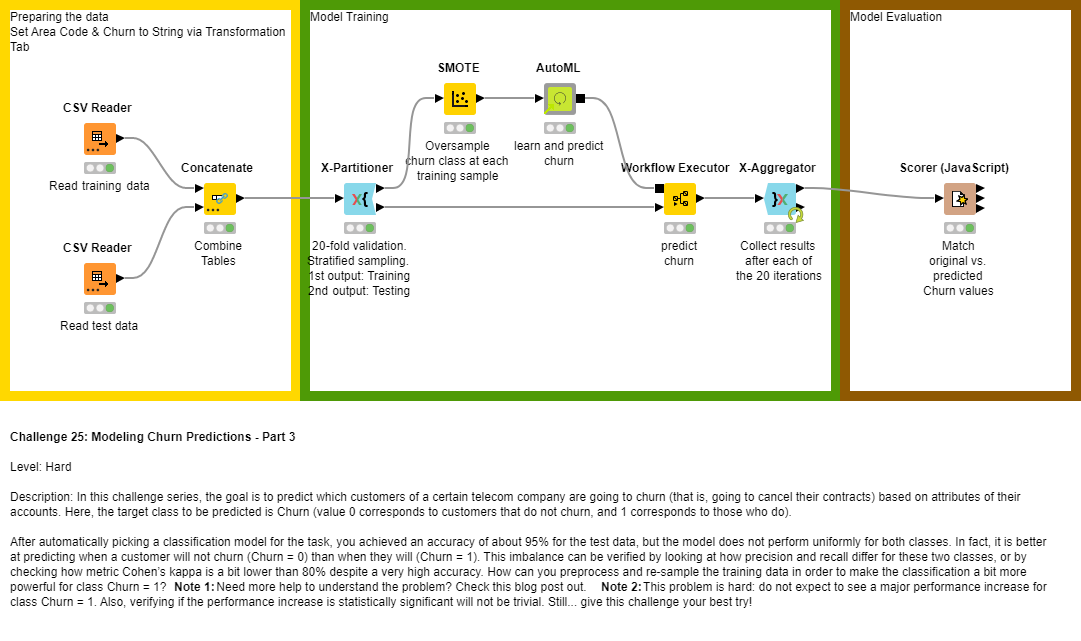
This thread is for posting solutions to “Just KNIME It!” Challenge 25, the third part of our four-week series on data classification! How can we preprocess our training data to build a classifier that is a bit more balanced for both classes?
I used the AutoML Component node from Challenge 24 and added 3 nodes in order to process and resample the given data:
X-Partitioner act like your Start Loop Node where you can also define how many validations/iterations the model needs to run
SMOTE in order to get good classification performance for Churn = 1
X-Aggregator as your End Loop Node
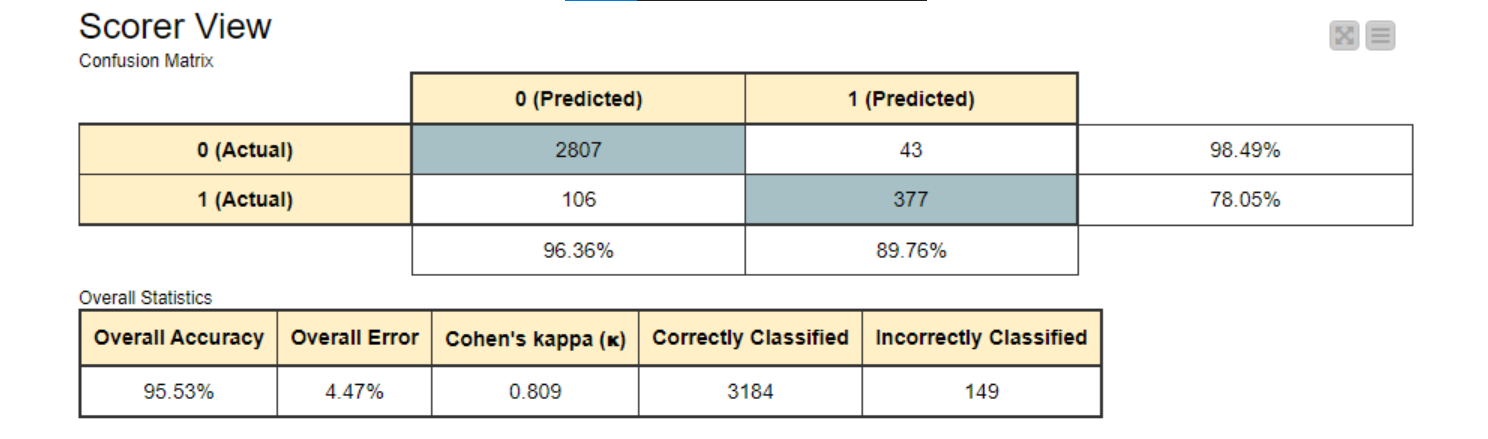
My Cohen’s kappa is now above 80% while still maintaining overall accuracy of above 95%
