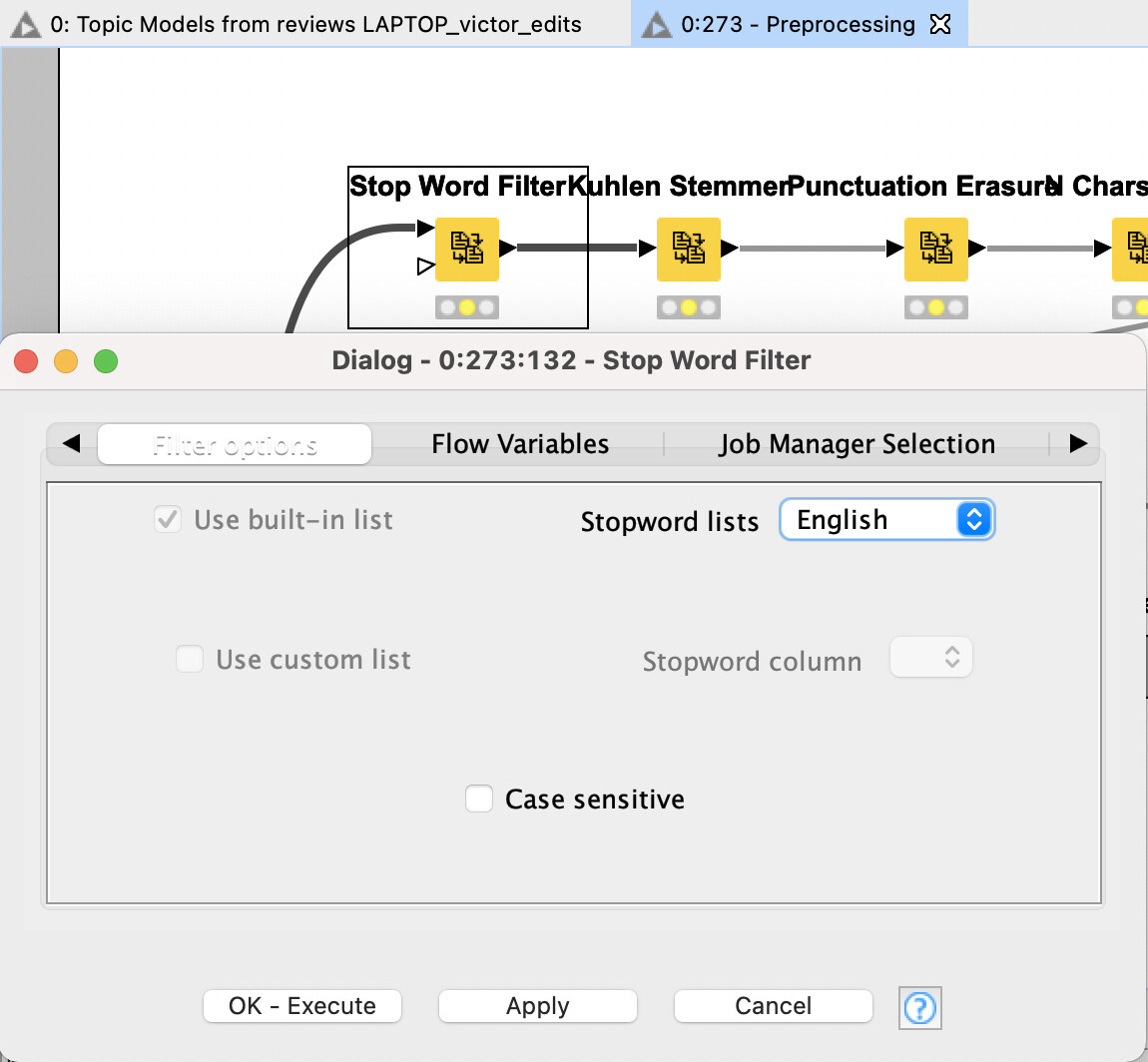
Hi @Jalvear,
In the workflow I shared I don’t think there are language dependent nodes except the Stop Word Filter within the Preprocessing component. You can change the language there to be Spanish.
Hi @Jalvear,
In the workflow I shared I don’t think there are language dependent nodes except the Stop Word Filter within the Preprocessing component. You can change the language there to be Spanish.