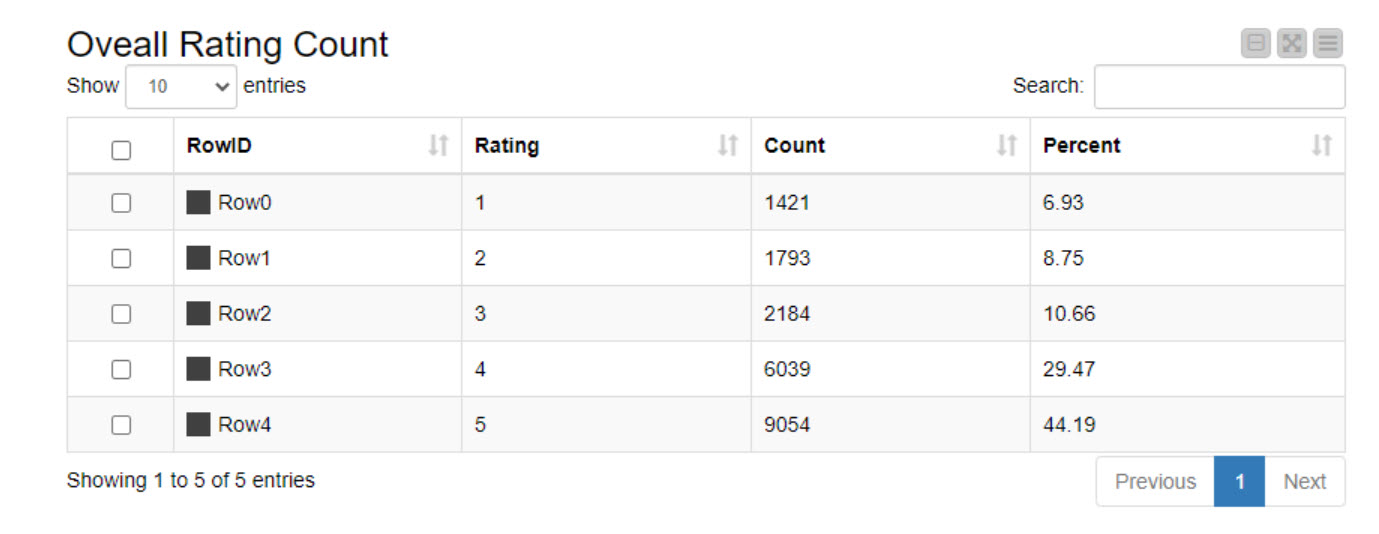
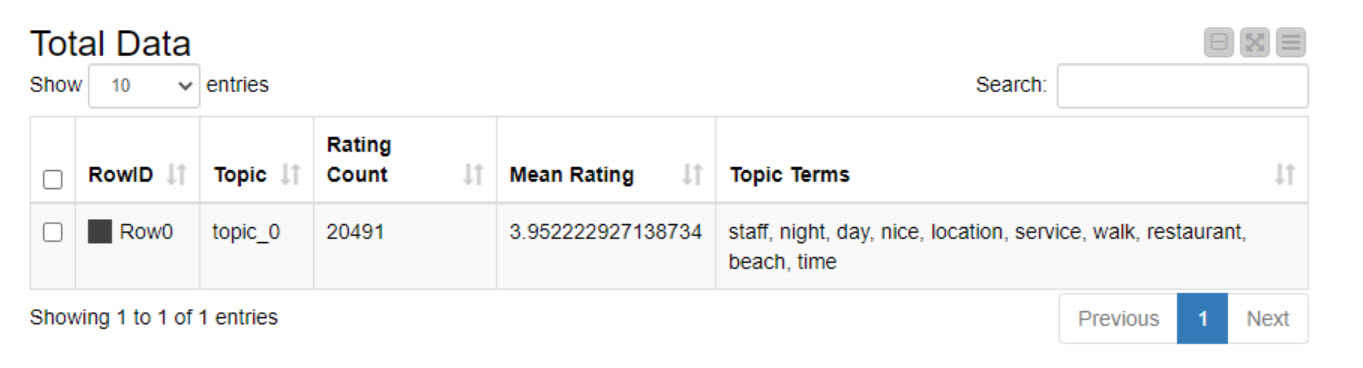
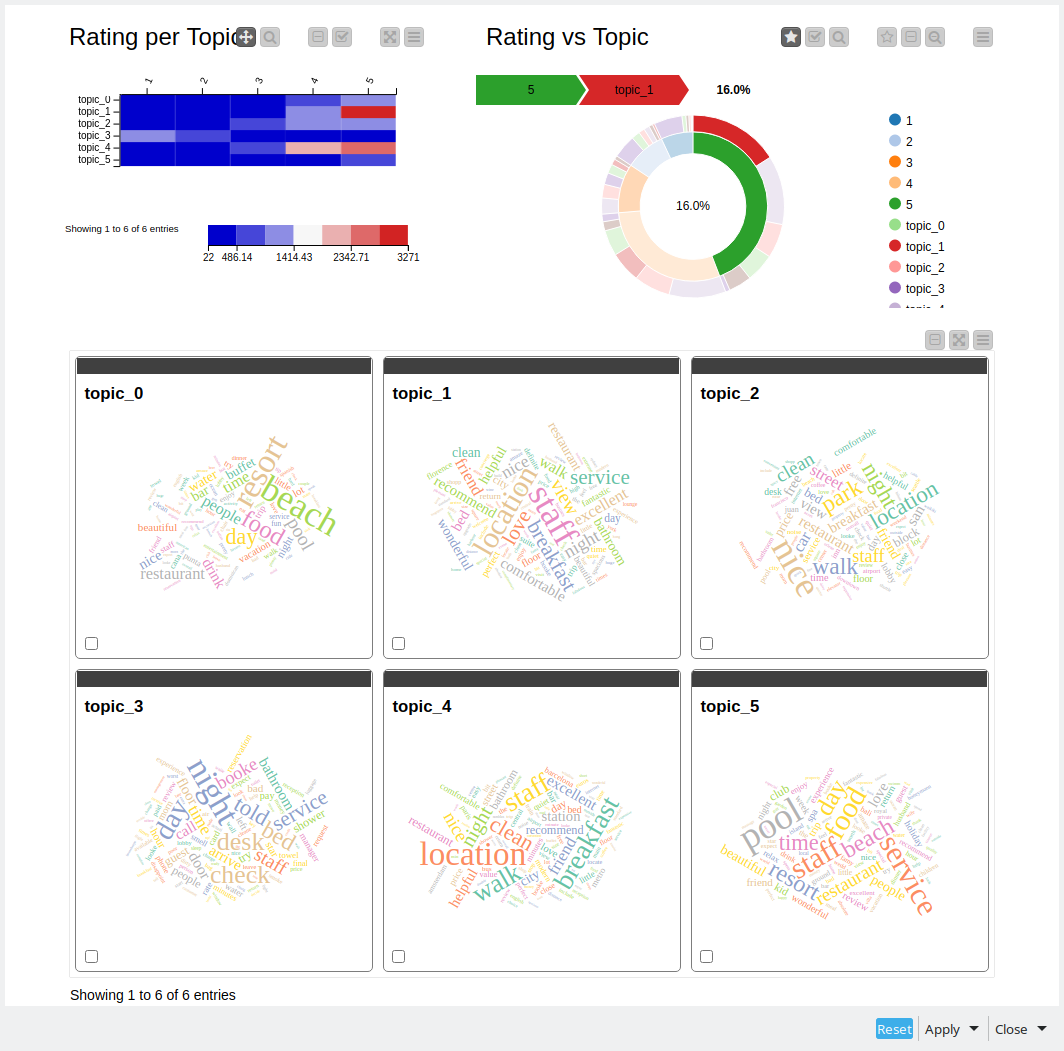
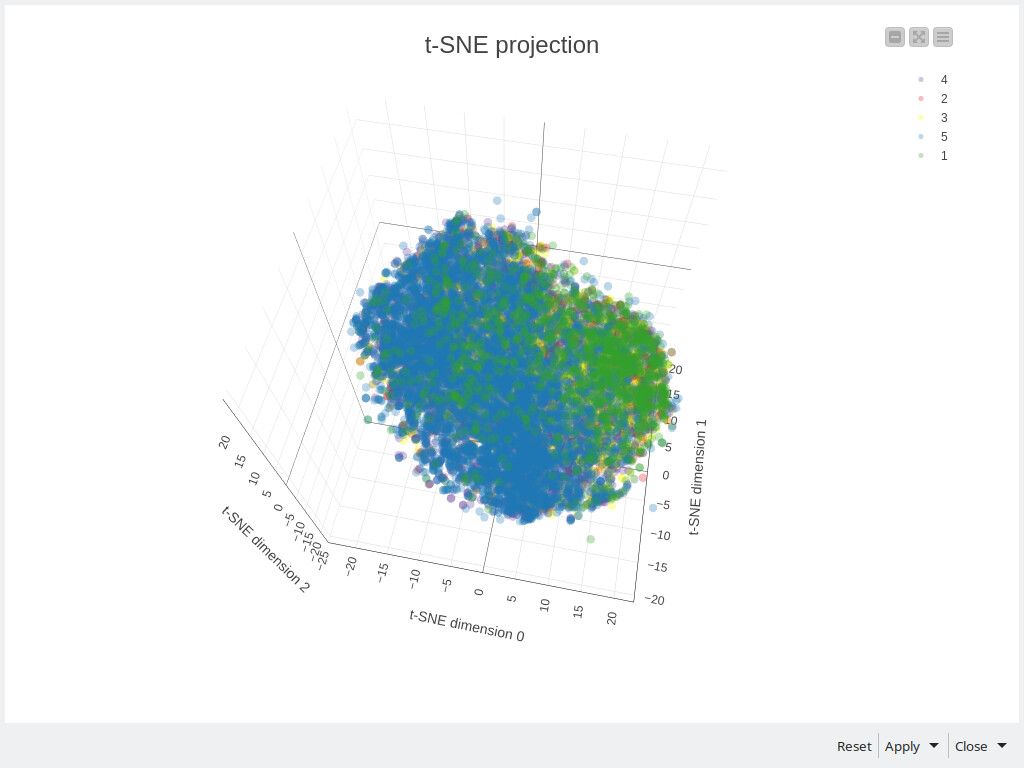
This week we’re going to analyze hotel reviews and understand what they’re addressing (in a summarized fashion!) using Topic Modeling.
Are reviews very different textually depending on their rating? What aspects of the guests’ experiences are uncovered in the reviews?
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason2-20.
Need help with tags? To add tag JKISeason2-20 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
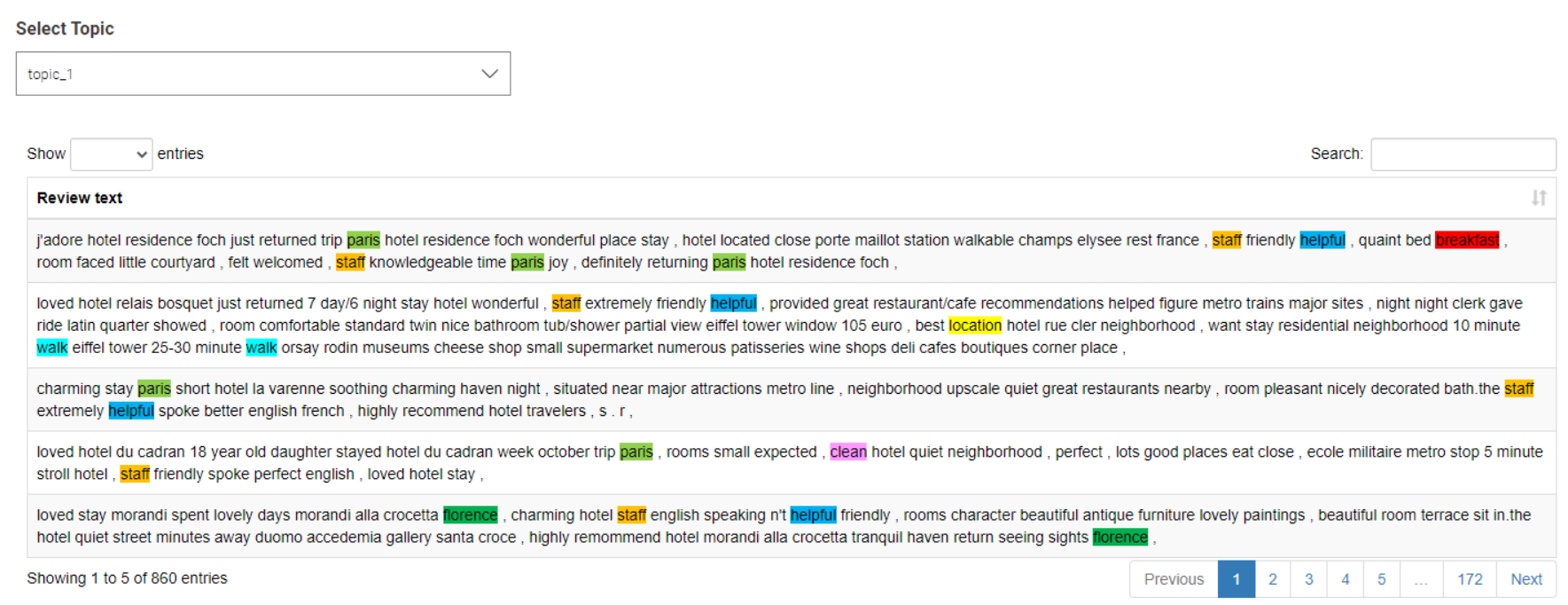
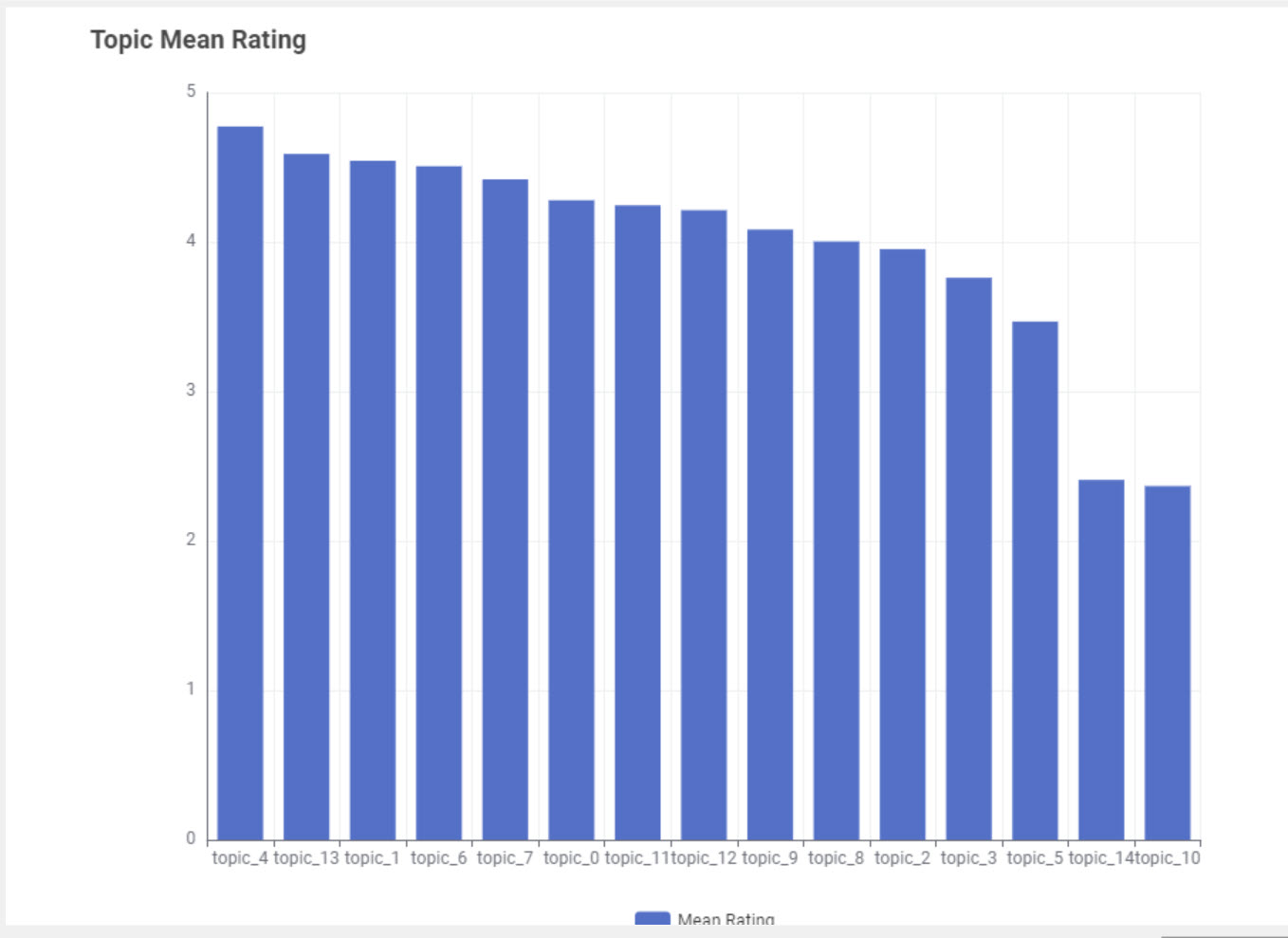
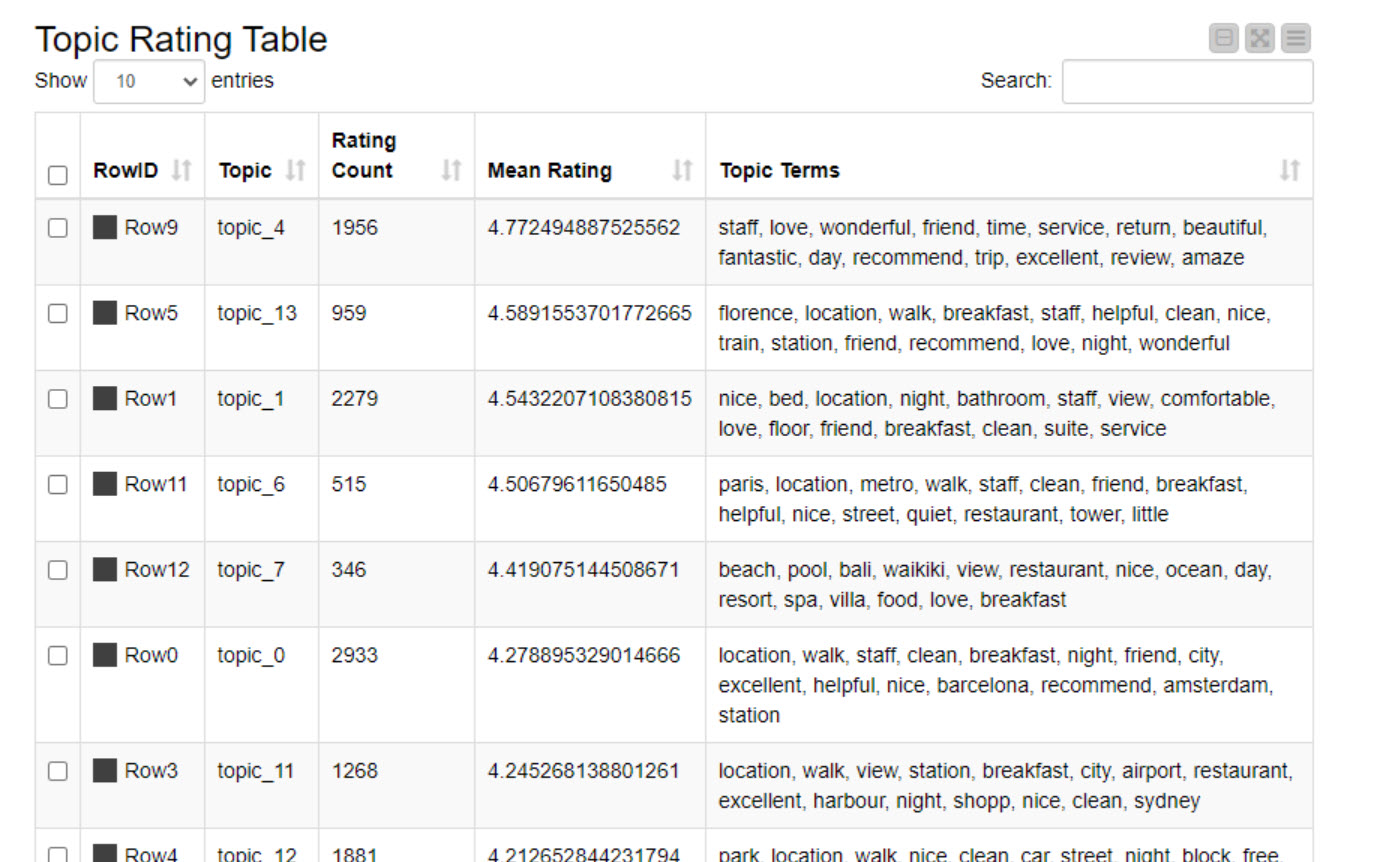
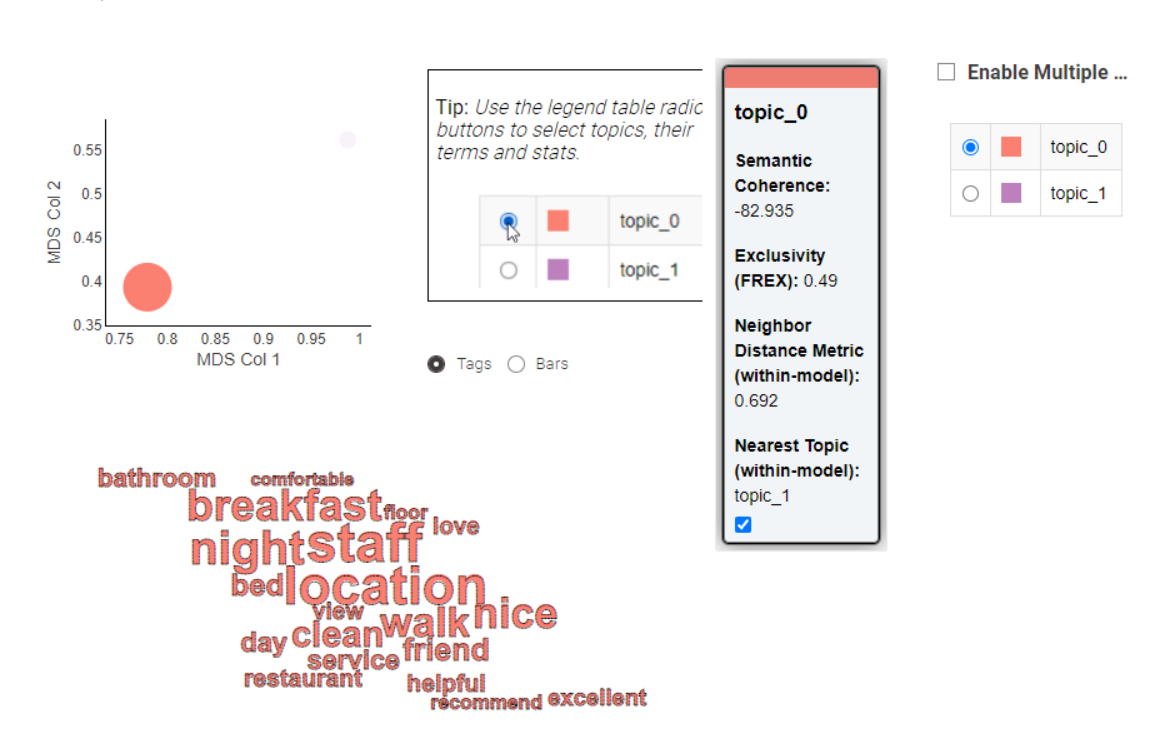
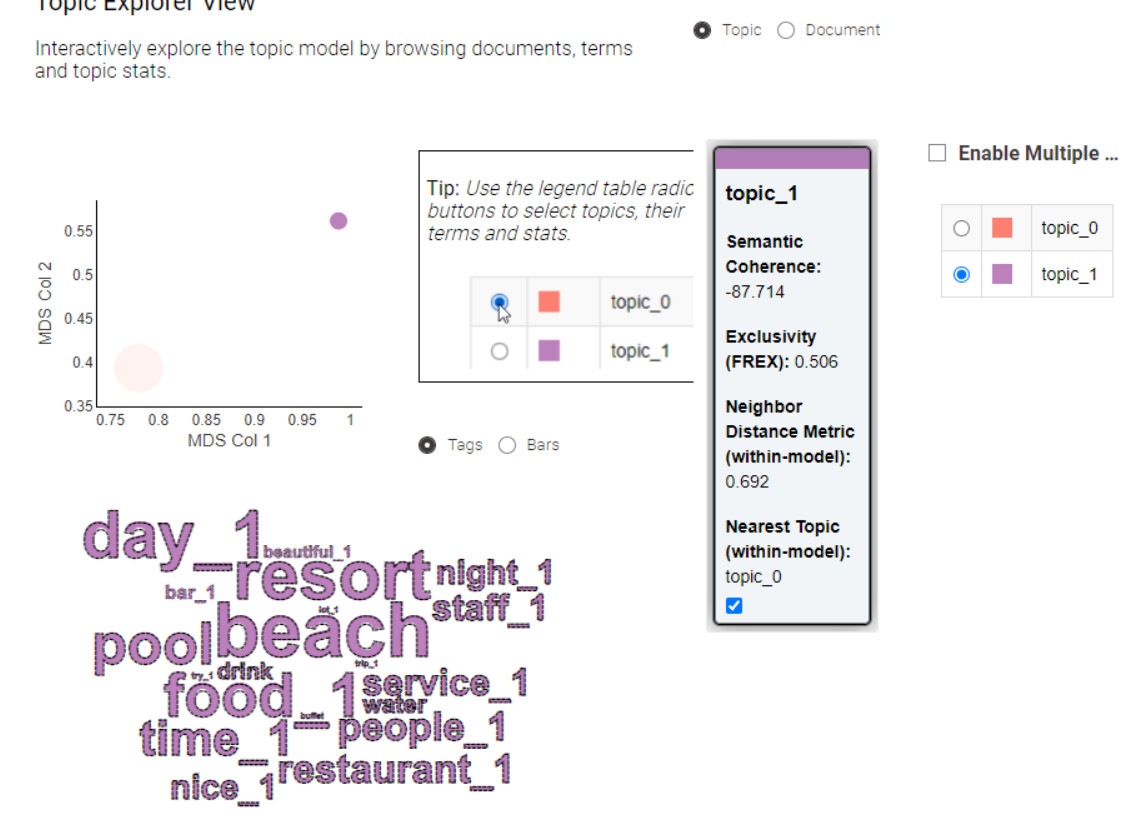
I also created the component that allows to see what are the key words per topic and estimate the connections between topics and the rating. In my case I can see that topic_3 is usually connected to the lower rating texts, while topic_4 is mostly connected to higher rank texts.
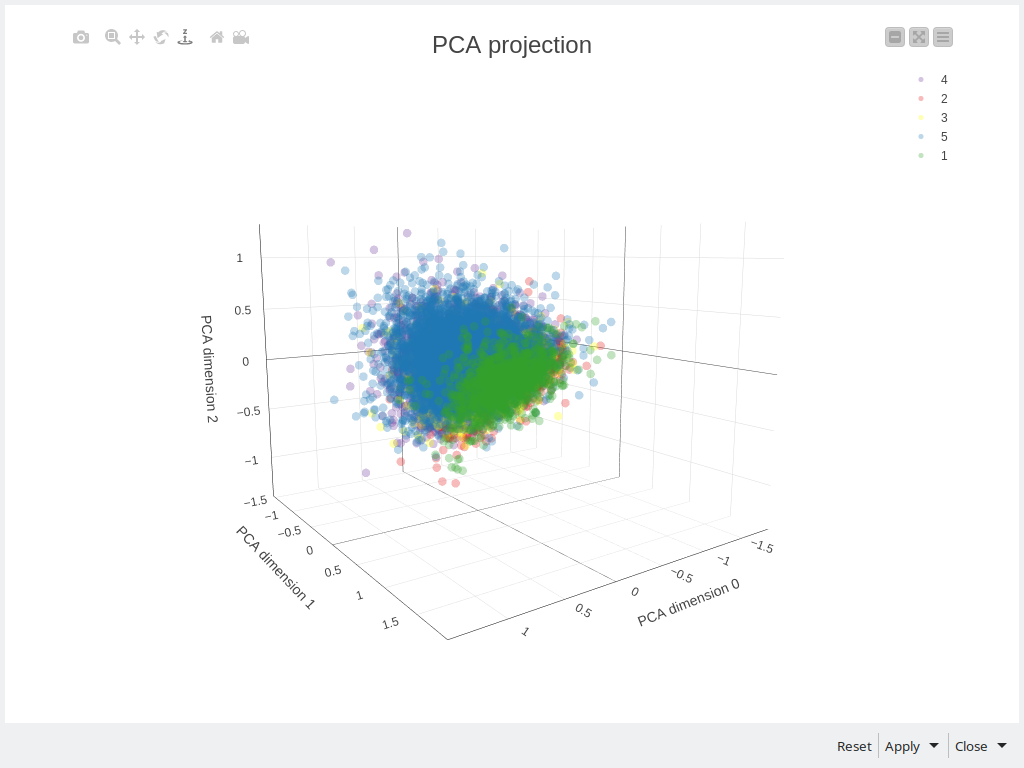
I also made some investigation to see if rating values can be anyhow helpful. To do this I used Spacy Vectorizer for the original texts, then I used both PCA and t-SNE to reduce the dimensionality and this is what I have got:
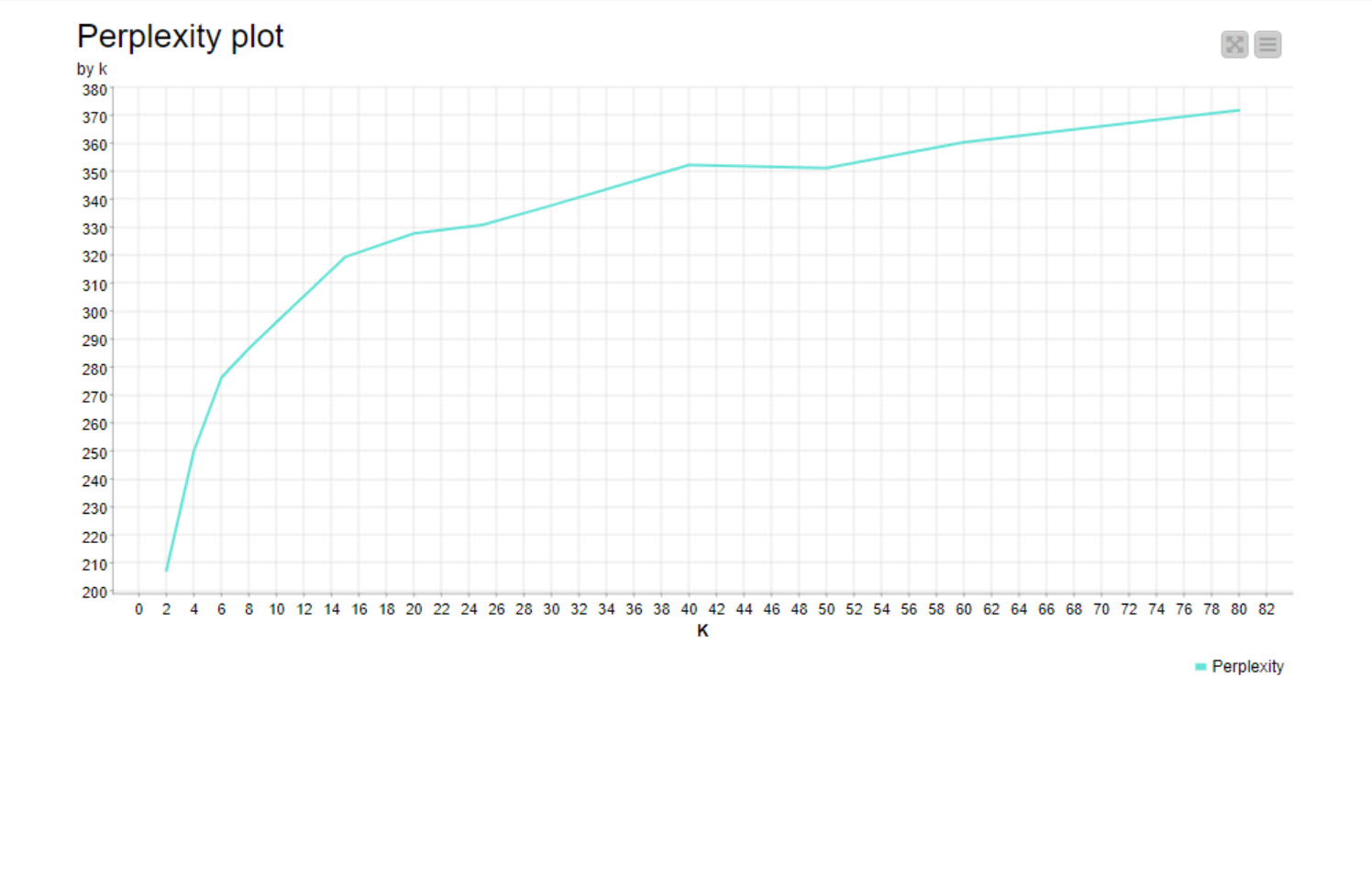
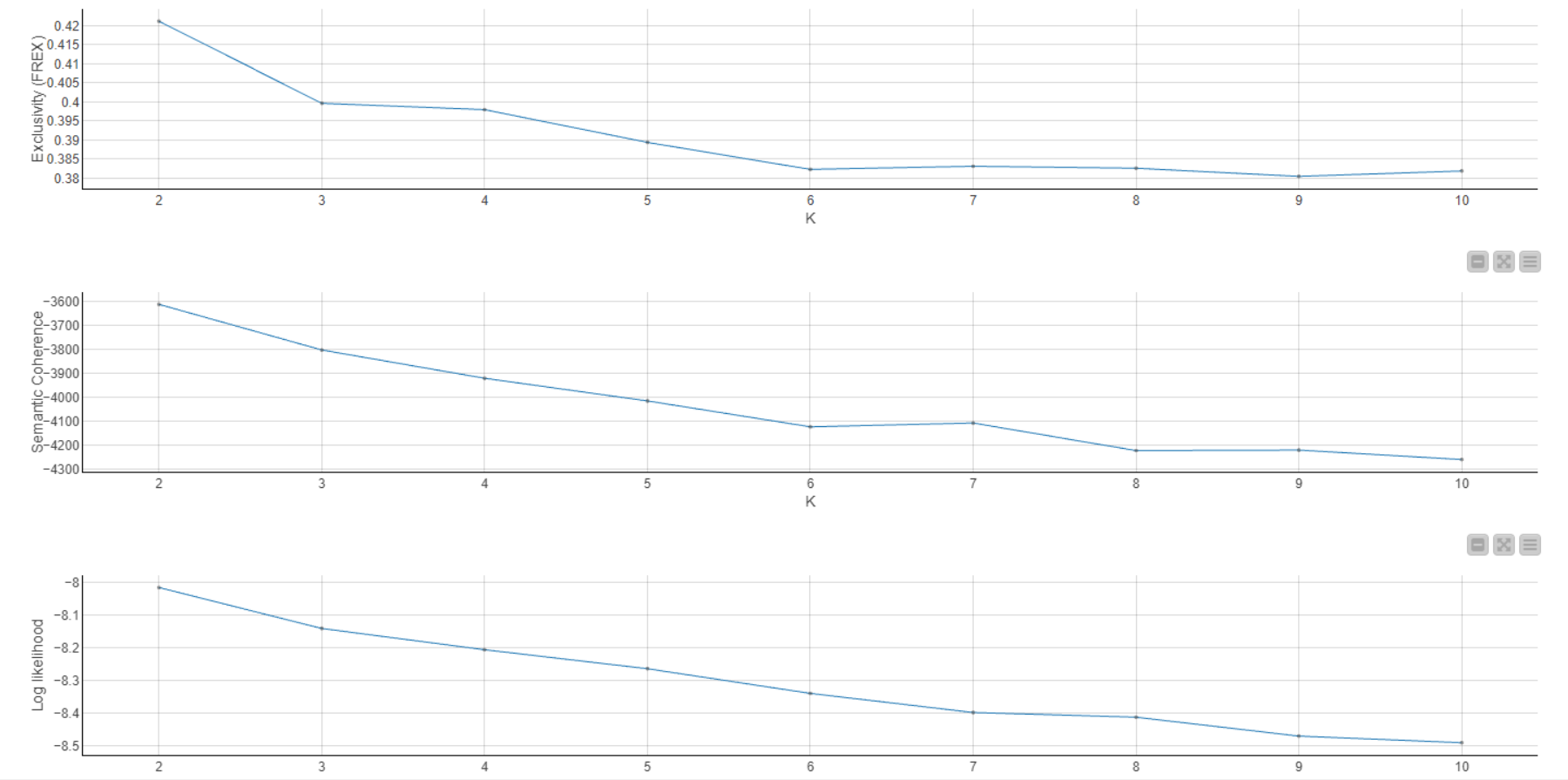
I also searched for the k value
There is also an interesting thing, in the [2,10] interval, the evaluation score is monotonically decreasing. This means that from a numerical perspective, k=2 is the best.
This solution may not be perfect because there are too many “* _1” terms in the category “topic_1”, which is a duplicate of the terms in “topic_0”, making it impossible to distinguish between the two types.
I think the solution is to add preprocessing and delete the same ‘tokens’ to increase the difference between the two. But it timed out, haha.
