Have an idea for a challenge? We’d love to hear it! Please write it here .
And remember: the more you participate, the more participation badges you may end up getting. Fancy, huh? Just remember to correctly mark your solution in the Hub with tag justknimeit-17.
Hi everyone,
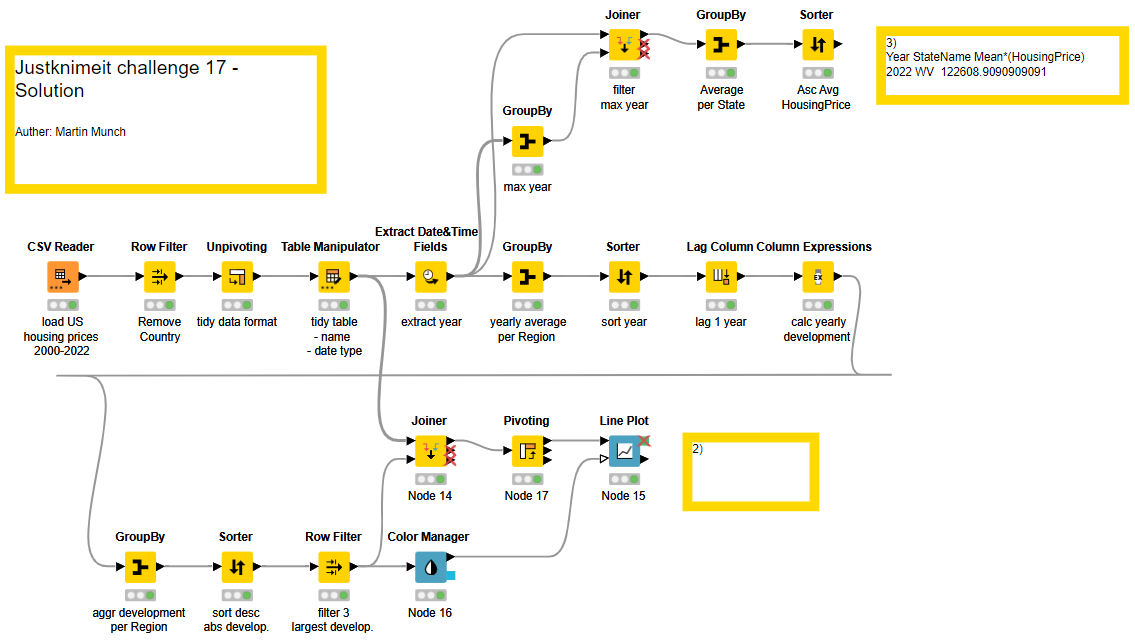
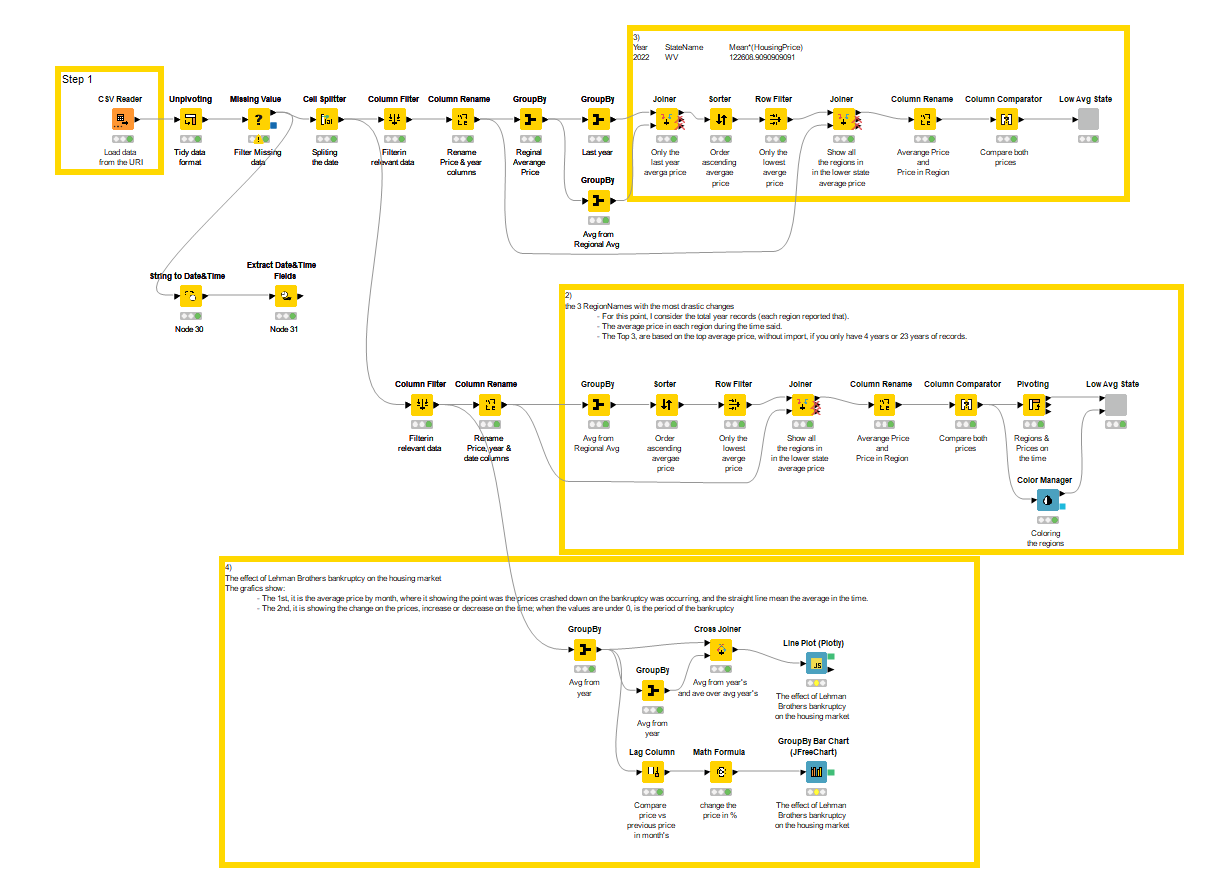
Here is my solution.
No CSV reader (just for testing purposes)
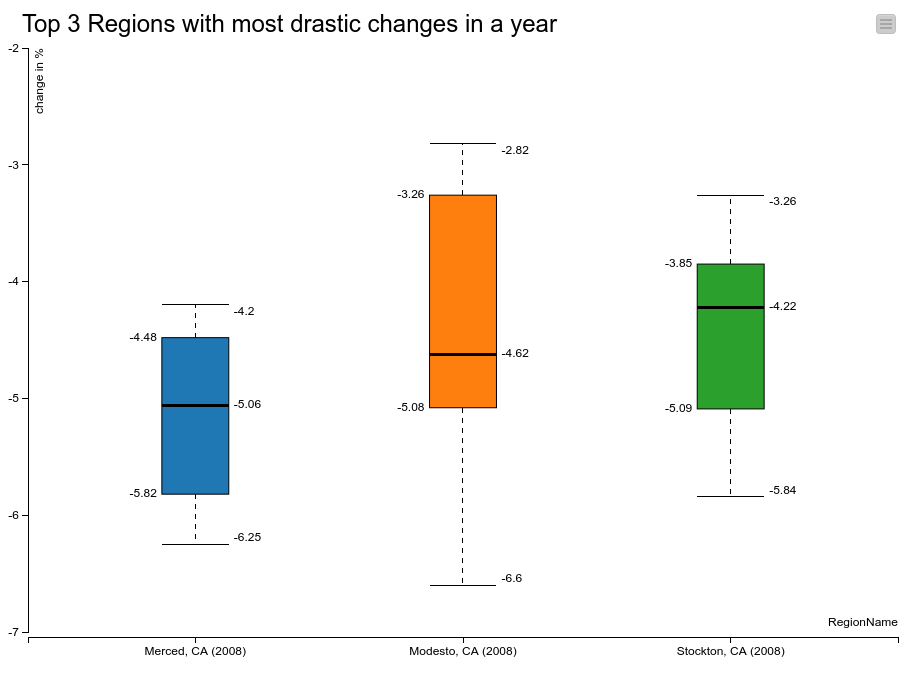
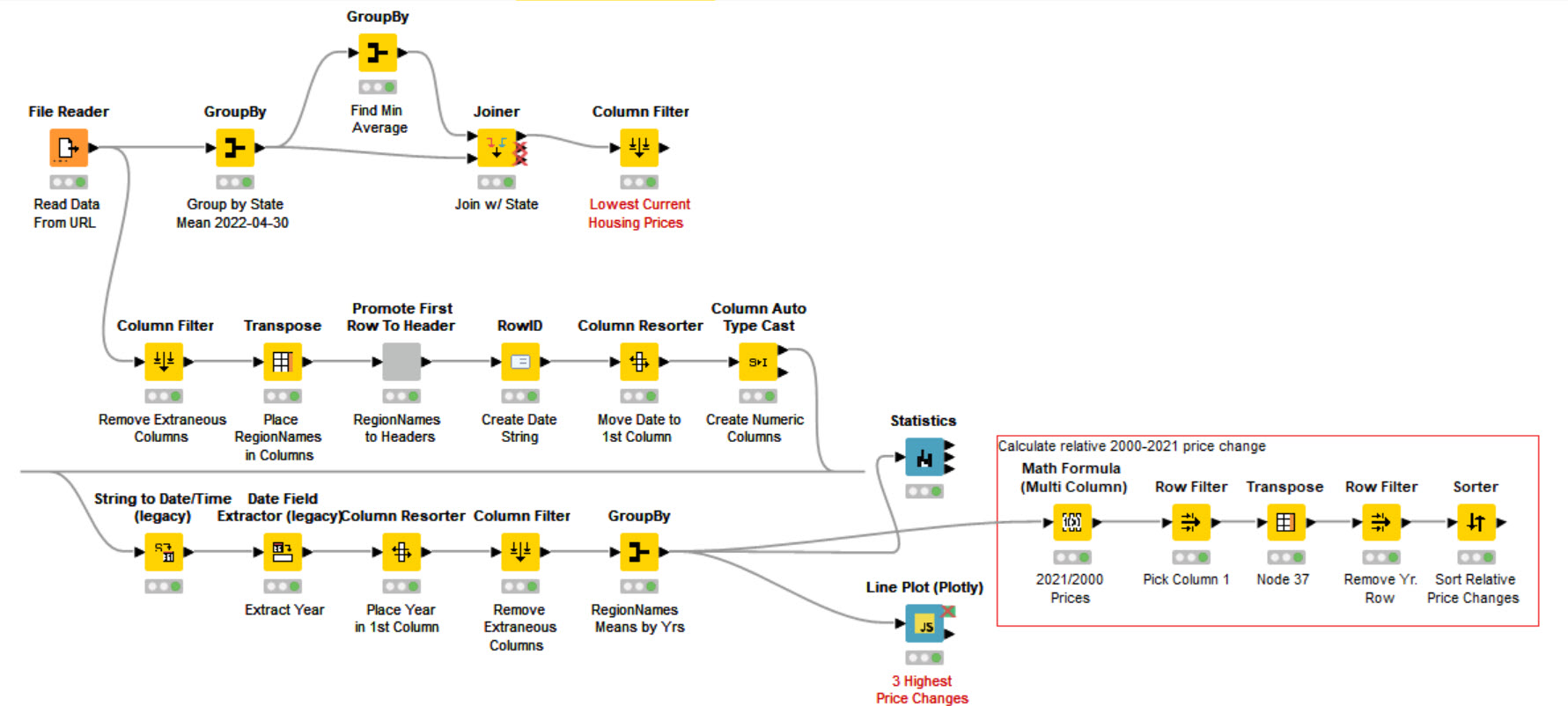
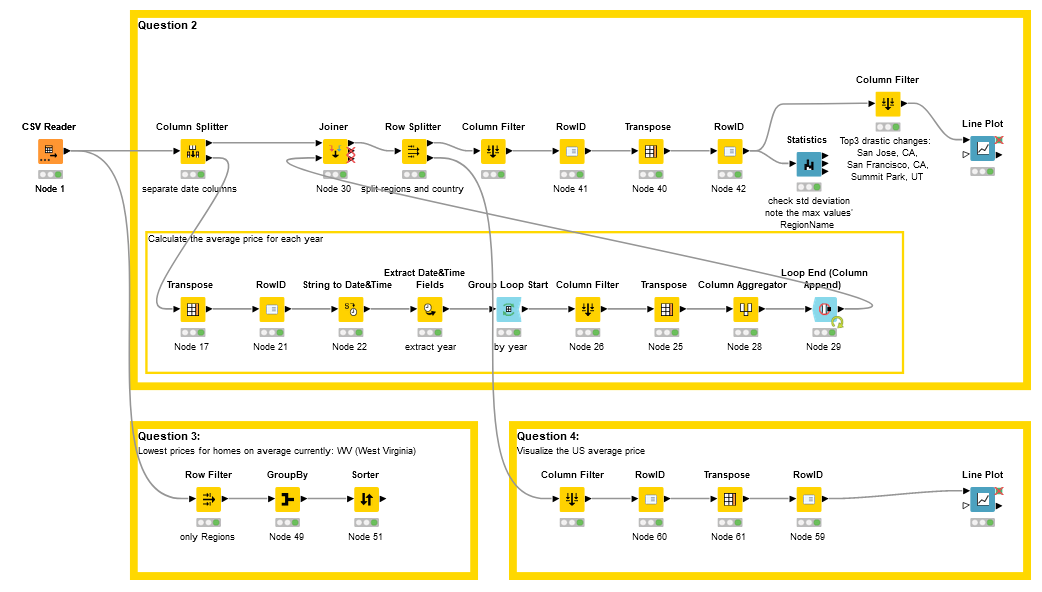
I calculate yearly average values and overall variance for drastic changes.
I did not use loops but intended to do so.
Should have use Table Manipulator
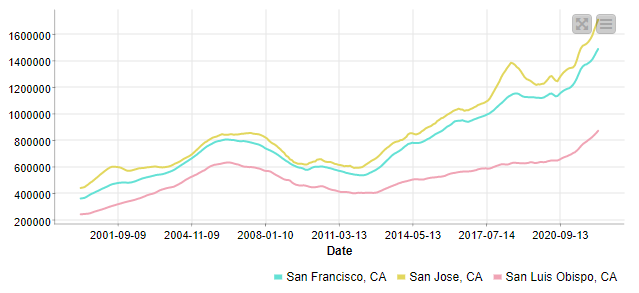
Here’s my solution. I used the three highest relative price changes from 2000-2021. The results are somewhat counterintuitive. I added San Fransisco for comparison to a high absolute change. The workflow is in a Dropbox link.
Here’s my solution.
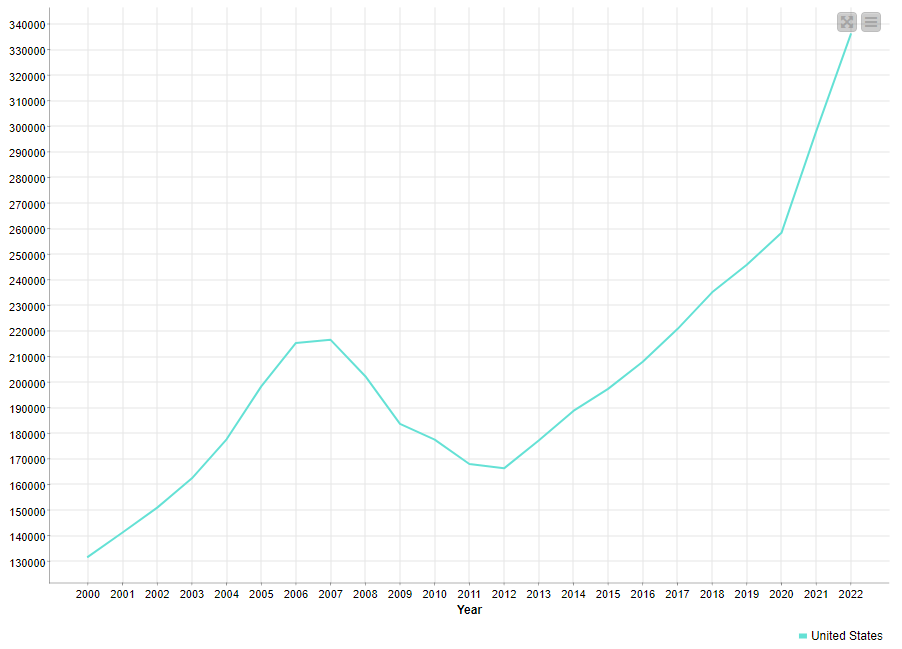
Q2:
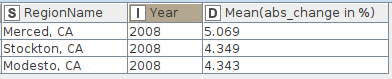
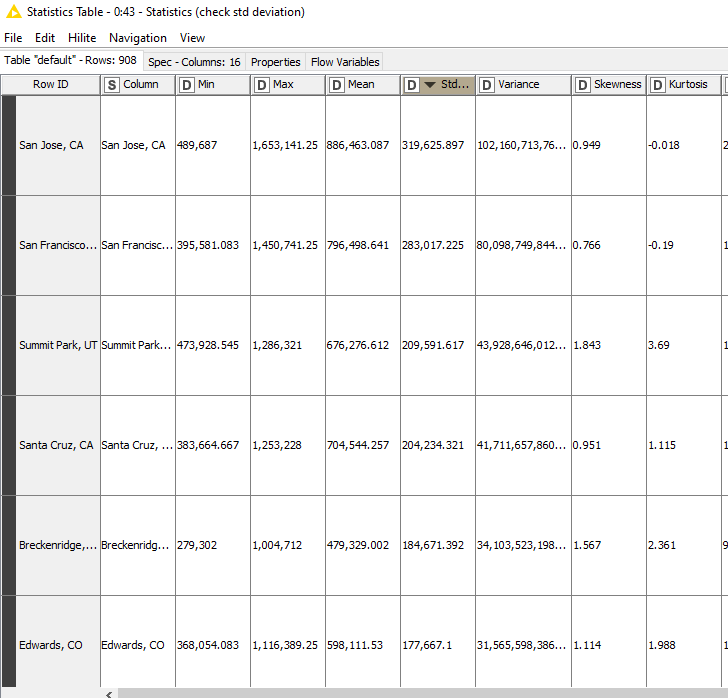
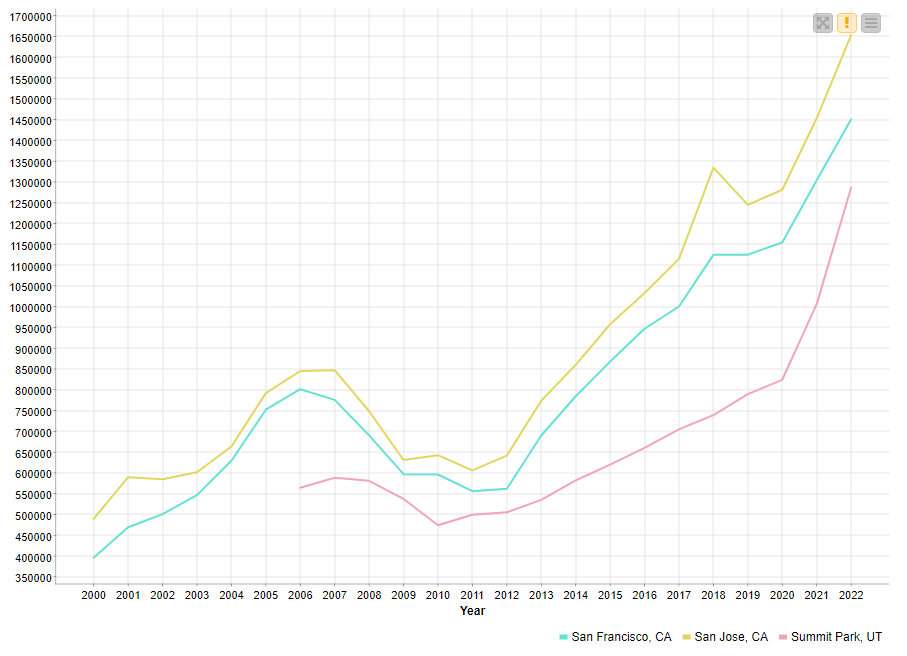
From the statistics, we see that San Jose, CA, San Francisco, CA, and Summit Park, UT have the biggest standard deviation by year:
Hello guys !
A little late to the game but I didn’t want to miss this opportunity on data visualizations !
Here goes my submission for the challenge. It was nice to see different approaches and results.
Despite I’m trying to catch up with the challenges, once again enjoyed the take on it.
Aiming to simplify the analytical approach, I just filtered the dataset for the closing year prices (this is filtering by including only December months); some more work could be done to reduce the gaps…
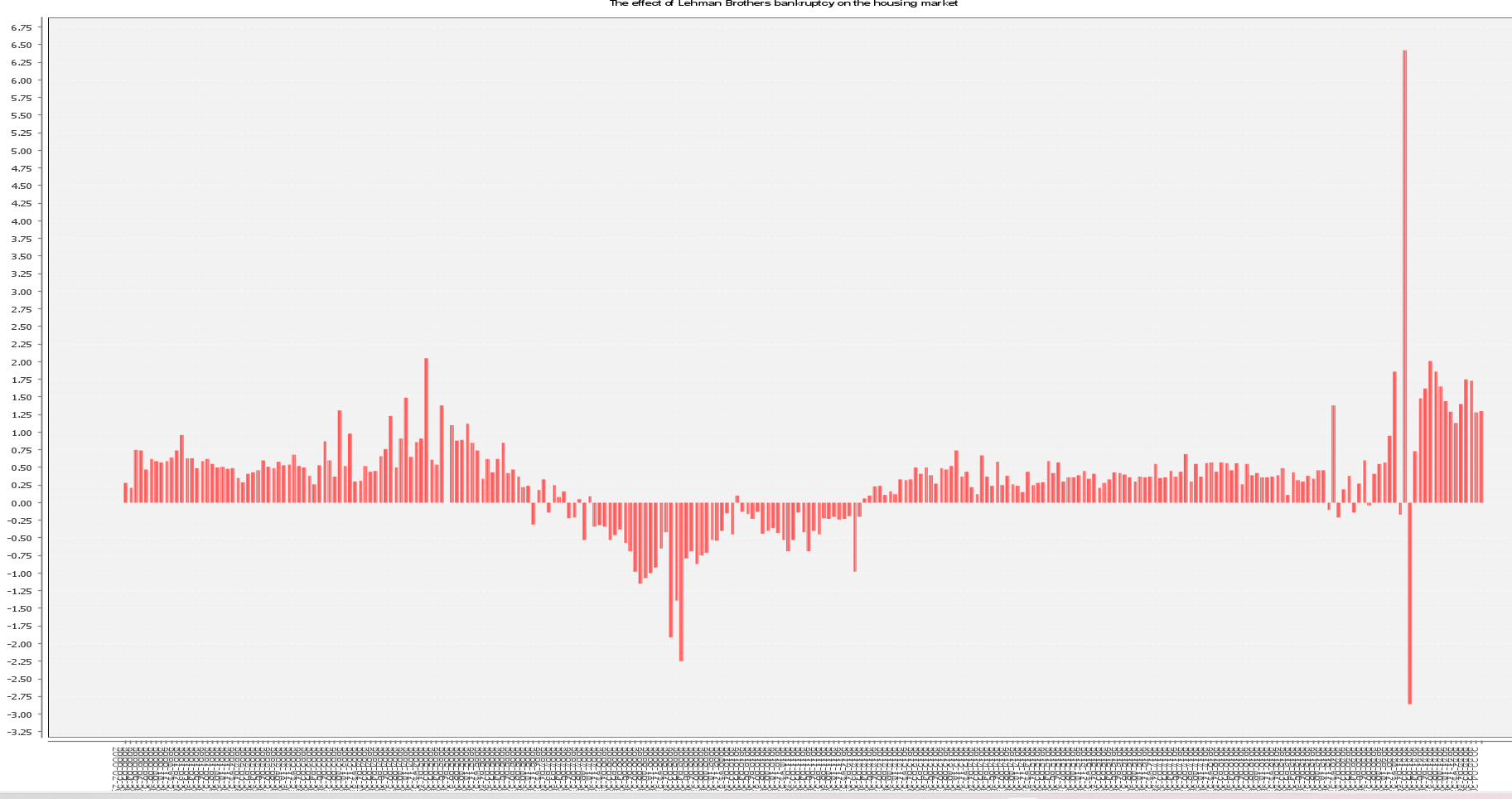
Afterwards to normalize observations avoiding pricing bias, I computed the yearly variation (from previous year) in percentage.