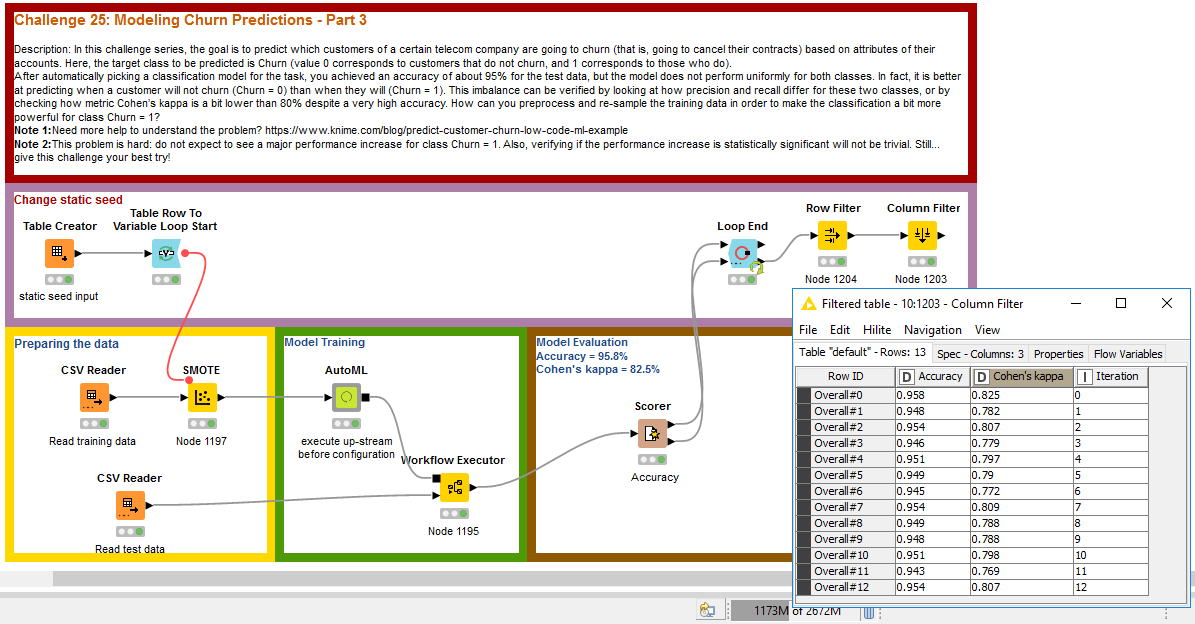
Note: In my first run, I used 10 times validation, this gave me a 0.799 Cohen’s kappa and accuracy of 88% for Churn = 1, so I presume the higher the number of validation will give me a better Cohen’s kappa value and accuracy. for Churn = 1
Here is a solution for the “Just KNIME it” challange 25.
I have used the parameter optimization node to tune two parameters in the model: “minChildSize” and “nrModels”. To test the overall accuracy for each parameter I have used the x-partitioner to make a k-fold (n=5) cross validation. The SMOTE node is used to make an equal amount of “Chun” as “Non-Chun” rows. The best parameters are chosen to create the final model, which has an accuracy of 95% and a Cohen of 0.783.
Changing random stuff until your program works is “hacky” and “bad Coding practice”, but if you do it fast enough it’s “Machine Learning” and pays 4x your current salary.
My last submission from previous challenge works pretty well for this challenge part, so here is the link to my previous contribution with workflow and infos :
Without any change on data, by using and optimizing XGBoost, I’m able to achieve a Cohen’s Kappa of 0,825 (and accuracy of 95,802%), a better score and better prediction of the minority class than the previous solution of last challenge with AutoML component.
I tried to add and test SMOTE, bootstrap oversampling and undersampling, but I obtained lower scores.
I will try some other options of data transformations, perhaps with the autoML component, and also try to figure out a statistical test or fair comparison technique to emphasize on the benefits of data transformations
Here’s my solution. I added a Smote node to the workflow from Challenge 24 as well as some statistical nodes to compare the results from Challenges 24 and 25.
Interesting! This means that the optimization you tried was not implemented in the AutoML component. Good to know, and telling of how model engineering is “infinite”.
Your workflow does a really good job at highlighting how the solutions are sensitive to parameter changes (here, a change in the seed you use to resample the data). Note that there’s a chance that these performances, even if a bit different, are statistically equivalent. Still fun to see how they vary here.
My take on Just Knime it - Challenge 25
Churn Prediction Part 3
Tried to play around the various sampling techniques to raise the Kappa along with accuracy.
In the AutoML component you can change the standard settings and optimize hyperparameters, change step size and optimization strategy, that might be more relevant for a specific algorithm.
By default, I have found that for XGBoost Tree Ensemble, the standard settings for parameter optimization were :
Hyperparameters to optimize : max_depth (from 5 to 10, with a step size of 5… ?!) and eta (from 0,2 to 0,3 with a step size of 0,1),
Optimization strategy : Random Search
From my side, I have optimized hyperparameters of XGBoost Tree Ensemble with these settings :
Hyperparameters to optimize : Max depth (from 2 to 10, with a step size of 1) and min child weight (from 1 to 10 with a step size of 0,1)
Optimization strategy : Bayesian search
I think AutoML is a very good component to have a first quick and to deliver a first good prototype, and/or to help decide which algorithms should be more relevant to the dataset. But once the algorithm is chosen, there is still room for optimization
As mentioned, even with data transformation and resampling strategies, I wasn’t able to outperform these first results. Even with normalization and data transformation, the results were just above 0,8 for Cohen’s kappa, but lower than 0,825 I had with optimized XGBoost, so I’m very curious to know how you achieve better results
And I’m quite skeptical about some of the solutions here which are mixing the training and test set, this is not good coding/ML practices, and it provides biased/overestimated performance of the solutions, since test set is seen during the training. A good example of data leakage and what ML practicioners should avoid. I can only recommend the excellent playlist “Making Friends with Machine Learning” by Cassie Kozyrkov, that explains the basics of Machine Learning and the algorithms MFML 069 - Model validation done right - YouTube
As always on Tuesdays, here’s our solution to last week’s rather tough challenge!
As stated in the challenge, the idea was to optimize the model over the training data and then assess its performance over the test data, so we did not use cross validation over a combination of both datasets here. We also did not experiment further with model optimization (I mean, we’re still using the AutoML component here, but we did not try anything different from this, or played around with the component itself). Rather, we focused on data engineering. Since the AutoML component already does a fair amount of feature engineering, we worked on altering the data distribution by using sampling techniques. Our goal was to be didactic with these challenges, so we refrained from playing with many aspects of ML engineering at the same time.
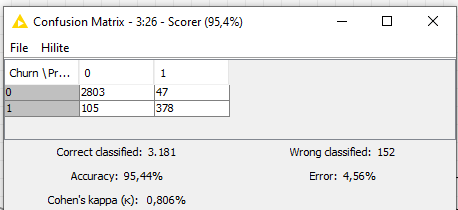
As a result, we got a Cohen’s Kappa of 81.1% and an accuracy of 95.4% – both better than last week’s – but we haven’t evaluated the statistical significance of this change.