with the recent update to 5.1 I happen to notice that saving a workflow requires considerably more time. I had already saved and restarted a few times but the overall performance during a save seems to be considerably slower.
The workflow in question took about a minute to start saving and than progressed rather slowly and with inconsistent saving times upon each save compared to the previous Knime version.
Thank you for your feedback.
Does it happen to all workflows or to a specific workflow?
Is it possible for you to provide an example workflow/instructions so we can replicate the issue?
so far the experience was erratic but I didn‘t had the chance to test a variety of workflows, though.
The primary difference to other workflows I had is that the table contained images. Just a few hundred, though, which collectively account for a few hundred, maybe 1 GB worth if data.
However, I saved in between steps and all nodes were already cached / written to the disc.
At the moment I am on the move nit having access until beginning of the next week to my workstation. If I can identify more circumstances or reliably reproduce the issue, I will let you know immediately.
Hi,
I am experiencing exactly the same problem. Knime has become extremely slow when updating to 5.1. On top of that, when saving workflows it takes for ever.
Coming back to this since @Fernando brought it back up. Knime, maybe Windows 11 or both seem to have a serious performance issue when writing data to disk.
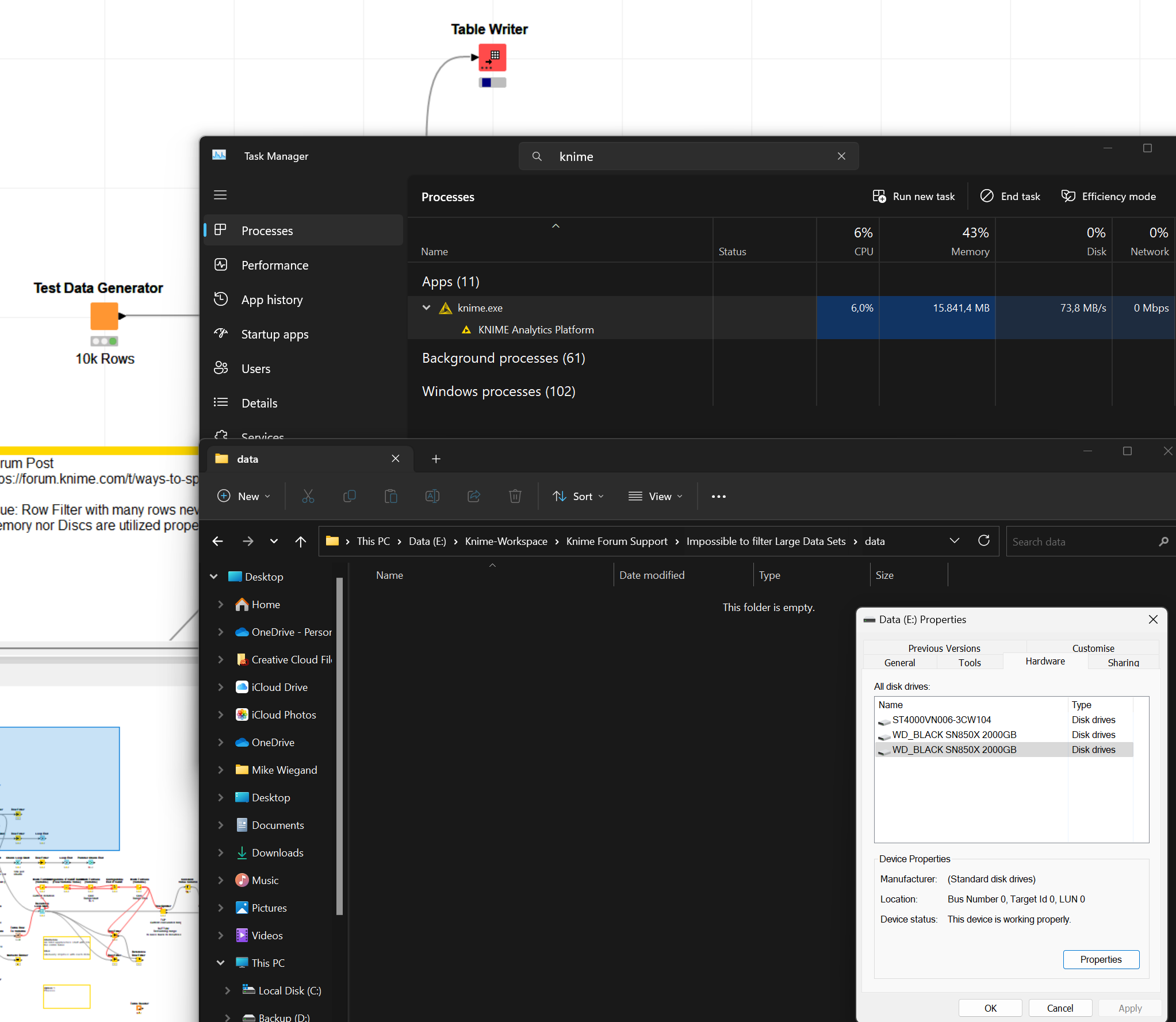
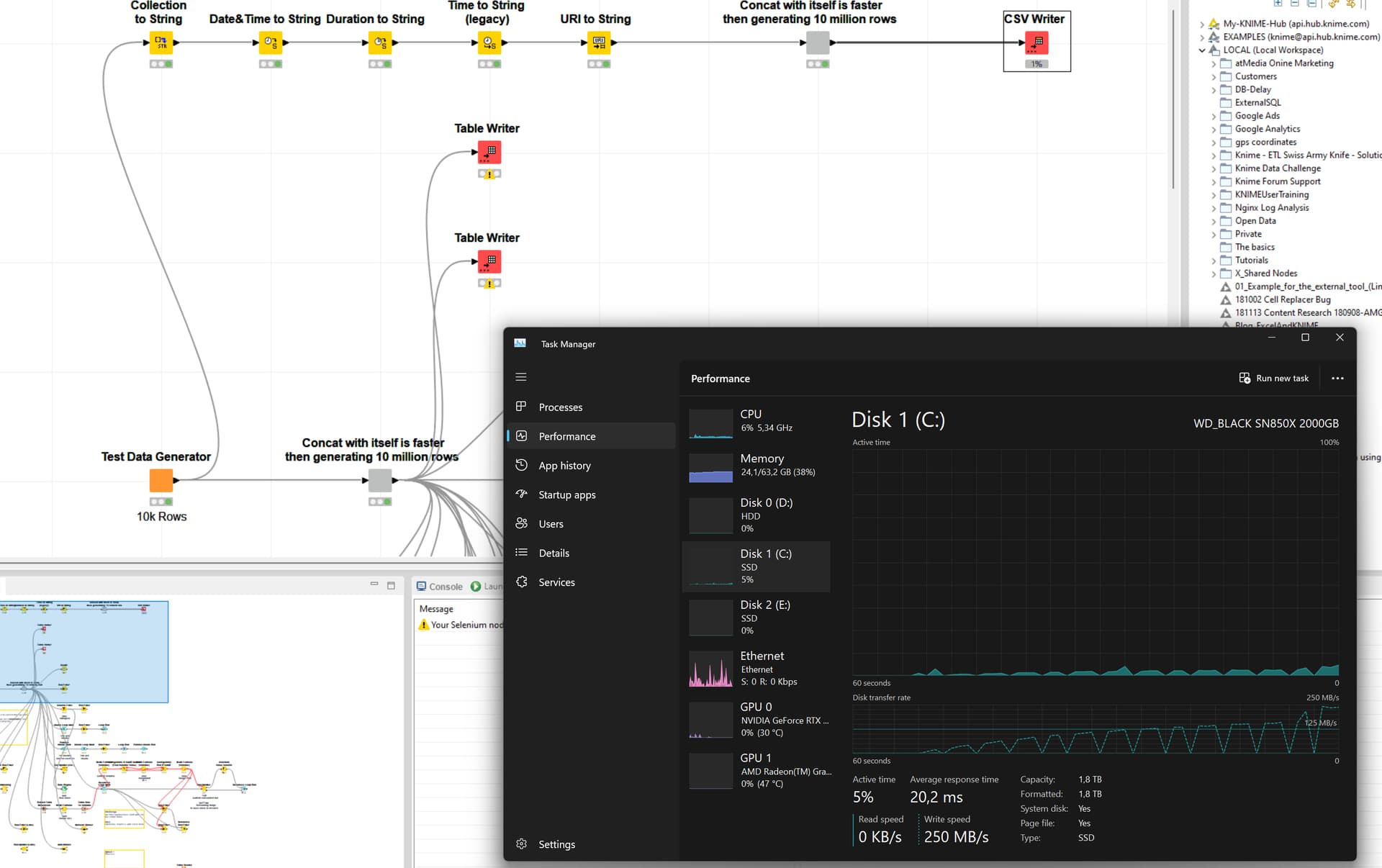
I created this workflow to easily create large amount of different data types.
