account.
I have to use one of the [ContactID] & [AddressID] pairs because they are foreign keys in other tables. I can use either, but I have to use 1 of them, I cannot create a new one.
I cannot use the duplicate filter because there is a list field in another column that I need ungroup so I cannot lose any rows.
In this example, the ungroup will result in the same 2 rows but in others, the 2 rows maybe ungroup into 10, but the [ContactID] & [AddressID] must all be the same because ungrouped rows are going to be regrouped again using the ‘repaired/fixed’ [ContactID] & [AddressID] pair.
Can you suggest another elegant/simple solution? This set is 2 million rows so elegant/simple is good.
in deduplication you can aggregate towards a key. That means you will loose any other key that is not been aggregated to - if you want to preserve the information you will have to do something like
** aggregation functions like min, max, avg
** llists (list all the values in one cell) the group by function has such things
** separate variables that contain the information like
*** preserved_id_1, preserved_id_2
then you can choose to keep one line based on several criteria (that would contain the original structure and row integrity - like discussed in the links below). You would loose the information from the other lines
** if you want to preserve them you will have to aggregate them separately and then re-join via a preserved ID (preferably your key value)
The reason why I (somtimes) like the solution with the row_number forcing the reduction to a single unique line is that especially in very large datasets with a cascaded group by (over several fields) some duplicates might be lurking even if the providing database sweared that would not be possible (very common in Big Data environments). So if you want to be sure just eliminate a lone duplicate.
But that very much depends on your business case. If you cannot loose any information at all you will have to resort to one of the methods mentioned above.
I am a fan of your 1st solution in your reply. I have implemented it in a flow that runs every night to process between 5 and 6 million transaction rows to update a customer segmentation report. I have been tempted to replace it with a Duplication Filter node but feel much more comfortable with the process as it is. It does take a few seconds longer but I like the additional insight of your workflow. I agree with your comment on the need for a COUNT(*) function.
As you suggested as well … I will probably have to implement an aggregation (min/max) method and then “rebuild” the key values.
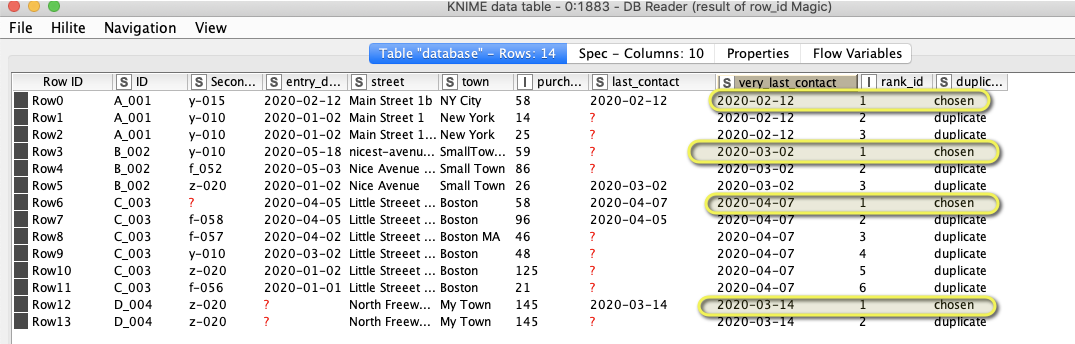
Really Nice - Interestingly a null last contact for ID B_002 is carried thru in the example with the DB reader due to the sorting. Obviously there are lots of ways to get that date back. As an example i added a group by ID with max last contact attached to [result of row_id Magic] and prior to the Rule based Row filter and then a joiner node and then would some rule node to re-append. Whats the easy way to get something like that back?
Yes this is due to using the whole line according to the entry_date. One could just use the Duplicate Row Filter and sort by last_contact descending and rejoin like with the largest purchase ever.
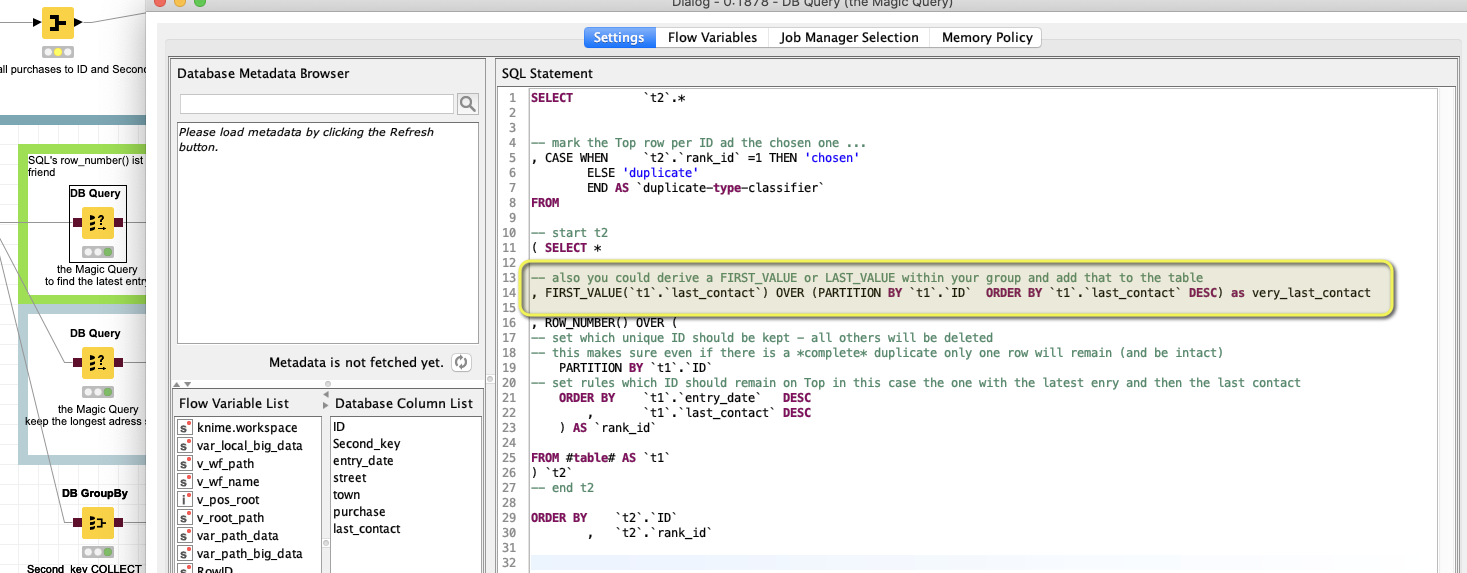
Or you could just do that within SQL (Hive) and select a FIRST or LAST VALUE like this: