This week, our challenge explores what features matter the most for wine quality , using regression and feature selection as the backbone techniques . This is a challenge that will put you thinking for sure!
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-9 .
Need help with tags? To add tag JKISeason2-9 to your workflow, go to the description panel on the right in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
As a french KNIME user I couldn’t miss the challenge this week !
I have tried several options, with AutoML and other components, but it was too close of what has already been proposed here so I wanted to change the possible points of view on this problem and bring something more to the discussions. Feel free to answer, discuss or add comments or remarks to any of these points :
I have considered this was a classification problem, instead of a regression one (since it involves rating, so numerical ordinal target), but both options seem acceptable (will perhaps try the regression case just for fun and see how it differs from the classification one).
When dealing with Machine Learning algorithms, I often see workflows where overfitting (because of improper data split) or data leakage (because of exploratory data analysis done on the whole dataset, or any preprocessing steps done on the whole dataset) occur.
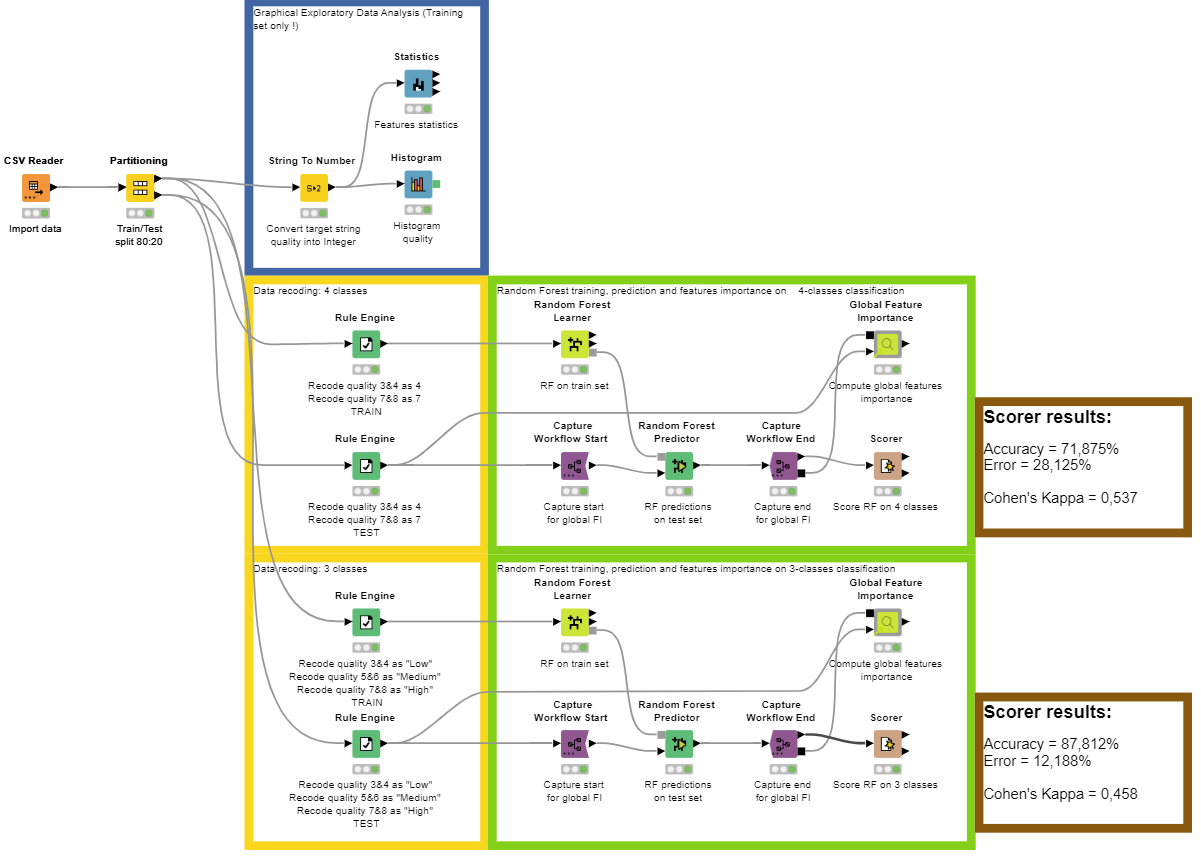
I wanted to propose a workflow that should assess fairly the performances of a classification algorithm : Train and Test set are separated just at the beginning, and steps done on the training of the model are only done with the train set. The Exploratory Data Analysis is done only on the training set. Since I used a tree-based method and since the dataset is pretty clean, there are no need for transforming the variable or advanced preprocessing steps for outliers analysis or missing values imputation. If it was needed, it would have been fit on the training set, then apply on the test set, to avoid data/information leakage. As I’m using Random Forest, the bootstrapping process already enable an implicit validation and prevent overfitting with Out-Of-Bag samples. I also tried XGBoost and other boosted algorithms, but performances were lower ; it seems normal as the data can be quite noisy if the ratings come from human labelling.
Since I am dealing with a classification problem and the classes are not well balanced, there are two versions possible in my workflow :
One with 4 rating classes (4, 5, 6 and 7): class 7 and 8 are combined, as well as 3 and 4 to have sufficient sample size and avoid having too much “dispersion”.
One with 3 rating classes (Low, Medium, High): class 7 and 8 are combined as “High”, 3 and 4 as “Low” and 5 and 6 as “Medium”.
What I wanted to highlight with the comparison of the two class possibilities here is the fact that the more class there are to predict, the more difficult it is for an algorithm to find the classification rules (in general). Here, looking at the comparative results from the two scorers, we can see less classification errors in the case of 3 classes compared to 4 classes.
My solution is less oriented towards algorithms optimization, but more on the understanding of the use case and possible different interpretations on how to deal with the data. Other domain experts, users, data scientists/analysts may have different views on this, and the difference in results is often more a question of how people deal with the inputs, rather than the algorithm (and optimization) chosen.
Here is how the workflow looks like (quite simple) :
Hello everyone, this is my solution.
I referenced to Knime’s solution and found that it is more reasonable to transform the quality label into a binary label. The reason is that if it is a segmented label, the distribution of labels is unbalanced; If it is a binary label, there is no such issue. thank you.
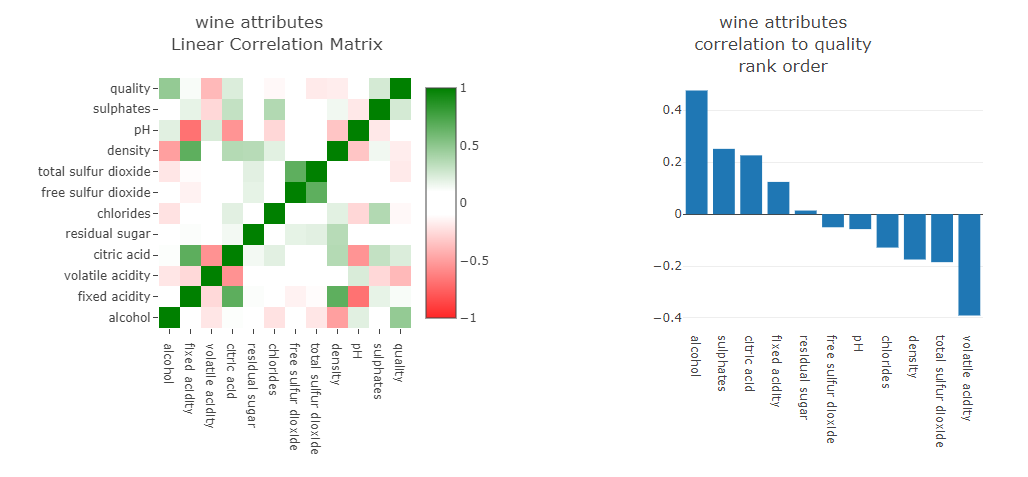
Hi all - back from a small hiatus. Here is my solution. I went with a linear correlation node to determine which attributes had the most impact on quality and my custom plotly correlation matrix view for dataviz and a plotly bar graph for displaying rank-order of attribute correlation.
My result differs from previous posts; but please don’t take it as an starting argue, as I’m not really an expert working with ML algorithms. This result is more related to the data pre-processing I did.
This is something already discussed in JKI S2 Challenge 5 when confronting quality vs pollution… they have negative correlation coefficient because of opposite meaning; but it doesn’t mean that coefficient of determination has to be negligible.
Then I pre-processed all independent variables turning into negation form (this is: 1 - normalized value [0 to 1]), all those independent variables that presented negative Pearson’s vs dependent variable. Renaming them with the prefix ‘neg’.
In my result negation of density (lightness?) has become the second independent variable in importance to define quality. That in terms of wine quality makes some sense
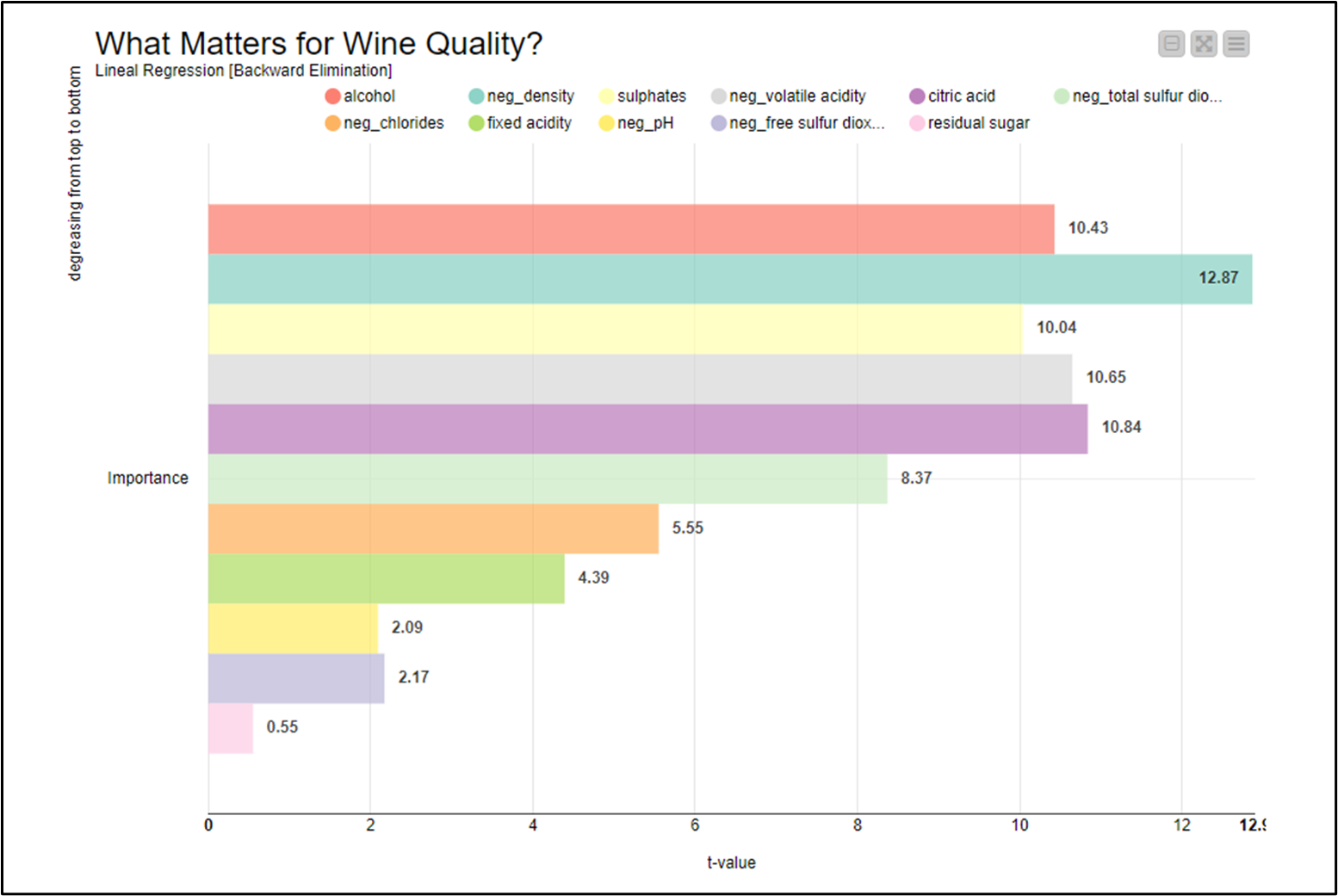
All along with what I’ve already exposed; I’m not considering the challenge 09 as a predicting exercise. I’ve interpreted ‘Importance’ as a ranking of all independent variables in terms of significance degree related to a multiple lineal regression model. So I ran a multiple linear regression backward elimination, without significance level restriction.
