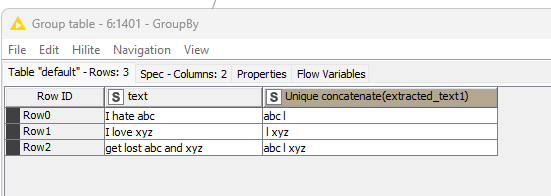
The attached image has the example of the Input data and how the Output data to be reflected.
I used Rule Engine (Dictionary) to add a single word, but not sure how to do it for multiple words.
If there is an existing post for this topic, please do tag it. I did not find a similar post, hence created this.
P.S.- If $words_found$ order (text position?) is important, some additional work would be needed; sorting based on indexOf() can be added in the loop as well.
Please see the workflow attached. I believe it’s easiest to do with regex-based nodes & loops. Examples below using either palladian’s regex extractor (available on nodepit) or Column expressions: