There is an issue with the SAP Reader (Theobald Software) node in KNIME.
The extraction of a BW Query is set-up in the XtractUniversal and it works fine it shows correct data but in KNIME some records doesn’t appear, if I use the GET Request node, then I can perform the call to the extraction and get all the data, but not if I use the SAP Reader node:
I see that regarding the Hierarchies issue, it is in the roadmap, but this is different issue (sorry for adding this information in the same ticket).
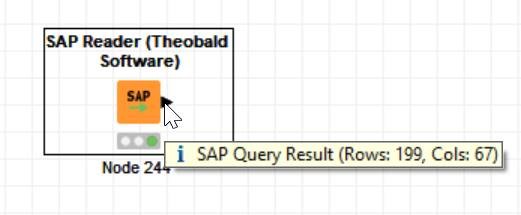
The NEW issue is that in some BW Query extractions, the data that is available in KNIME through the SAP Reader (Theobald software) node is not the complete data set!
This is a huge bug as we cannot then rely on this node for which we pay a license.
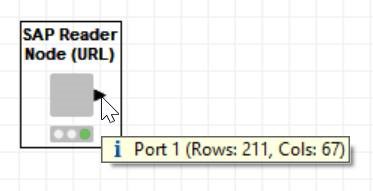
Please see the attached screenshots above and let me know in case any clarification is needed.
Using the SAP Reader node we get 199 rows
Using GET request call we get 211 rows
so with the new KNIME version 4.4.2, the hierarchy extraction worked even with empty Date field.
However we have an issue while extracting data from a BW Query where the Date field value is ‘#’, for those records, the data is not replicated to KNIME.
In short when we try to extract data through SAP Reader (Theobald Software) node where we have date type field with “#” value complete row is ignored and we do not receive any data.
If we setup second extraction without the date field with “#” value all fields are being extracted perfectly fine.
Hello @MarcEM ,
the problem is the leading # character. The node uses internally a CSV library to parse the result from Xtract Universal which uses # as default comment character. This means that each row that starts with a # is ignored. We will fix this problem with the next 4.6.6, 4.7.3 and 5.0.1 release.
Bye
Tobias