we’ve been in touch via email this afternoon – I’ll answer this here.
To familiarize yourself with the Selenium Nodes, I suggest to have a look at these entertaining and educational videos which I cannot recommend enough, by two power users of the nodes, @kowisoft and @armingrudd:
What’s generally helpful as well is the existing threads in the Selenium Nodes subforum which you find here – it’ll lead you to some hidden gems like this one, which you can surely adapt to your specific problems:
Several example workflows using the Selenium Nodes are available on NodePit, the most comprehensive search engine for KNIME nodes and workflows: selenium — NodePit
I hope this helps to get started – keep me posted how it goes! If you require more in depth support, please post a workflow which shows your current progress and describe where you’re having trouble.
in general I would approach this to get a max list of all entries based on your search criteria and then process this “offline” within KNIME.
What I mean by that is to download the whole page source based on your search result and then convert the xml data that makes a website into a KNIME table.
If you could provide a link to the specific website you’d like to query, I am sure, we can come up with something.
@qqilihq thanks for the kind words Really appreciate that
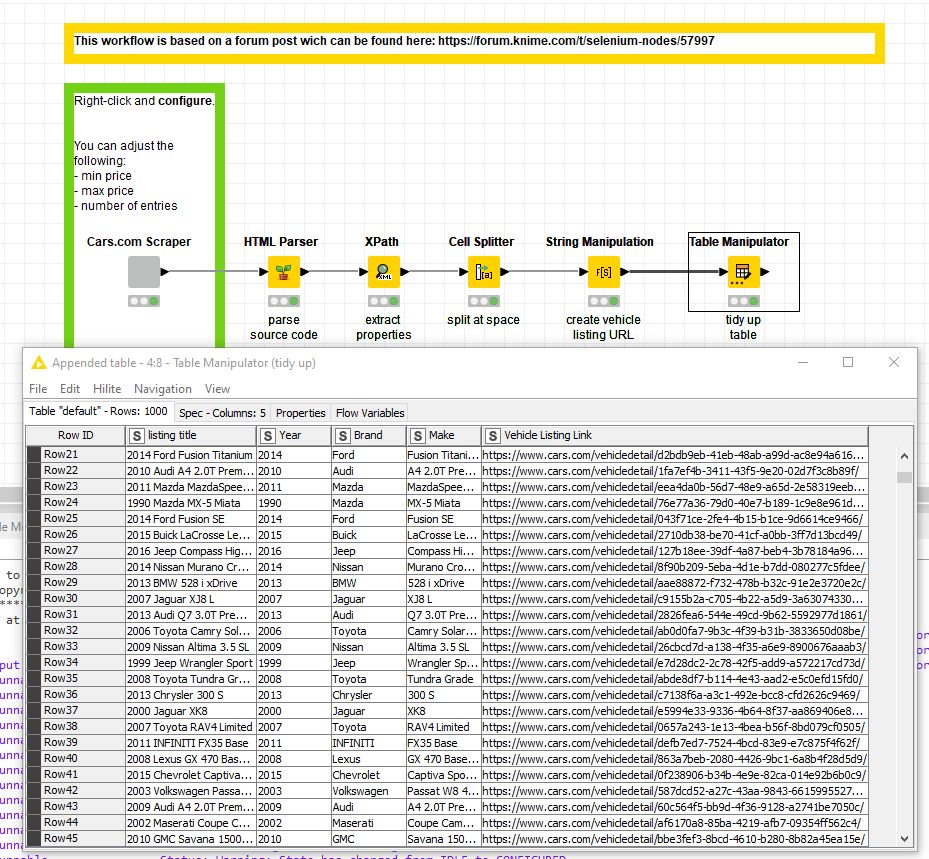
I used the configuration nodes to allow the user to configure the input into the component (e. g. min price, max price and number of entries to be returned).
Note: the SE Nodes run in the component, there is maybe a better way to structure that but it was just for these testing purposes. Hence the components takes a while until it is finished. If you want to have more control then manually run the loop within the component.