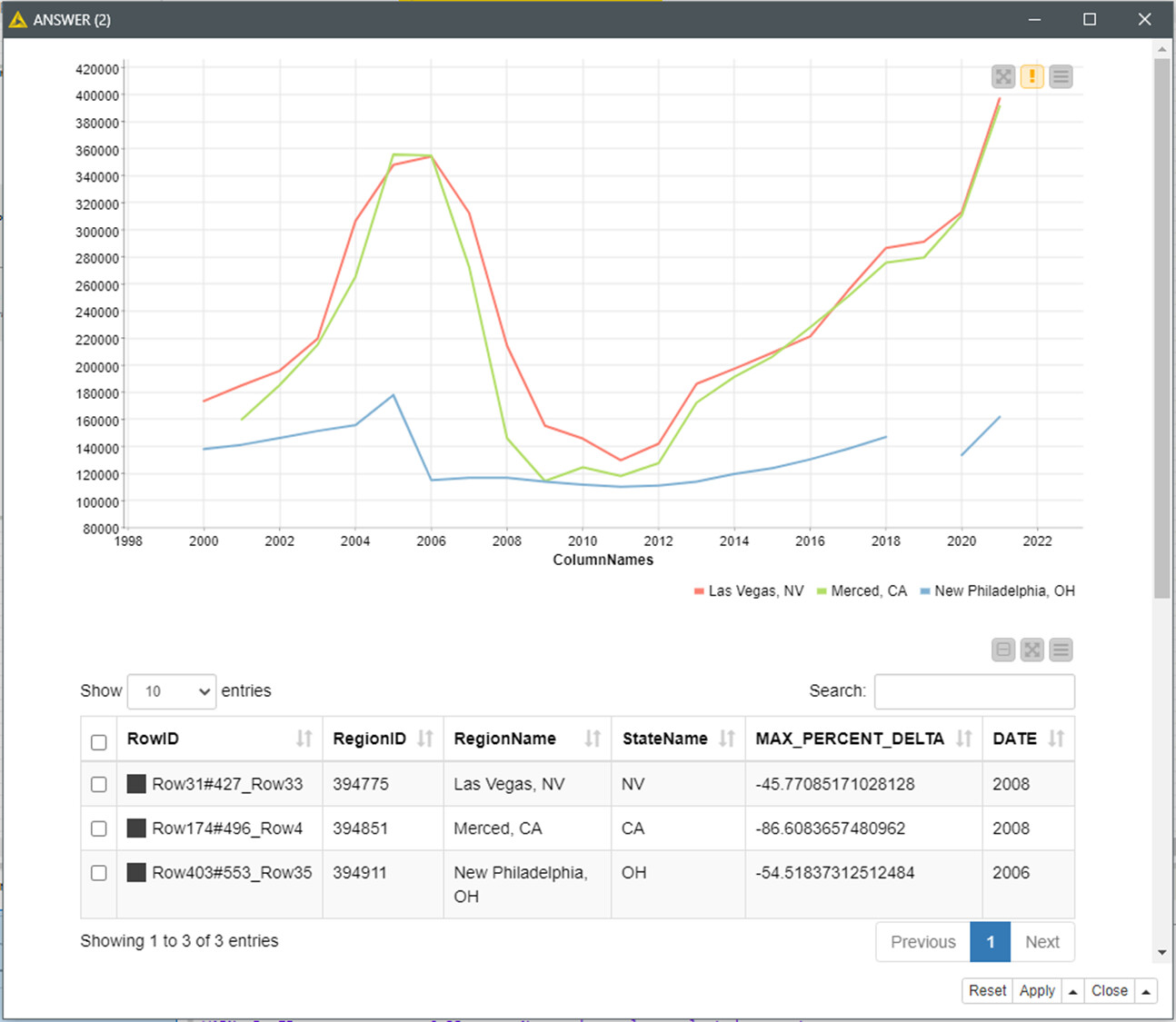
Q2.- The initial Max. variations gave me a bored answer with similar behavior of three California Regions. Then I confronted the Max. variation champion from the different States, displaying some more flavour for the different State ways.
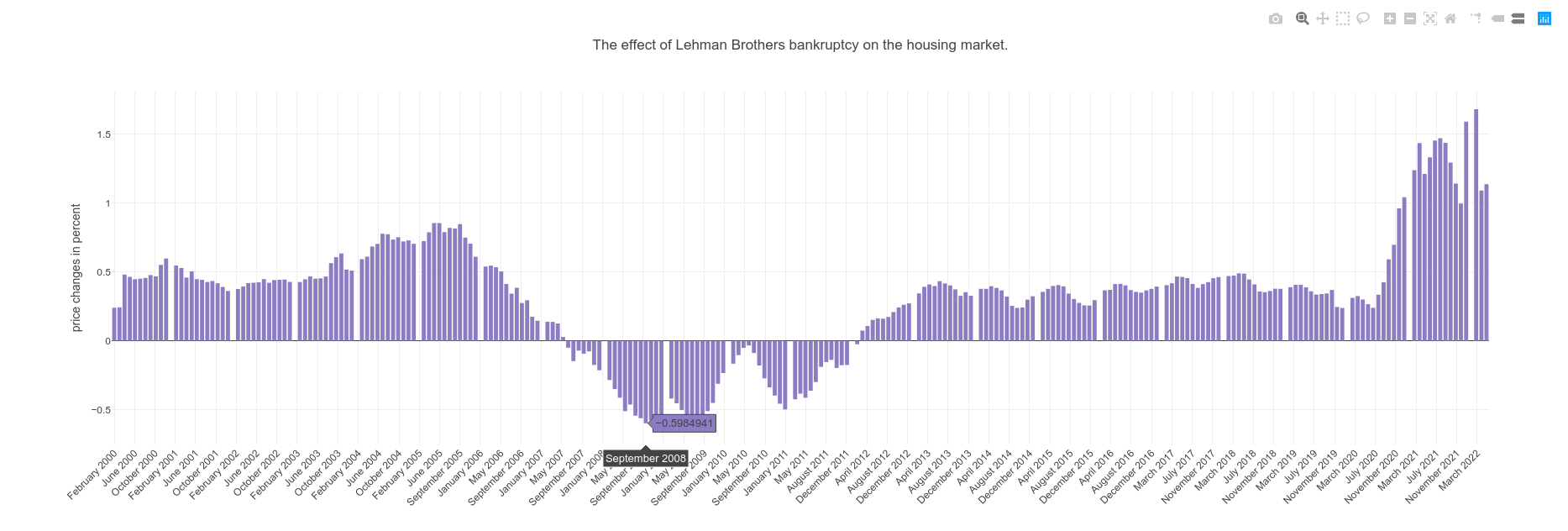
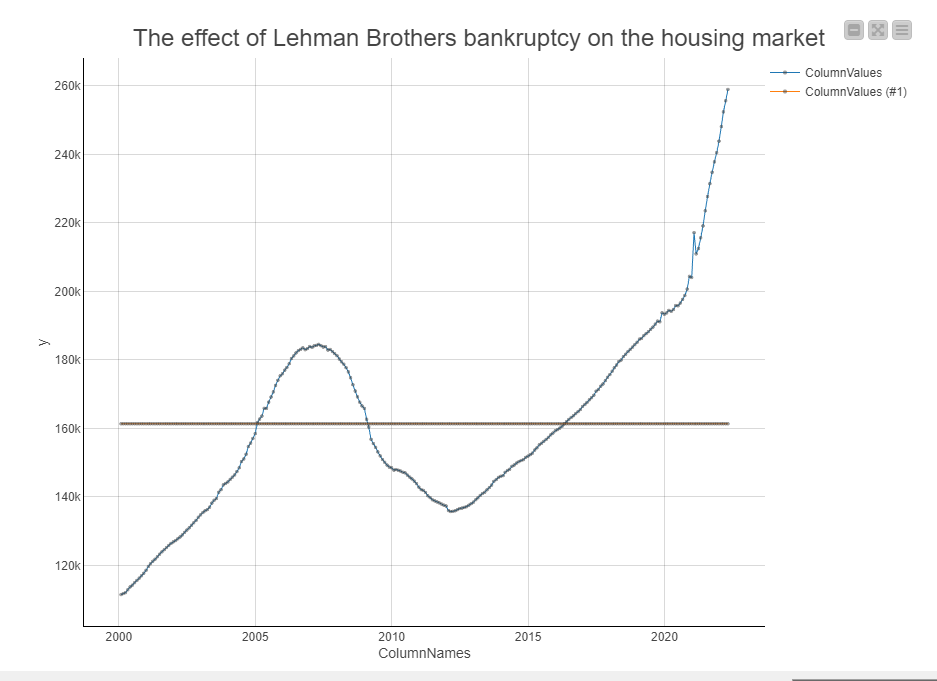
New Philadelphia OH (in blue) was strongly affected by the the 2003–2006 