Is there anyway I can execute Rule based Row filter node in parallel ?
Requirement is I have 1 millions records as an input table data for Rule based Row filter node containing data for different rules and total number of rules are 100 ,I just want to execute all 100 rule in parallel because in serial it is taking approximately 50 minutes. I want to reduce its time.
Another way would be to split your input data into smaller data sets using multiple Rule-based Row Splitter node and connect each smaller set to one Rule node. Finally use Concatenate to bring data back together.
Core issue is that rule-bases row filter most likley isn’t all that fast and the intended use-case was most likley for a handful of rules and not as many as 100 rules.
Depending on the rules you could try to chain them (potentially using splitter instead of filter) and wrap that in a component with streaming execution.
Rule-based Row Filter (Dictionary) is doing the same thing in 1 minute for all 1 million records and 100 rules but now I am unable to map the rule_id with the filtered data.Is there any way to map rule_id with
Rule-based Row Filter (Dictionary)?
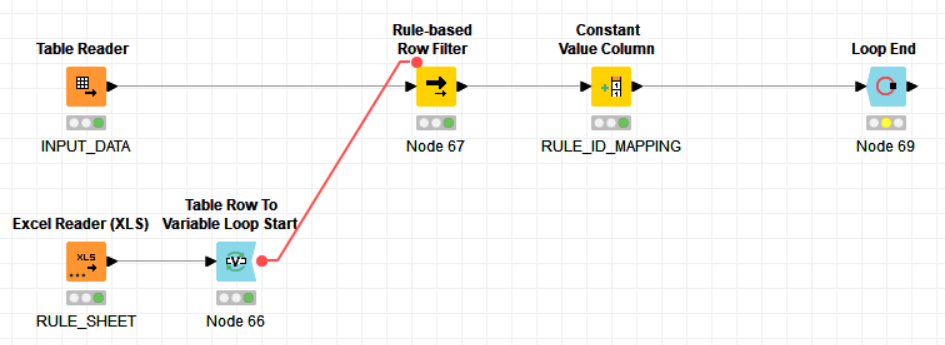
In my existing design I am mapping the rule_id as well with the help of constant value column by passing rule id as variable from Rule_sheet(Attached)rule_SHEET.xlsx (11.0 KB) .
if you want to add rule_id I would suggest a bit different approach. First use Rule Engine (Dictionary) node to add Rule_id column. IF no rule matches you will have missing value based on which you can filter then. Check attached example: rule_based_filter_dictionary_ipazin.knwf (49.9 KB)
String Manipulation node is only needed to modify existing rules. Additionally see how you can include and reference data into your workflows using data folder and relative to option from Excel Reader.
I Have found one issue in RULE ENGINE(DICTIONARY) for below scenario:
$RESIDENCY $ in (“JOY”,“JON”) AND UNQID IN (1,2)=>“P”
$RESIDENCY $ =“JOY” AND UNQID IN (1,2)=>“Q”
I have written above two condition in RULE ENGINE(for testing) which can be a valid scenario but RULE engine is not working for second condition because this condition is covered in First condition(IN operator) which should not be the case. Please suggest something, It is Really important.
Rule engine checks for first match and returns that value right? so that’s what I would expect. For getting both you probably need to run 2 rule engines.Your mentioned structure probably needs additional shaping afterwards
bR
I have 50000 rules in my rulesheet…i am trying to loop the rule engine…it is working but with really poor performance which I cant afford:grimacing:…so @izaychik63@ipazin@Daniel_Weikert…please suggest some better approach if possible
if you need 2 or multiple outputs (as multiple rows) from a single row then using single Rule Engine obviously won’t work. You can try following approach:
use modified rules whenever you need/can get multiple outputs. Rule should output all needed values separated with comma or any other delimiter example: value1, value2,..., valuen
follow it by Cell Splitter node with specified delimiter
finish it with Unpivoting node where value columns will be all column created with above splitting operation and retained columns are all those you wish to leave and “multiply”
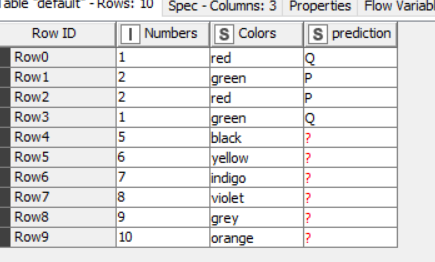
 …so
…so