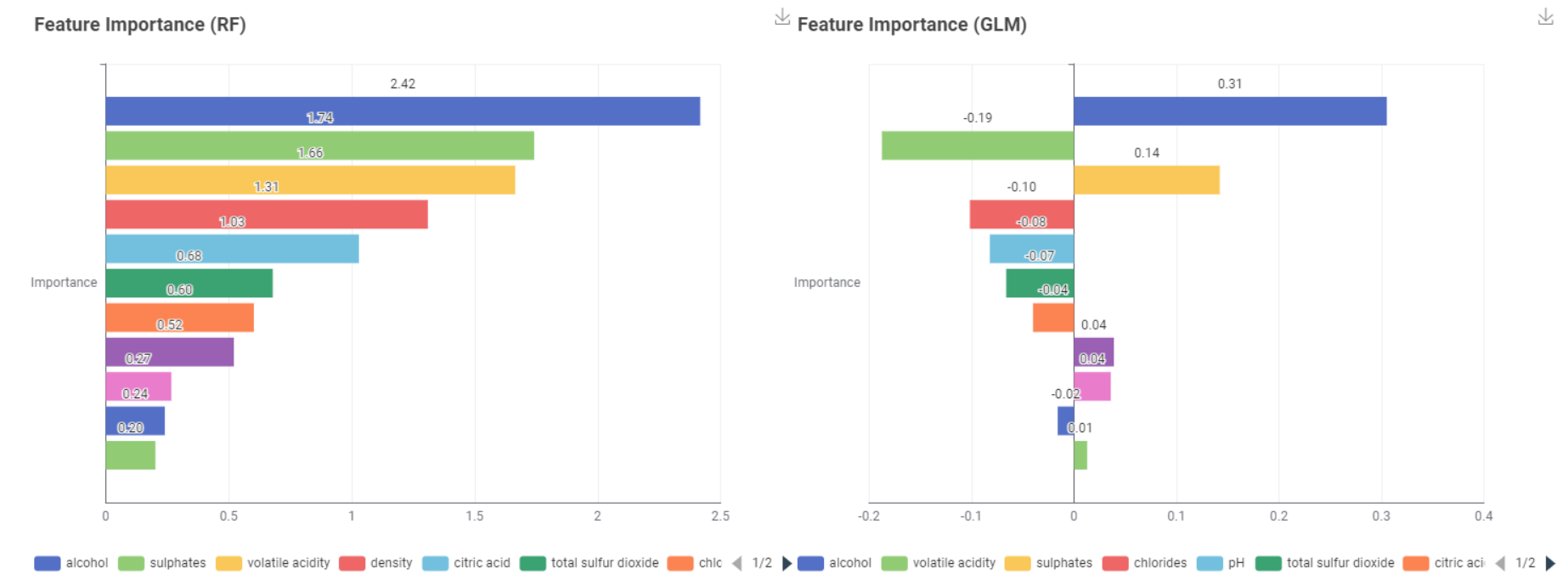
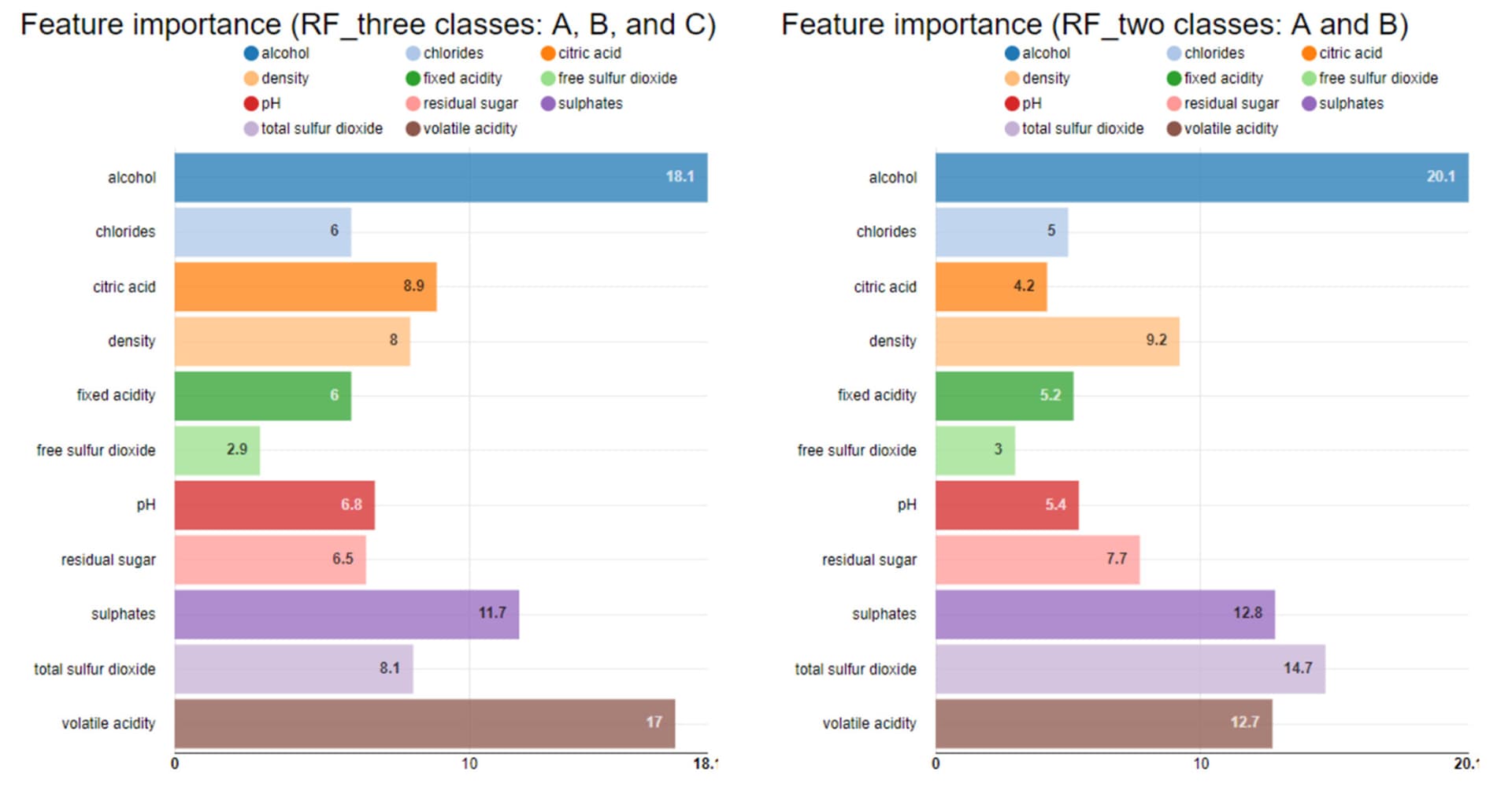
As other participants have already done, I classified “quality” into two or three categories. I compared the feature importance using a simple random forest. “Alcohol”, “sulphates” and “volatile acidity” appear to have relatively high scores in both models. Are “sulphates” a type of additive or preservative? If so, I guess they would have some influence on the overall quality.
As many other participants I recoded the labels to category, so I have been solving the classification