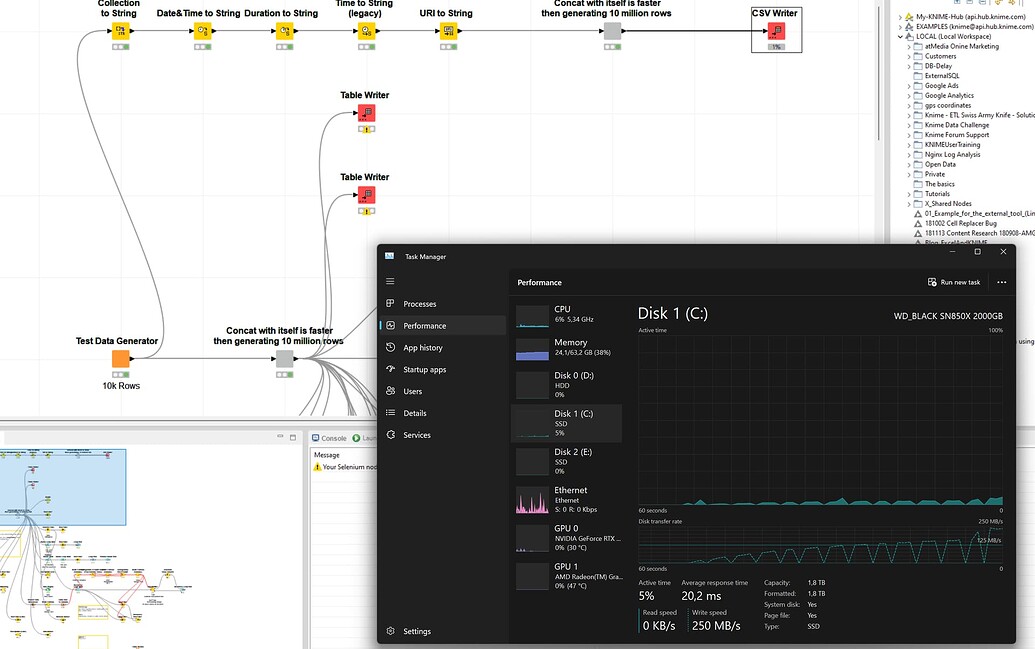
When trying to write them to the disk, write speeds briefly burst to several hundreds of MB and then plummet down. Contrary to tests the write speed is far slower then expected indicating some sort of bottle neck:
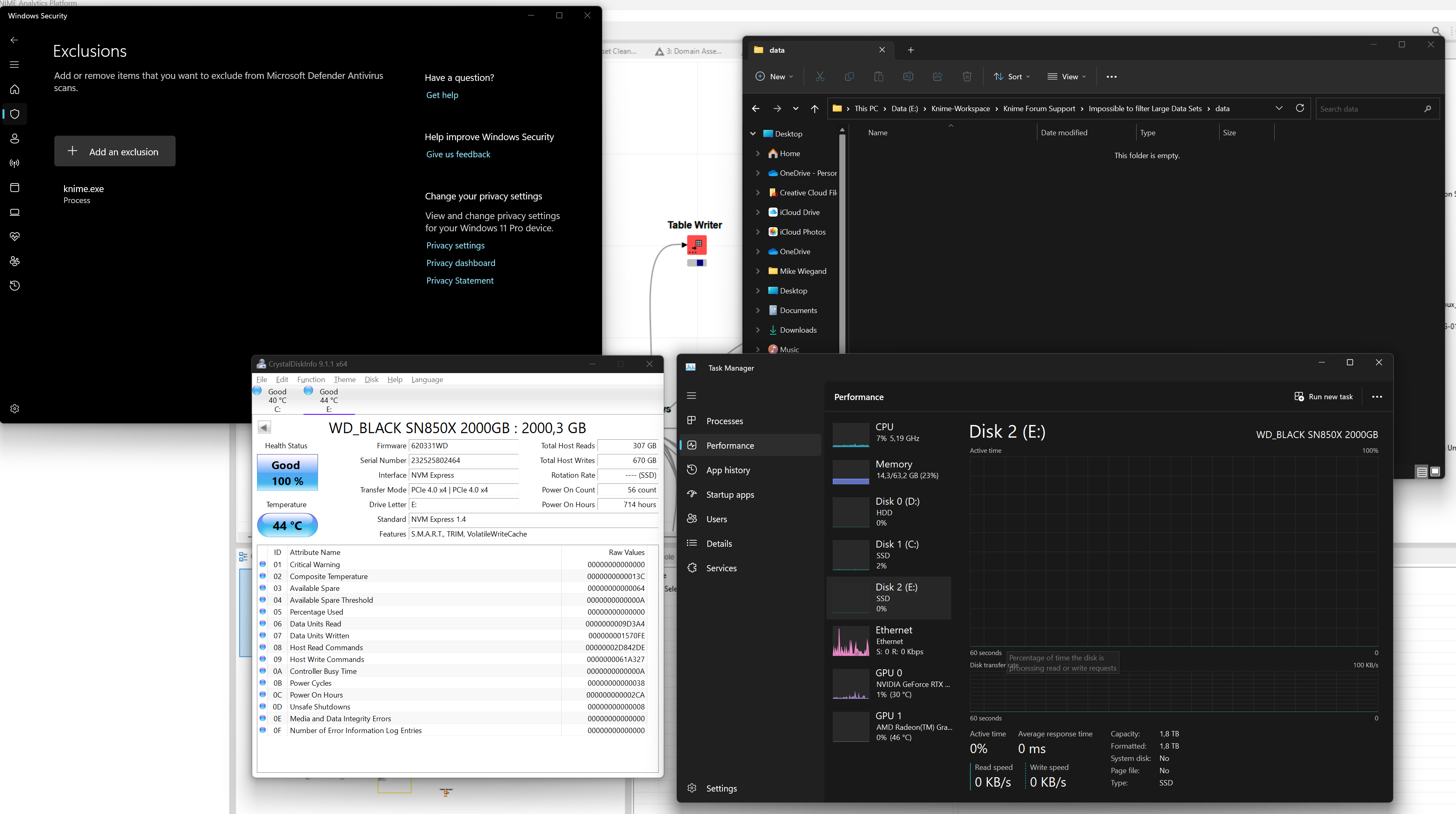
It’s been about ten minutes since the prev. screenshot and the SSD is not thermal throttleing. Yet, Knime is still writing but as seen above, it seems not to the second disc “E” as it is pretty much idle.