I’ve learned @rfeigel’swork flow and tried implementing N-grams creator to analyze continuous two words. I also tried using Elbow method to find the optimal number of topics, referring to the following.
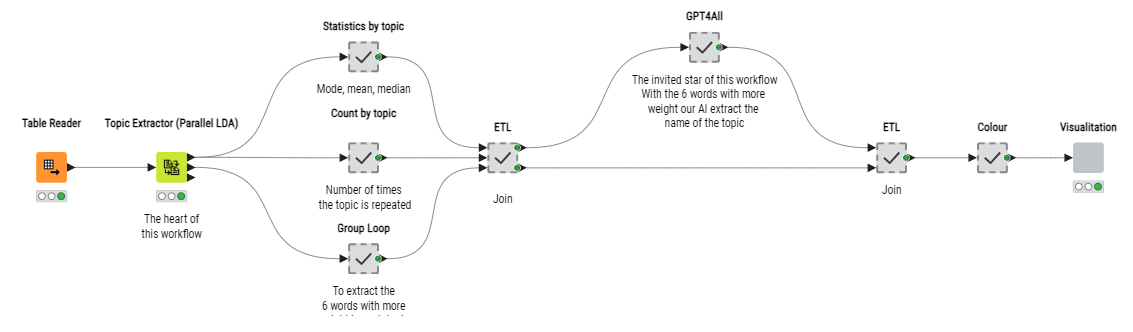
I don’t want to be late, and although I don’t fully have the workflow since I want to do an article in my weekly newsletter (today I think I’ll leave it uploaded) I want to give you a preview:
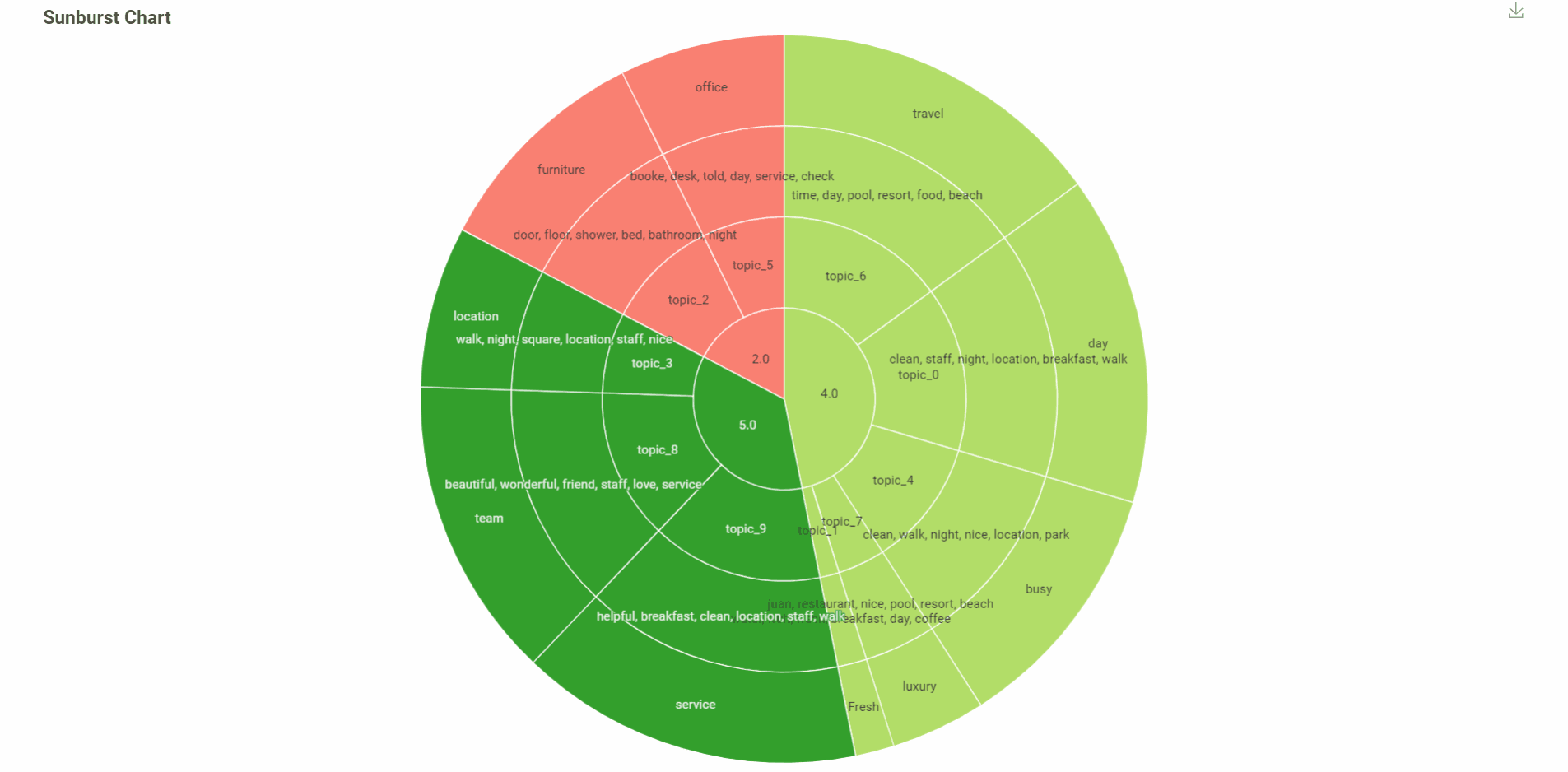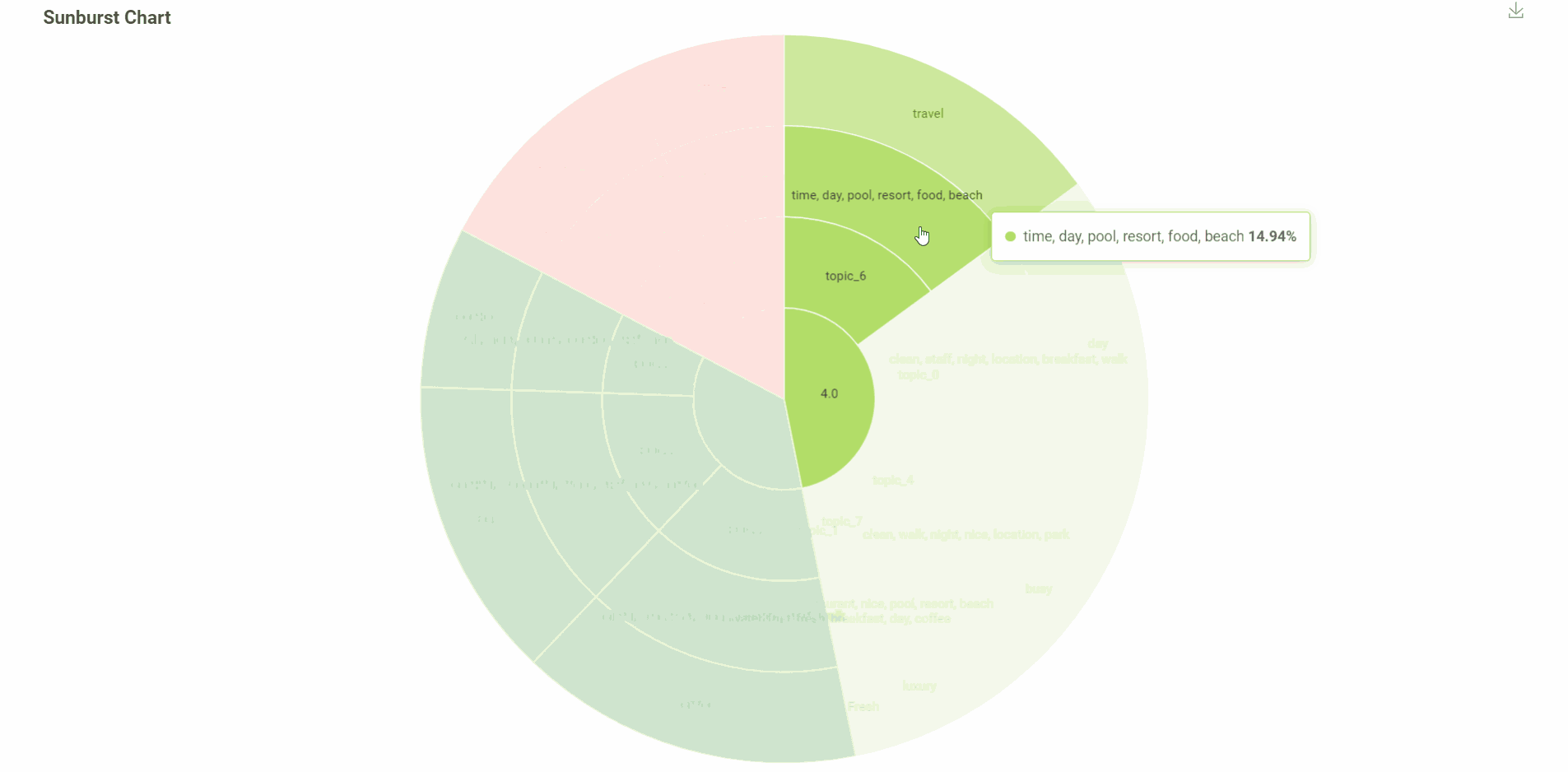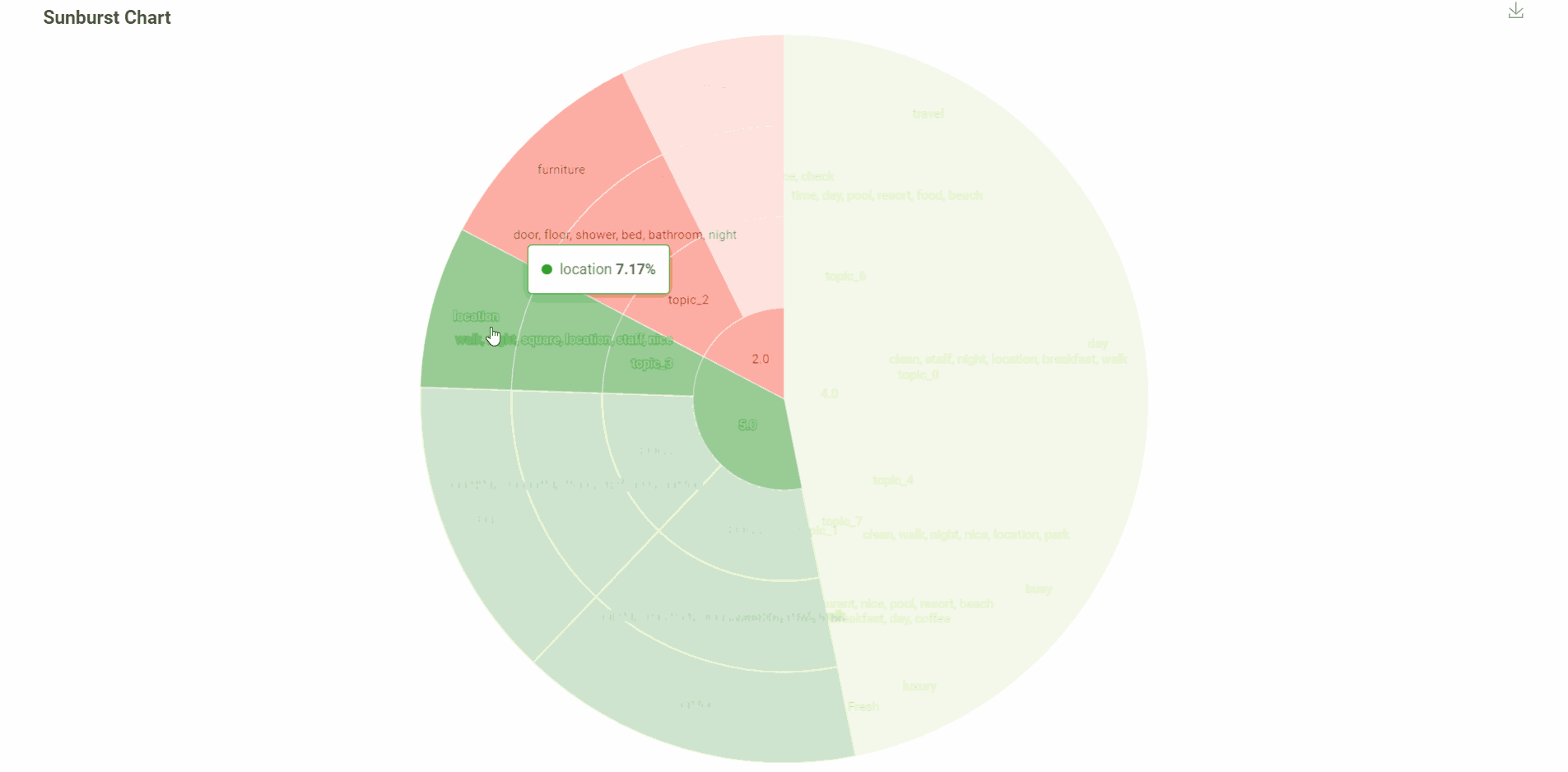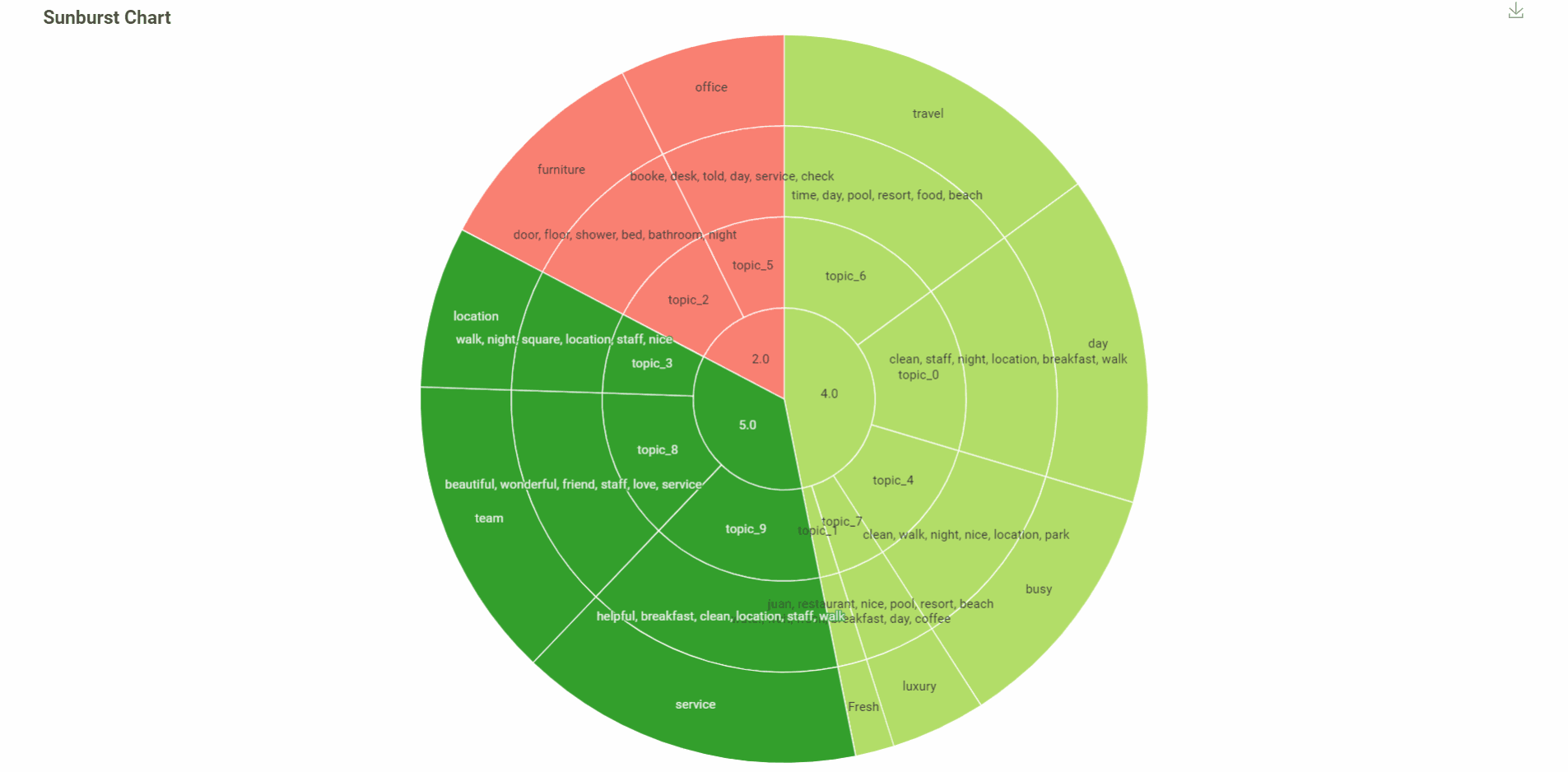
In this visualization, you can see:
Rating (median)
Topic
6 words with more weight in the topic
The name of the topic was done automatically with AI with the 6 words before
The colour of the visualization indicates the rating, red - bad. light green is good and green is super good.
% of each topic.
I hope to be able to upload the workflow and the article today.