problem. And as @Victor_G mentioned, the data set is extremely unbalanced, so I also worked with 2 cases (thank you for this idea): the original set of classes and reduced with 3 classes: low, medium, high.
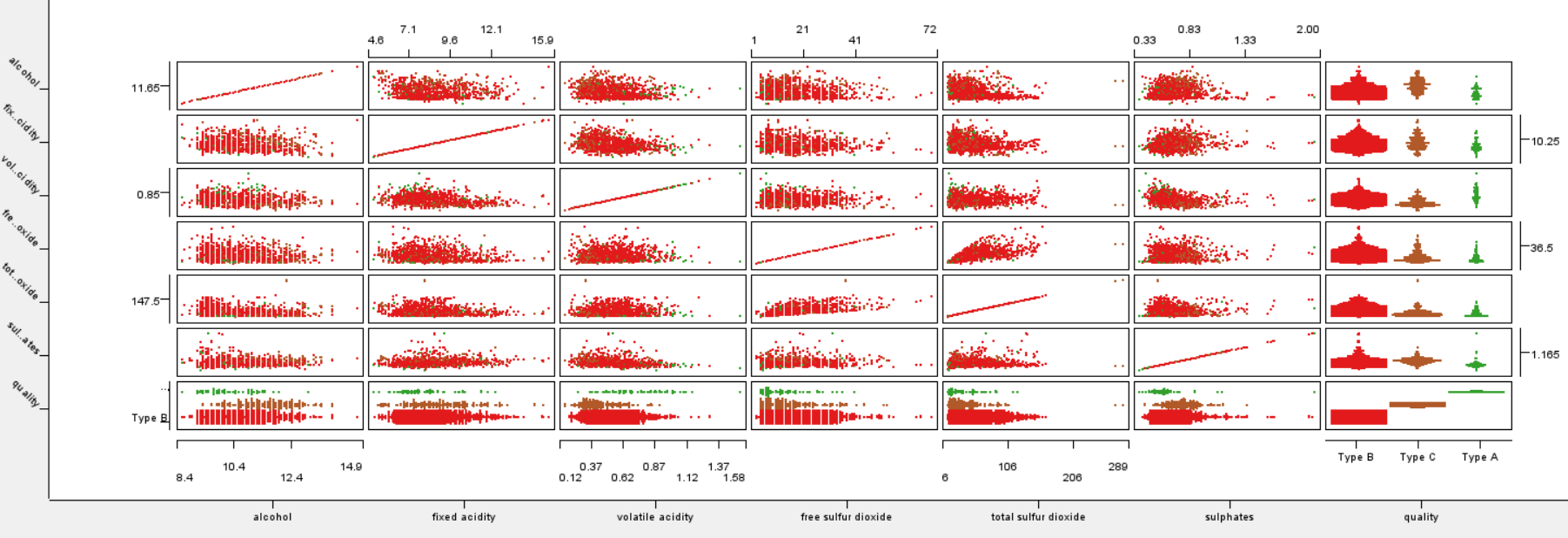
First I did correlation analysis which makes sense, since even in the feature names one can see that they are very close to each other - they are different types of the same measurements (acidities, sulfur dioxide measures). So I created a component that allows users to apply correlation analysis or go without it.