@armingrudd there have been quite a few topics in the recent past about performance a regression. The not officially acknowledged Window fix of slow SSDs is installed but I do not see any improvement. Regardless of the backend type, row or columnar based, writing data should be … fast.
Yet, Knime or Winbdows (I really don’t want to blame any app here) seems to behave odd to say the least while writing data without writing data as the 2nd SSD is idle.
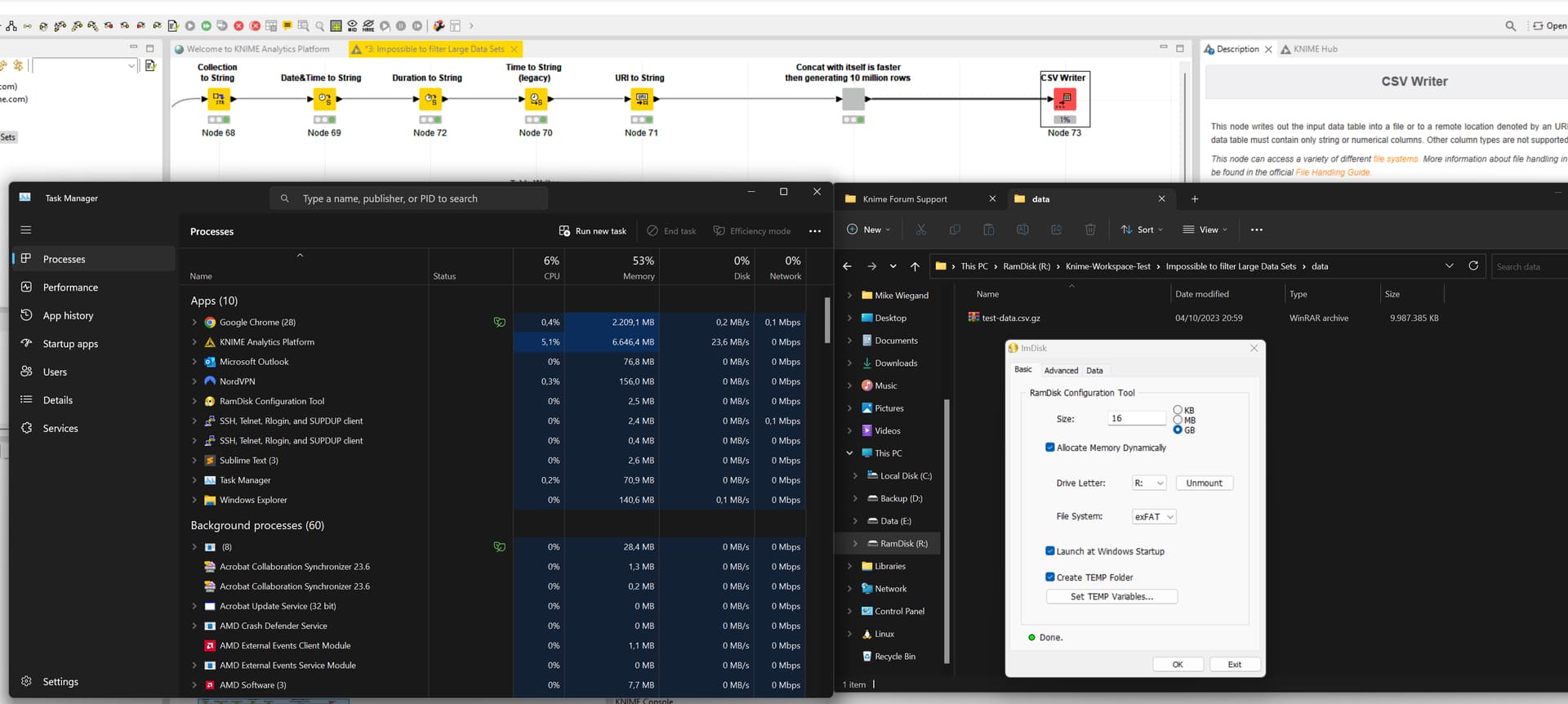
You are most welcome. I ave this some addition thought and at came to the conclusion that the possible issue must get narrowed down before. Therefore I converted all special column types to string in order to save it to my primary disk, same type of WD_BLACK SN850X 2TB M. 2 SSD, but as CSV.
