Hello JKIers
This is my take to the JKI S02 CH09.
My result differs from previous posts; but please don’t take it as an starting argue, as I’m not really an expert working with ML algorithms. This result is more related to the data pre-processing I did.
This is something already discussed in JKI S2 Challenge 5 when confronting quality vs pollution… they have negative correlation coefficient because of opposite meaning; but it doesn’t mean that coefficient of determination has to be negligible.
Then I pre-processed all independent variables turning into negation form (this is: 1 - normalized value [0 to 1]), all those independent variables that presented negative Pearson’s vs dependent variable. Renaming them with the prefix ‘neg’.
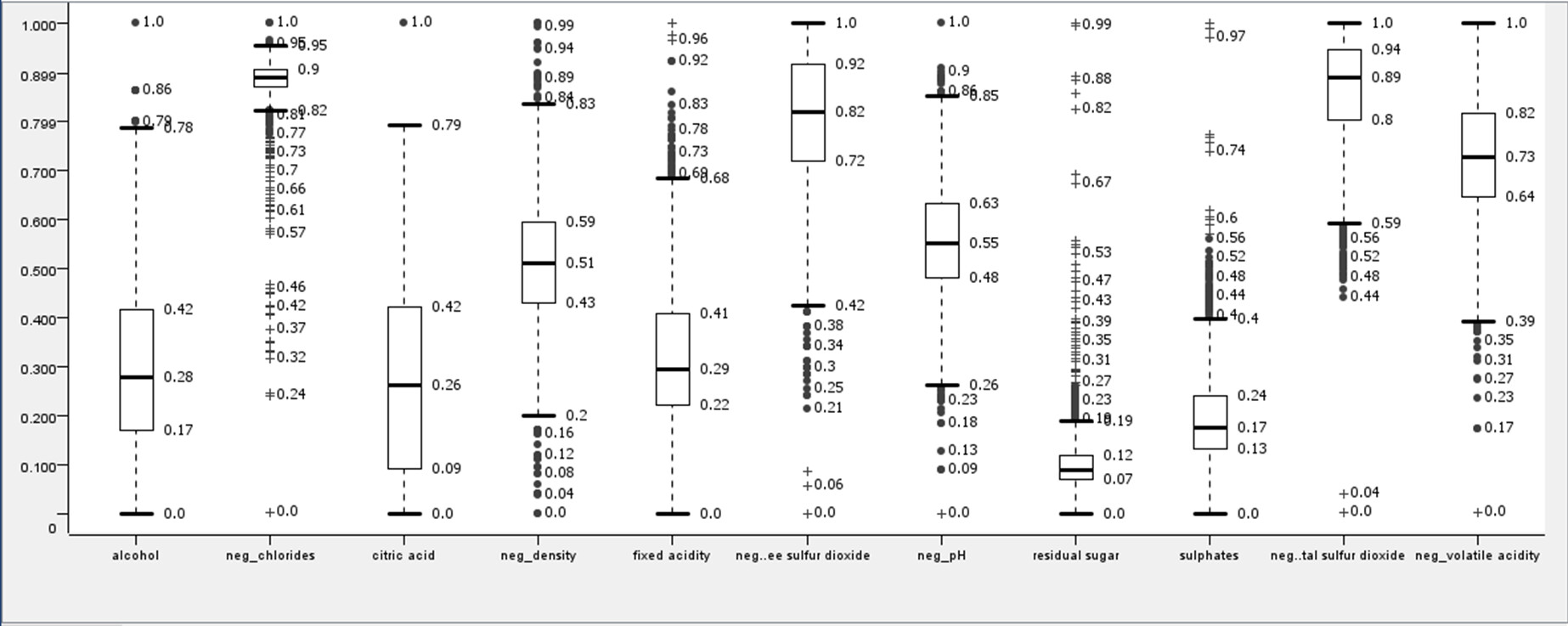
In my result negation of density (lightness?) has become the second independent variable in importance to define quality. That in terms of wine quality makes some sense ![]()
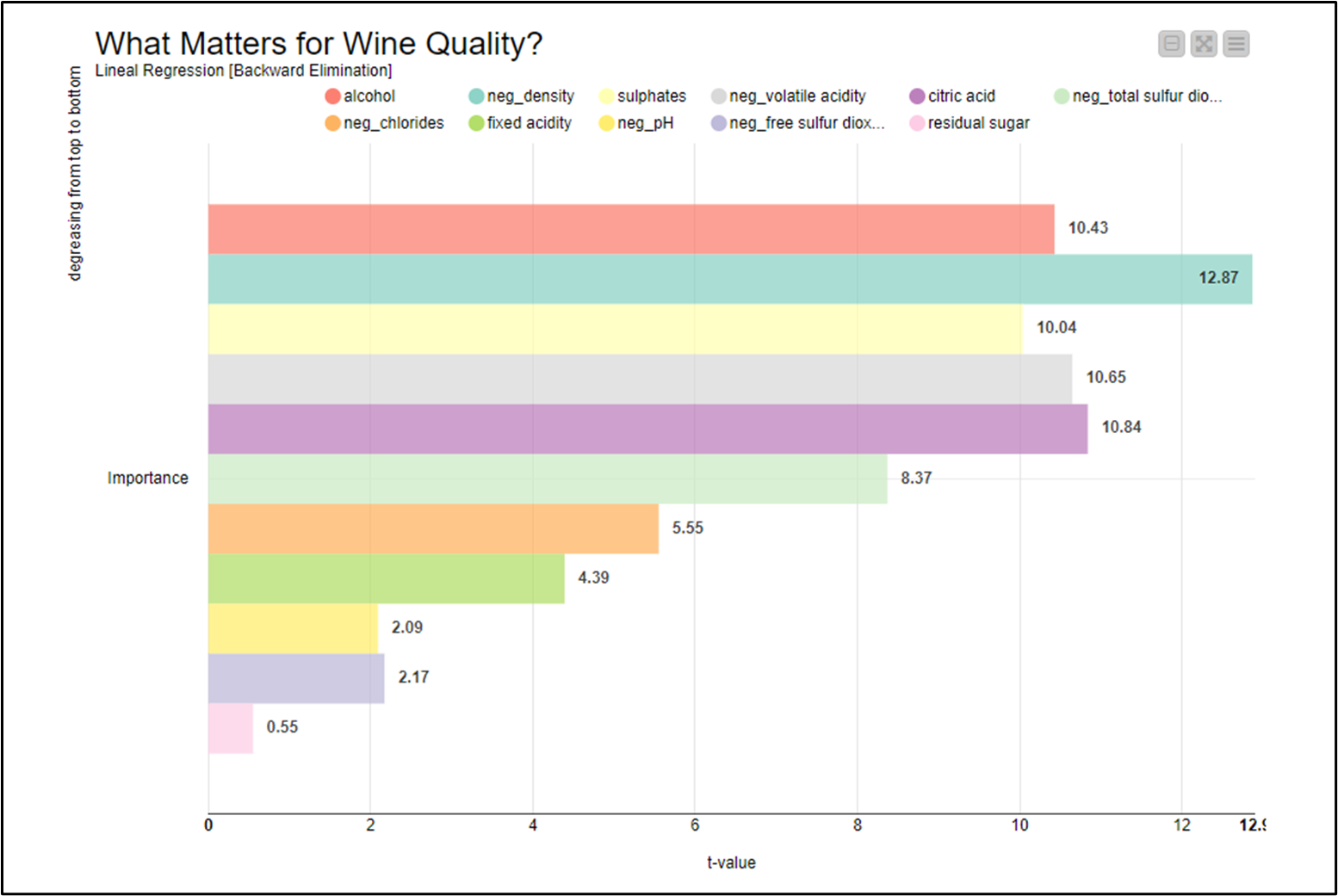
All along with what I’ve already exposed; I’m not considering the challenge 09 as a predicting exercise. I’ve interpreted ‘Importance’ as a ranking of all independent variables in terms of significance degree related to a multiple lineal regression model. So I ran a multiple linear regression backward elimination, without significance level restriction.
Happy KNIMEing