house price boom and subsequent collapse already in 2006, but didn’t noticed the LB’s bankruptcy in 2008; probably due to the lower housing prices (see the map in Q3).
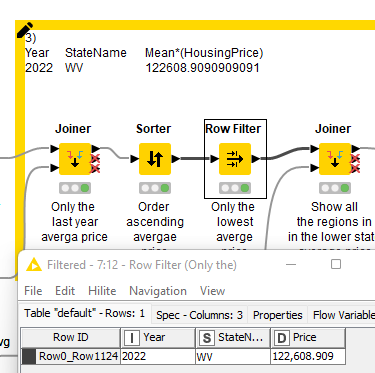
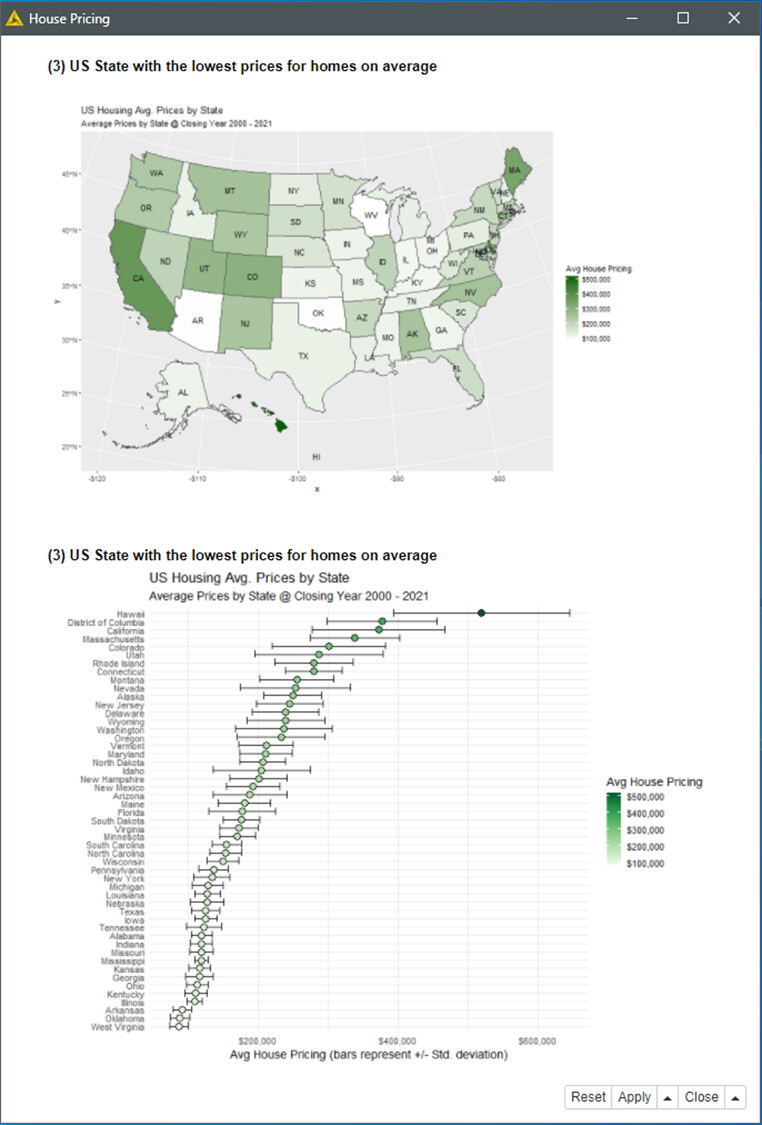
Q3.- To answer the easy question, I just took the opportunity to design a very intuitive qualitative dashboard with R. The answer by the way based in my data is West Virginia (WV).