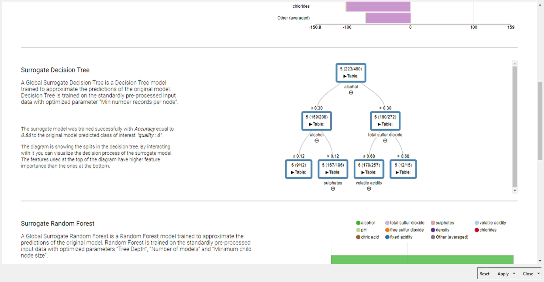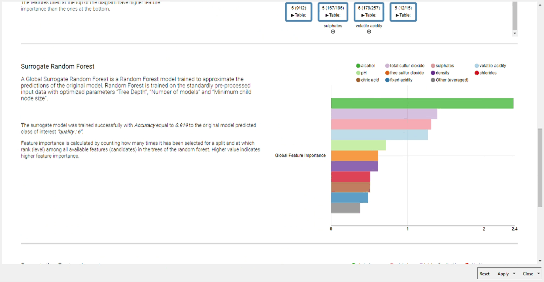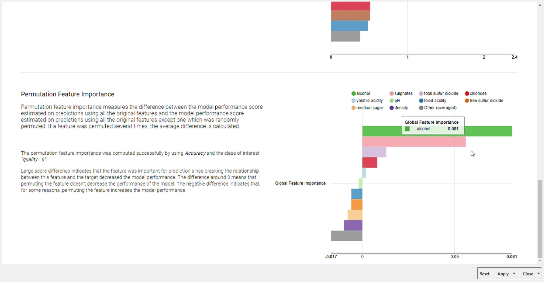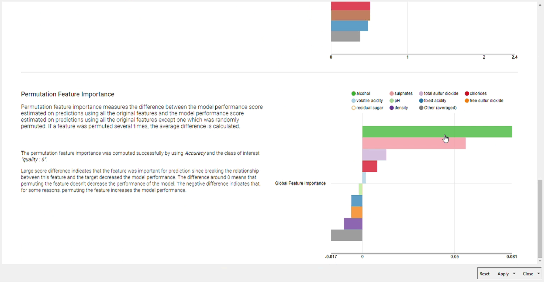
To start with feature analysis I tried with a straightforward counting the number of the splits candidates for Random Forest, which is in general a good approach. Then I found this wonderful component in this thread - “Global Feature Importance” which also does split analysis and much much more. Anyway it seems that for all cases - with/without feature correlation filtering, original set of labels / reduced set of labels, the selection of the desired class - the main set of features are pretty much the same: alcohol, volatile acidity and suphates.
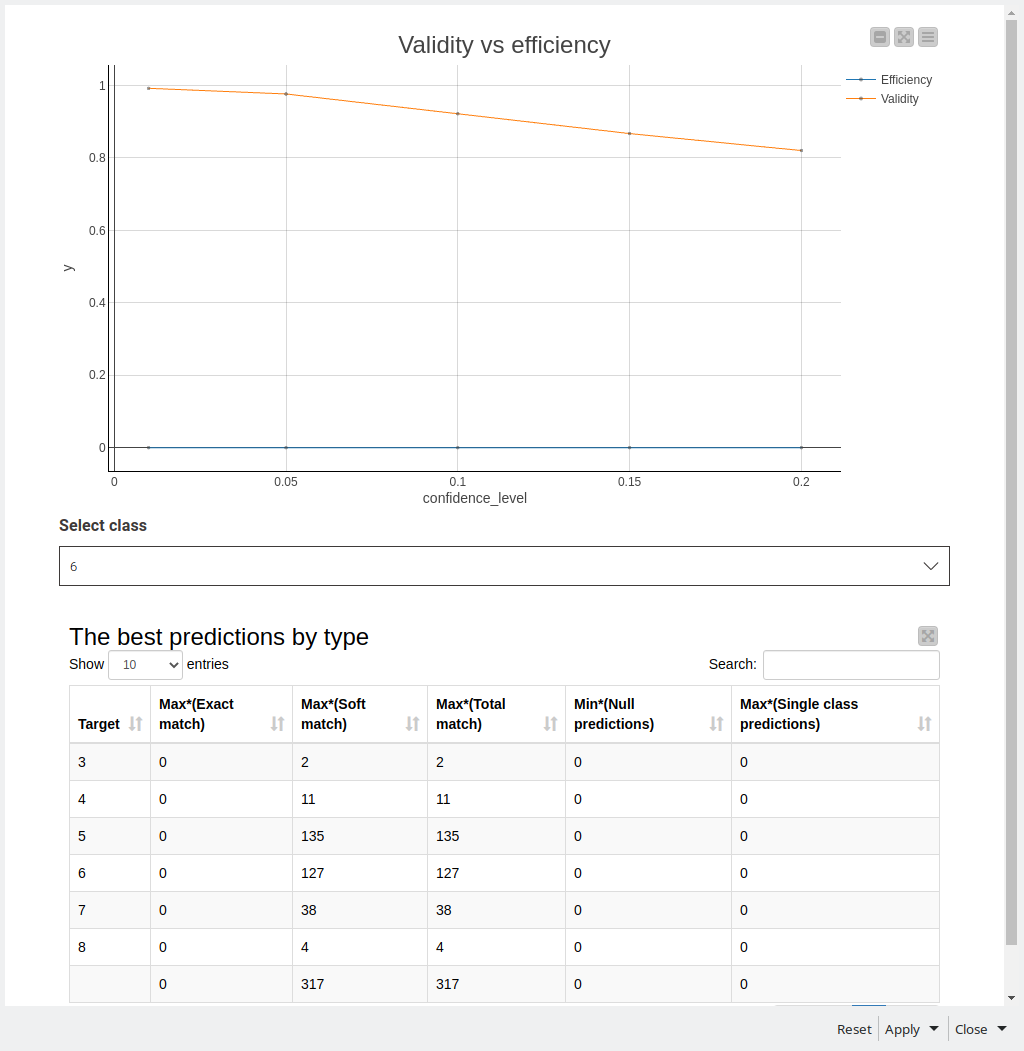
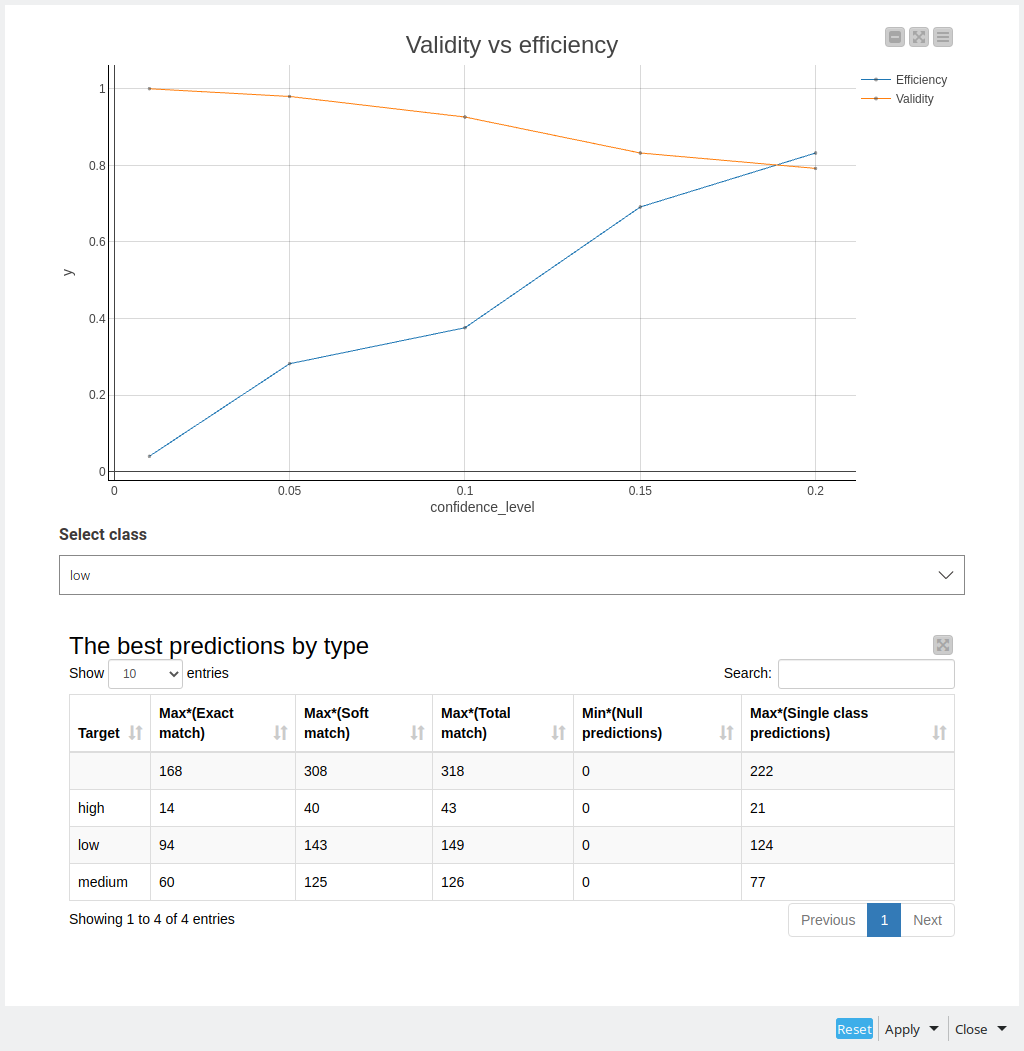
I also applied conformal prediction, however I could not apply it for feature importance analysis (at least for now), but it gave me a good overview regarding how hard it is to make the predictions, since for the original labels I always got the prediction sets with at least 2 classes. The situation got better for the reduced labels set problem, and it is possible to see the examples of “golden” representatives for each class. Still comparing validity vs efficiency showed up quite bad results for the problem with original classes.
Honestly, I find this question quite challenging due to two main factors. Firstly, there is an imbalance in the data which makes it difficult to improve accuracy. Secondly, interpreting feature importance is also a challenge, even though the task only requires us to display feature importance in order.
I believe this is a regression problem rather than a classification problem. While the quality scores in the dataset are integers, they have different sizes. If we use regression and the true quality of the wine is 6, a prediction of 5 would not be too far off. However, if we approach it as a classification problem, both a prediction of 5 and a prediction of 2 would be considered incorrect. Although they may not seem vastly different, they actually have significant distinctions.
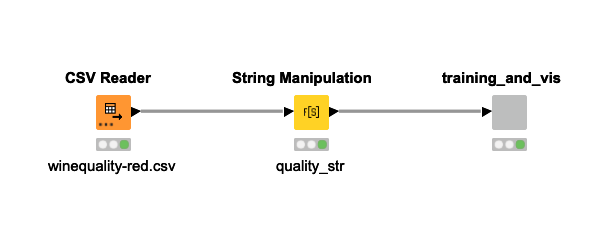
I generated a string variable called ‘quality_str’ and used it for sampling. Then, I inputted it into the “H2O Random Forest Learner (Regression)” to obtain the result.