Interesting that all search parameters are “hard coded” into the result URL. With thatl, all you have to do is to make a clever combination of your parameters and the String Manipulation Node (Variable)
I also splitted the resulting items by space as cars.com seems to have a clear “titling policy” as in “YEAR [space] Brand [space] everything else”
I also couldn’t locate any ID, at least not in the ovierview pages which my workflow scrapes. I don’t have the time to deep dive into every results page and hence I return the detail listing page for every line item which enables you to go deeper if you want.
Yeah . I see you.
We can talk 1:1 video for tonight on zoom etc.
In the meantime somepoints that I didn’t understnad (like Where selenium used this workflow)
Do you have any guide to learn quickly KNIME and Selenium nodes usage. I can watch and learn sth to our meeting.
Thank you so much @kowisoft your video is that very understandable.
As you know that in my case I should use Selenium Node.
And I set up Selenium Nodes. So I have a 2 problem;
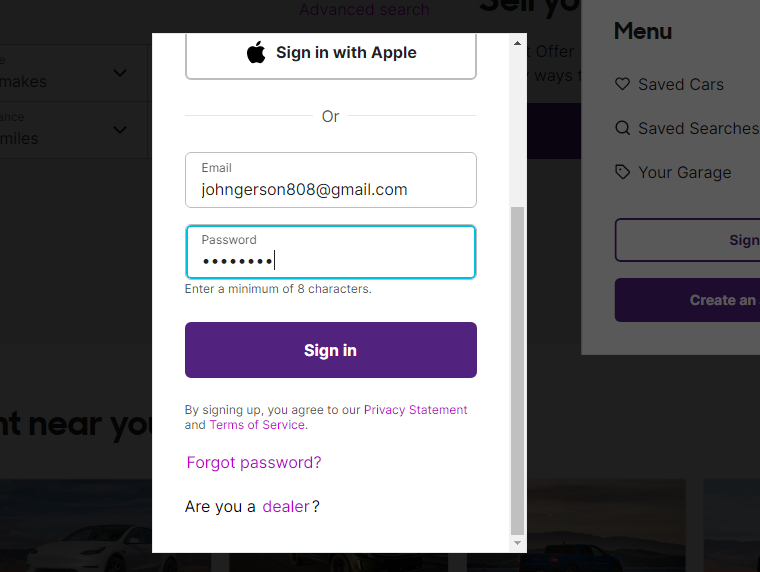
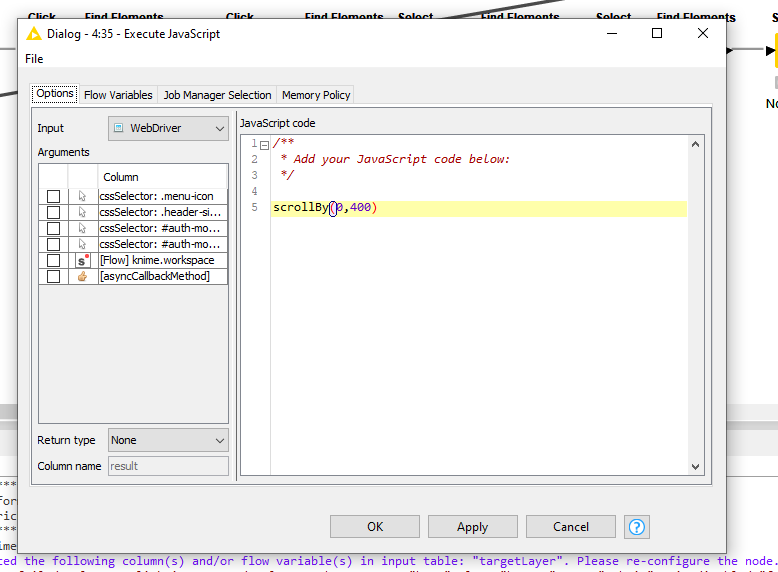
I can’t scroll down popup page for click “SIGN IN” button. (Normally uses window.scrollTo JS method) but didn’t enter popup page.
Why do you need to sign in? The search results are available without the need to sign in, at least on cars.com
Besides that, if you set the max number of results per page to 100 in the URL, why do you need to scroll down? The shared workflow extracts the whole (!) page so I don’t see a need for scrolling.
The JS shared is usually used when you have endless scrolling pages like reddit, Facebook etc
Also, I do not understand why you want to connect 2 workflows.