Worth to note in advance is that I quickly paid the groceries store a visit an the table writer didn’t even reached 1 %.
Surprisingly the CSV writer seems substantially faster but peaking at around 140 MB/s. Circa 15 minutes in it reached 13 %. What intrigues me is the fluctuating throughput which, from my perspective, is massively hampering the performance.
A colleague of mine asked in regards to another but still Knime-related question why I am not using a Ramdisk. You might have seen my feature suggestion.
Anyways, I played a bit around and noticed something which might be of help. Despite utilizing a Ramdisk, when I enable gzip compression with the CSV Writer node, performance plummeted even though CPU utilization, which I’d expect to significantly increase, was almost idle.
Saving only 10k rows instead of 10 million the CSV is more than 1 GB in size. This begs two questions:
Theoretically the 10 million rows (Output of the component) do not fit in the 64 GB of memory. The component simply appends one table to itself utilizing exponential growth. However, this is completed in just a few seconds. Question is, does Knime actually generate the data upon writing the CSV? But how does this compare to saving the workflow which is much faster?
The Gzip compression should be much faster and utilize pretty much all cores. Like here when I compress the very same data using WinRAR. Why did compression became the bottle neck and write speed dropped by a factor of more than three from 70 to just 20 MB/s?
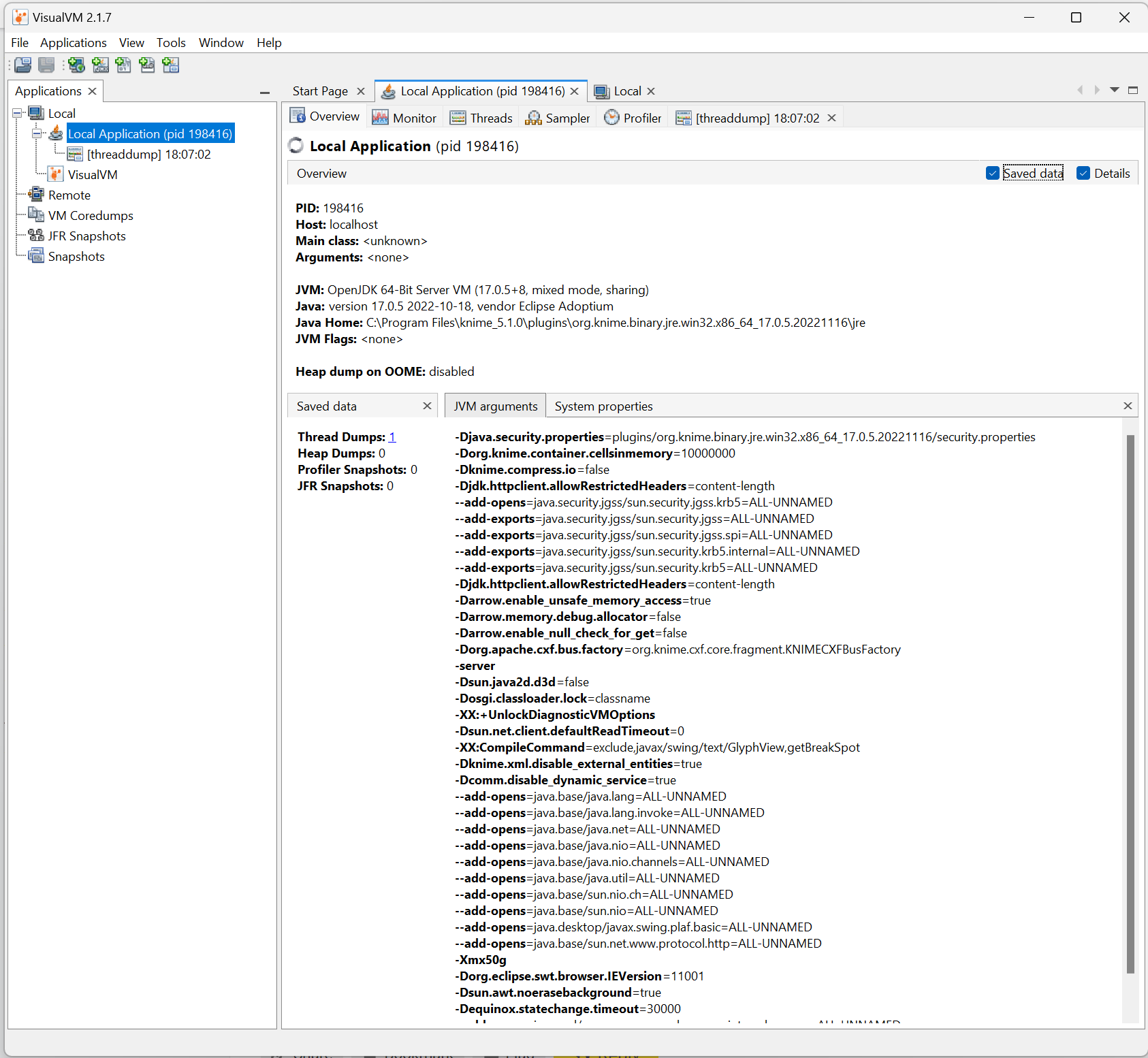
From the knime-5-1-1-thread-dump.txt file you linked above I can draw these conclusions:
There is one single CPU fully busy deserializing nested data structures
old date&time types (seeing that also in the workflow screenshot) - certainly worth a test switching to the ‘new’ nodes (not exactly new … they were released in 3.4, so 6 years ago )
these elements are nested in some list cell - so it doesn’t appear to be a plain native cell?
the table format is the old backend
Hiding the relevant part of the log here as it's probably only helpful for developers.
"KNIME-Worker-25-CSV Writer 3:73" #1346 daemon prio=3 os_prio=-1 cpu=2292984.38ms elapsed=2379.22s tid=0x00000000712f6a60 nid=0x30574 runnable [0x000000007466c000]
java.lang.Thread.State: RUNNABLE
at java.util.GregorianCalendar.computeFields(java.base@17.0.5/Unknown Source)
at java.util.Calendar.setTimeInMillis(java.base@17.0.5/Unknown Source)
at org.knime.core.data.date.DateAndTimeCell.<init>(DateAndTimeCell.java:256)
at org.knime.core.data.date.DateAndTimeCellSerializer.deserialize(DateAndTimeCellSerializer.java:77)