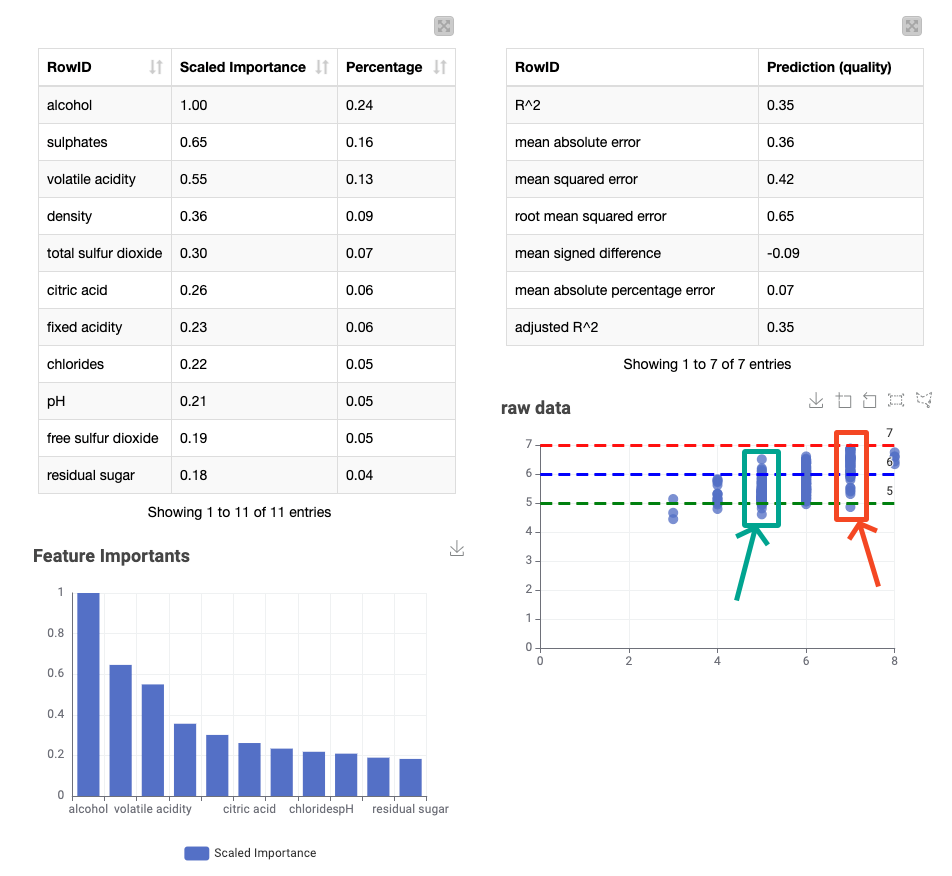
The visualization of the prediction data at the end is noteworthy. The horizontal axis represents the actual values, while the vertical axis represents the predicted values. Notably, the predicted result is slightly skewed towards 6 when the actual value is 5, as shown in the green box. Similarly, the value that is actually 7 is also biased towards 6, as shown in the red box. A potential solution to this issue could be an increase in features, but no such attempt was made.
Regarding the interpretability of machine learning, there isn’t much time to address this challenge this week. It’s a pity.
Exceptionally a little earlier this week, here’s our solution to the latest Just KNIME It! challenge!
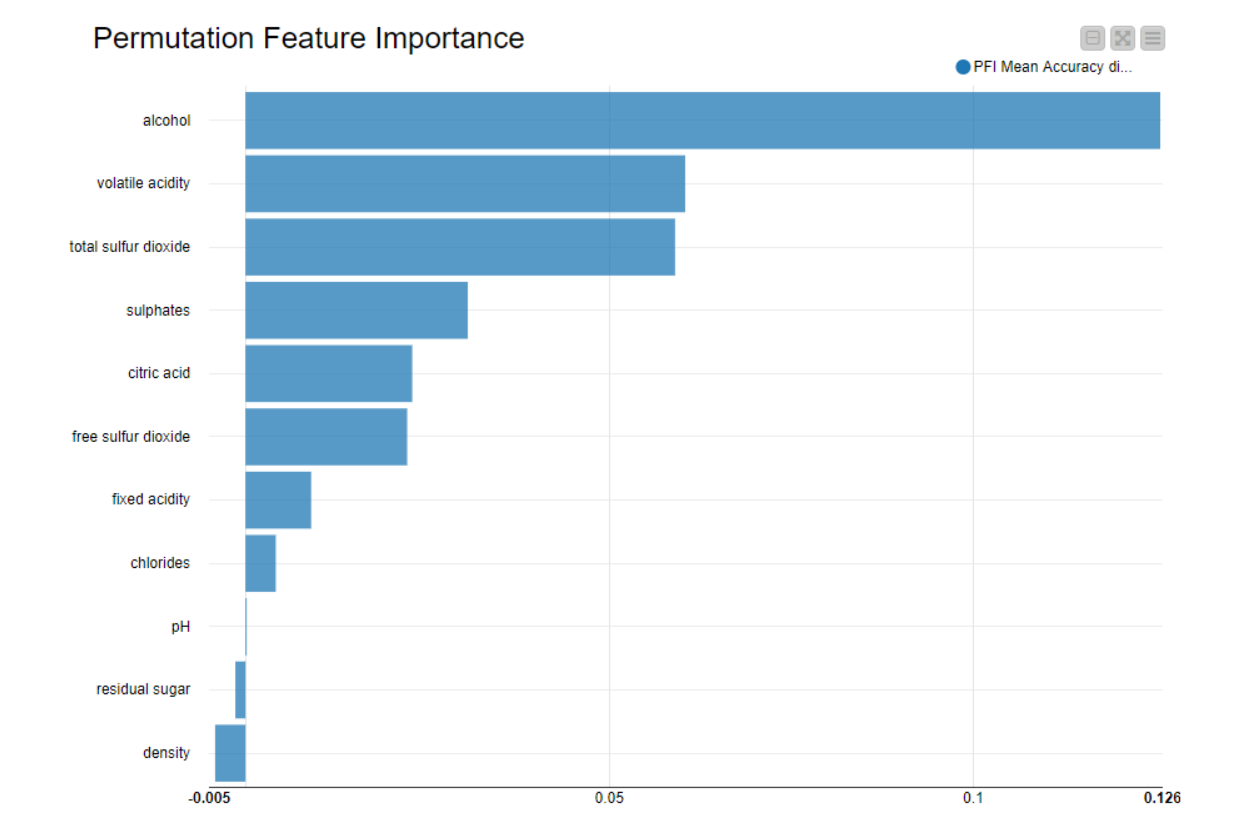
With our methodology, alcohol content seemed to be the most important feature in determining the quality of wine We are again very impressed with the variety and depth of your solutions, and can’t wait to see what you will prepare for our next challenge!