As always on Tuesdays, here’s our solution to last week’s Just KNIME It! challenge
We used the perplexity metric to determine the number of topics for (1) good reviews, (2) bad and neutral reviews, and (3) the reviews as a whole. After that, we used tag clouds to visualize the key terms per topic – it seems like positive reviews have a very “water oriented” topic, whereas negative reviews seem to focus a bit more on hotel facilities.
Just wanted to let you know that I added some notes about the key concepts related to this challenge. You can find them here.
By the way, I noticed that the official component Topic Explorer View doesn’t work when the “No of topics” is set to 2. You can verify the error in this workflow.
WARN GroupBy 4:1803:0:1800:0:1452 Group column 'topic_2' not in spec.
WARN GroupBy 4:1803:0:1800:0:1452 No aggregation column defined
WARN GroupBy 4:1803:0:1800:0:1452 No aggregation column defined
WARN GroupBy 4:1803:0:1800:0:1452 Group column 'topic_2' not in spec.
I’m not sure if it’s related to my KNIME version (4.7).
There is also this issue in 5.1, and I made the necessary modifications myself. Just unbind the component, find the “groupby” node inside the component where the error occurred, and delete the “topic_2” . I handled it this way on a temporary basis.
This week I was inspired by this workflow on the hub to determine the best k value for the -Topic Extractor (Parallel LDA)- node. From looking at the Semantic Coherence and Perplexity, I also chose a k value of 2 topics to implement in the rest of the workflow.
I then created a -Tag Cloud- for the reviews overall:
Looking at the different tag clouds, “location” appears to be a commonly used term for the reviews with a mid to high rating, where as the term “night” seems to be popular in reviews with low ratings.