at org.knime.core.data.date.DateAndTimeCellSerializer.deserialize(DateAndTimeCellSerializer.java:1)
at org.knime.core.data.container.DCObjectInputVersion2.readDataCellPerKNIMESerializer(DCObjectInputVersion2.java:104)
at org.knime.core.data.container.BufferFromFileIteratorVersion20$DataCellStreamReader.readDataCell(BufferFromFileIteratorVersion20.java:366)
at org.knime.core.data.container.DCObjectInputVersion2$DCLongUTFDataInputStream.readDataCell(DCObjectInputVersion2.java:245)
at org.knime.core.data.collection.BlobSupportDataCellList.deserialize(BlobSupportDataCellList.java:256)
at org.knime.core.data.collection.ListCell$ListCellSerializer.deserialize(ListCell.java:176)
at org.knime.core.data.collection.ListCell$ListCellSerializer.deserialize(ListCell.java:1)
at org.knime.core.data.container.DCObjectInputVersion2.readDataCellPerKNIMESerializer(DCObjectInputVersion2.java:104)
at org.knime.core.data.container.BufferFromFileIteratorVersion20$DataCellStreamReader.readDataCell(BufferFromFileIteratorVersion20.java:366)
at org.knime.core.data.container.BufferFromFileIteratorVersion20.next(BufferFromFileIteratorVersion20.java:172)
- locked <0x00000000cc300060> (a org.knime.core.data.container.BufferFromFileIteratorVersion20)
at org.knime.core.data.container.BufferFromFileIteratorVersion20.next(BufferFromFileIteratorVersion20.java:1)
at org.knime.core.data.container.filter.FilterDelegateRowIterator.internalNext(FilterDelegateRowIterator.java:130)
at org.knime.core.data.container.filter.FilterDelegateRowIterator.next(FilterDelegateRowIterator.java:123)
at org.knime.core.data.container.storage.AbstractTableStoreReader$1.next(AbstractTableStoreReader.java:220)
at org.knime.core.data.container.JoinTableIterator.next(JoinTableIterator.java:98)
at org.knime.core.data.container.JoinTableIterator.next(JoinTableIterator.java:98)
at org.knime.core.data.container.JoinTableIterator.next(JoinTableIterator.java:98)
at org.knime.core.data.container.JoinTableIterator.next(JoinTableIterator.java:98)
at org.knime.core.data.container.JoinTableIterator.next(JoinTableIterator.java:98)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.data.append.AppendedRowsIterator.initNextRow(AppendedRowsIterator.java:208)
at org.knime.core.data.append.AppendedRowsIterator.next(AppendedRowsIterator.java:180)
at org.knime.core.node.streamable.DataTableRowInput.poll(DataTableRowInput.java:91)
at org.knime.base.node.io.filehandling.csv.writer.CSVWriter2.writeRows(CSVWriter2.java:181)
at org.knime.base.node.io.filehandling.csv.writer.CSVWriter2NodeModel.writeToFile(CSVWriter2NodeModel.java:184)