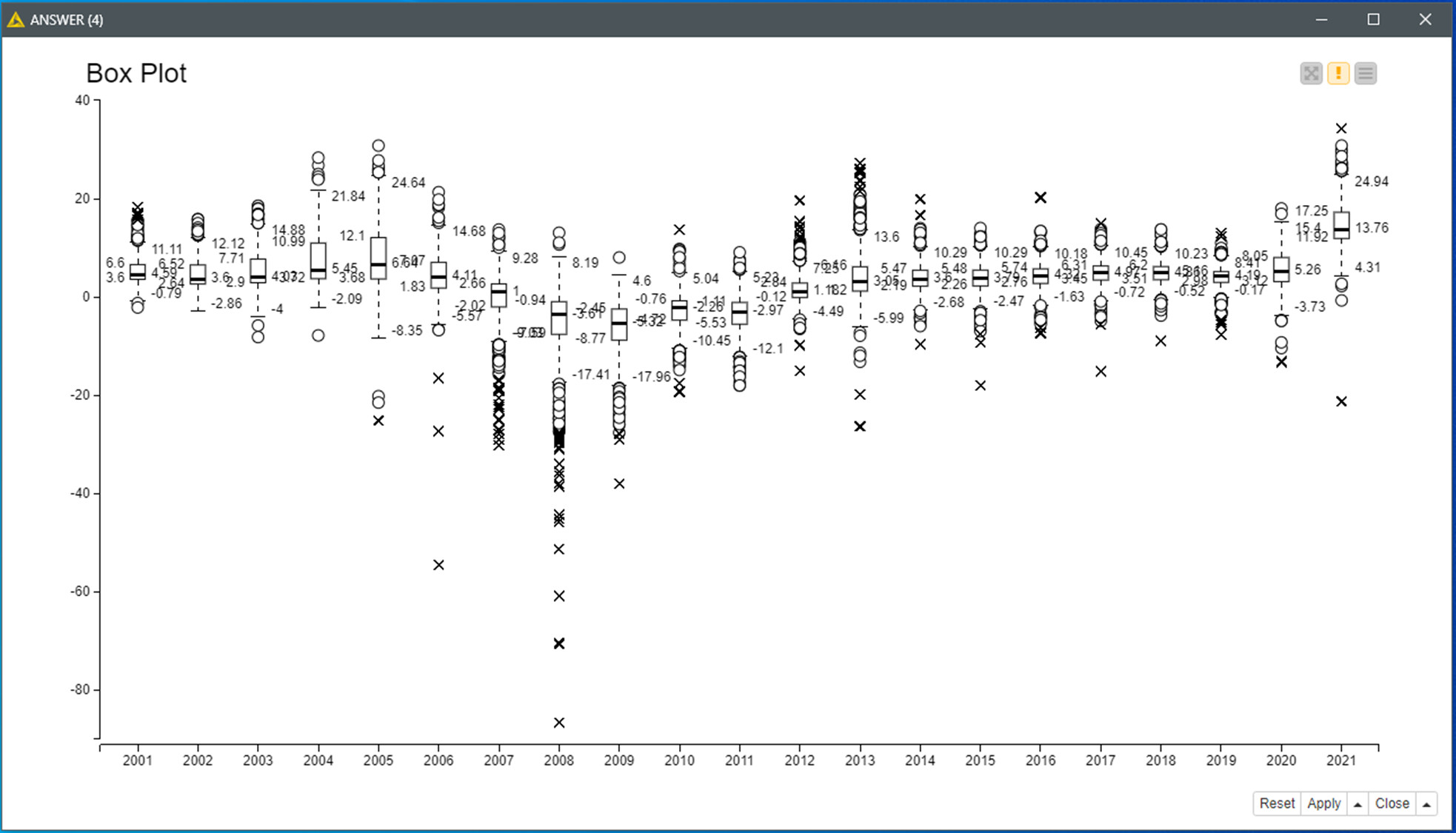
Q4.- Despite it can be explained based in Q2 visualization as suggested in the challenge description; I’ve tried a different busy one with the percent (state max) price evolutions, aiming to highlight the drama.
The trend line shows exactly when the pricing crisis started for each case close to the end of 2008. Normalizing the data surely tells the story in another way. And the final boxplot makes all more evident.
I love it when the story changes depending on how you preprocess the data (which can include normalization). Data analytics always needs to be taken with a grain of salt AND with a lot of context.