I’m a bit late, but here is my solution to challenge 9:
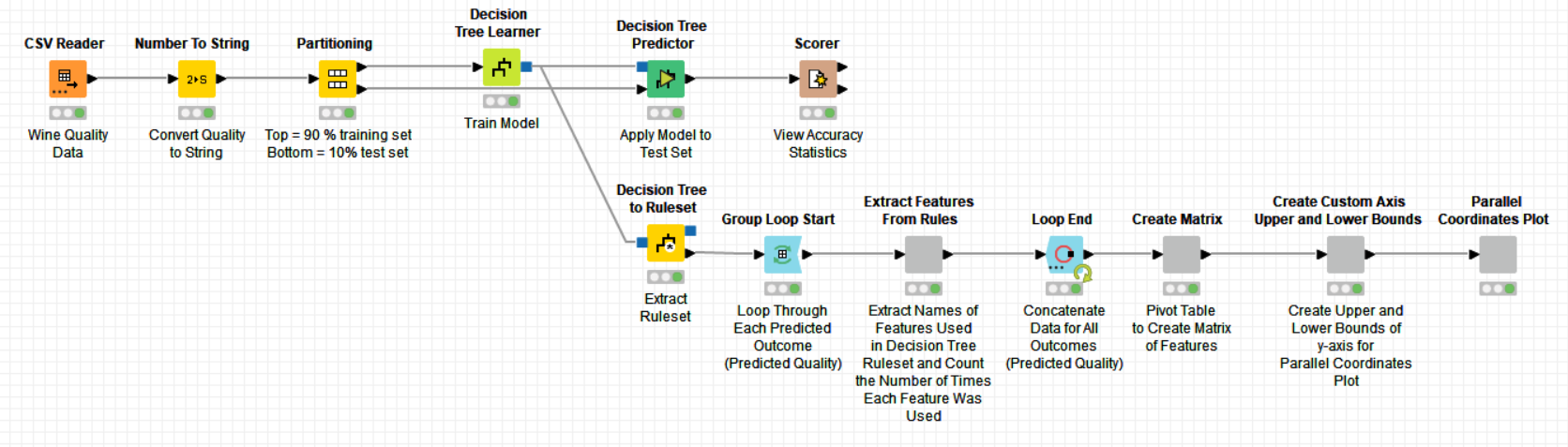
I have taken the simple approach of using the -Decision Tree Learner- and -Decision Tree Predictor- nodes and treating the challenge as a classification problem.
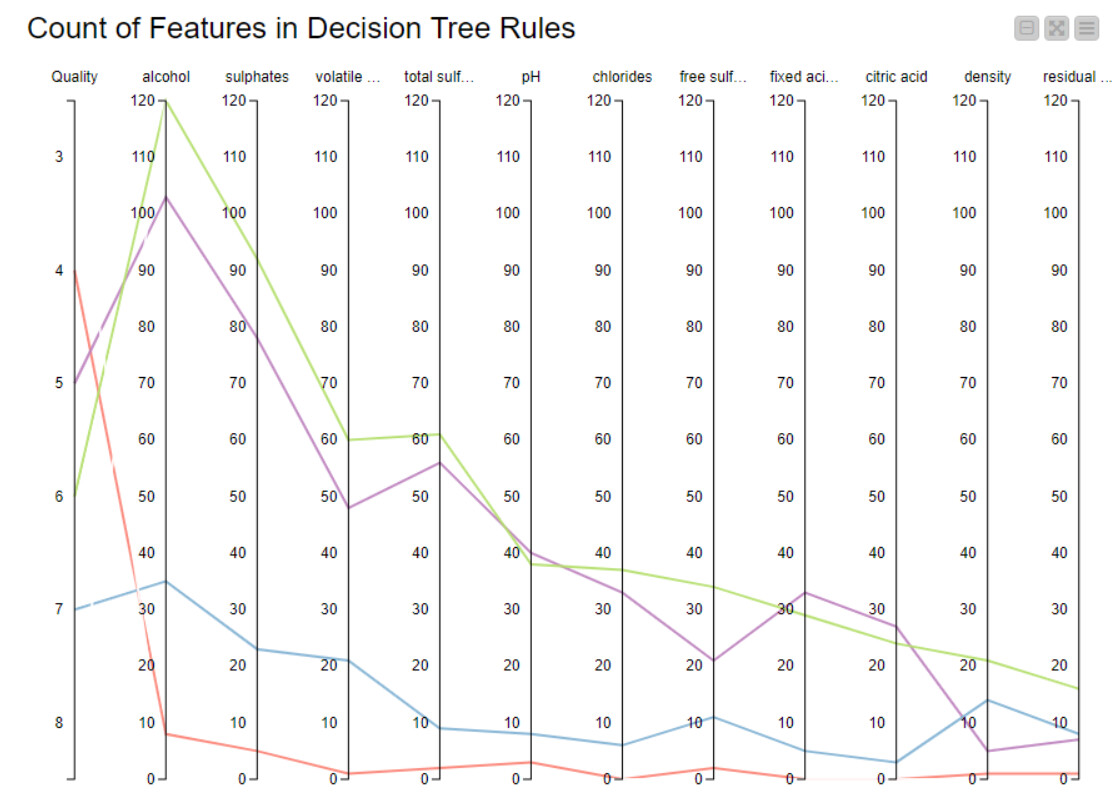
I have used the -Decision Tree to Ruleset- node to extract the rules and then used a Group Loop to loop through each predicted quality value (4-7) and count the number of times a feature is present in the quality rule set.
This led me to being able to present the results as a -Parallel Coordinates Plot-
As in the solution presented by Aline, the most important feature is the Alcohol content followed by Sulphates. It is apparent that only the first 3/4 features have any importance in determining the Quality of the wine and the other features can be ignored.