at org.knime.base.node.io.filehandling.csv.writer.CSVWriter2NodeModel.execute(CSVWriter2NodeModel.java:147)
@wiswedel that is odd as none of the cores were even close to being fully utilized per windows task manager. The table Format was generated by the Test Data Generator Node configured using v1 instead of legacy.
I do recall that I mentioned before that this node, because it generates outdated data types, seems in need of an update. Maybe adding v2 or “most recent” would be an option.
Nevertheless, I also converted all special data types, including the outdated date&time as well as duration data to simple strings in order to use a CSV writer. Whilst being slightly faster, write speed drops over the course of hours to the same level and basically never finishes.
As far as I understand the nested data must get deserialized which would explain the fluctuating write speeds as seen in this screenshot of mine from before:
That explains it! The “Test Data Generator” node is part of the testing extensions that we use internally (but also community node developers) to write unit tests and workflow tests to guarantee correctness of all sorts of compatibility challenges. It produces data, including deprecated data types, which is not relevant in any real world scenario. KNIME’s type system is very rich and we can tell from history that once in a while there is some community extension that does crazy things, like 3rd party types embedded in collections of variable type etc. This node allows us to simulate some of this.
Again, it’s part of a testing extension, the category is called “KNIME Node Development Tools”.
If you needed some larger data to simulate and stimulate CPU and I/O usage I would use some public benchmark (some kaggle data, for instance this one).
Maybe we should do a reset here and focus on the problem you mentioned in your first post (I realize now that you do have real data at hand). Do you mind extracting a similar file to knime-5-1-1-thread-dump.txt using your own custom data?
Thanks for your feedback @wiswedel. When I find some time I will use the kaggle data and upload a topic agnostic workflow or update the one I linked before.
About legacy data types. I’d not wave the presence of these away that easily as I do know that some had, and might still have, Knime version 3 in production. Adding to this, those I referenced are not the ordinary tiny nor even mid-sized businesses. So as far as I can conclude, even thought I helped the aforementioned to update to a more recent version, it is a fairly realistic scenario.