This thread is for posting solutions to “Just KNIME It!” Challenge 3. Feel free to link your solution from KNIME Hub as well!
2 Likes
Hi @alinebessa , not sure if the data files are correct or not.
For the CSV file CDC_cancer_2017.csv for example, there is data in all the columns up to the Count column up to Row 156977, but with a lot of missing values in the Count column. Then past that row, all of the columns up to Count have no values, but Count is fully filled up to Row 158296.
See extract below:

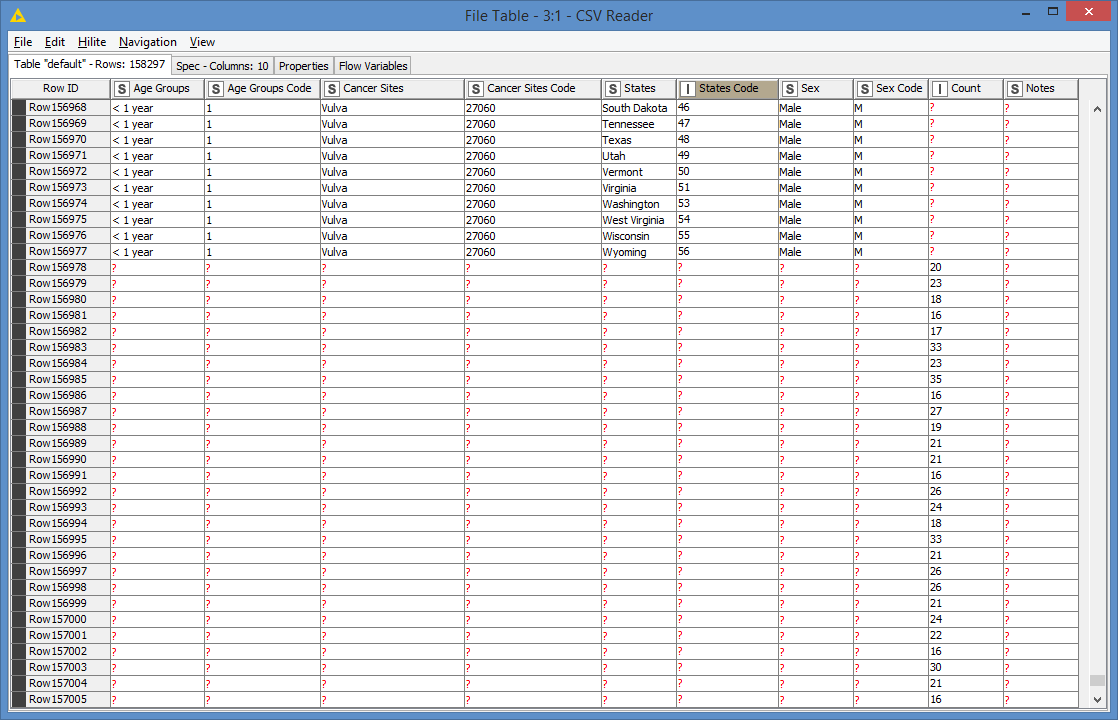
Is that normal?
And for the Excel file population2017.xlsx, all of the states, except for the last one, starts with a dot:
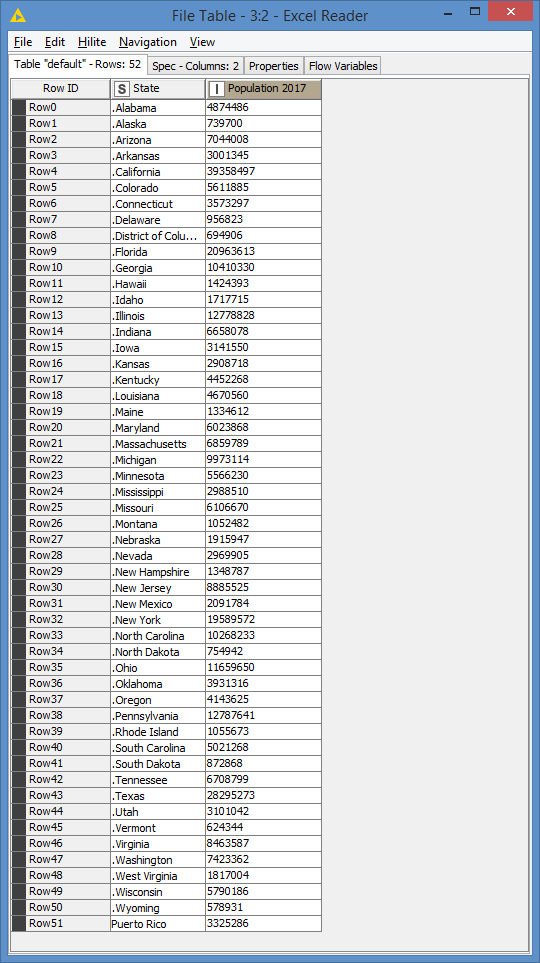
Was that on purpose to see how we manipulate the string, or is that unexpected?
Please confirm.
Thank you
2 Likes
Hi @bruno29a,
Yes, the CDC data has missing values for lots of different cancer types (per gender and per state). It’s a bit dirty, like so many real-world datasets. The interesting thing here is that it allows you to exercise your data cleaning skills. How would you handle this missing data?
And as for the population dataset, it is also a bit dirty and the purpose is also to exercise your data cleaning skills by doing, for example, some string manipulation.
Hope this answer helps!
Cheers,
Aline
3 Likes
Hi,
I have a solution but I’m not really happy with it.
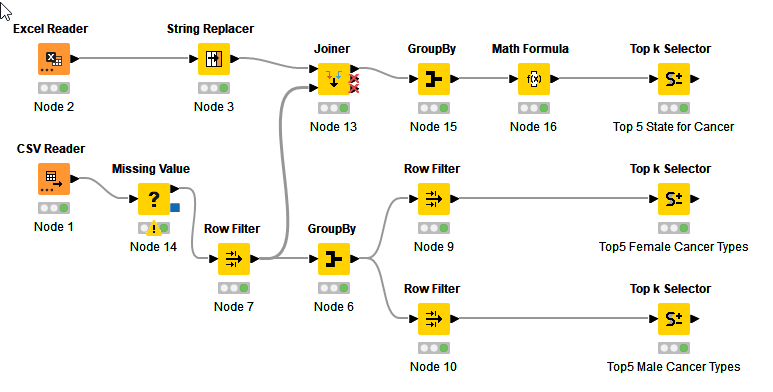
My Workflow:
just_knime_it_3.knwf (760.7 KB)
Why am I not happy? Because I don’t know how to deal with stuff like this:

Should I generate new Cancer Site codes and distribute the count equally over this new side codes?
Or something like this:

Should I count the values vom 33011 to the range from 33011-33012 or vis versa?
I don’t think there is a good answer without domain knowledge.
Best Regards,
Paul
3 Likes
One of the most important parts of data cleaning/wrangling/science is to explain what assumptions you made. I would be happy with your solution so long as you made your audience aware of what issues you faced. At the end of the day, these challenges are created so that you can arrive at an MVP (minimal viable product). This is because in the real world, we seldom can arrive at a perfect product that we are truly happy with. And it’s great you understand that you need domain knowledge to arrive at an answer that even experts will accept.
Finally, congratulations on being the first brave person to post your solution! If you could share on the KNIME Hub as well, that would be awesome! Thank you!
3 Likes
Hi @alinebessa , thanks for confirming. I just wanted to make sure that they were the correct files 
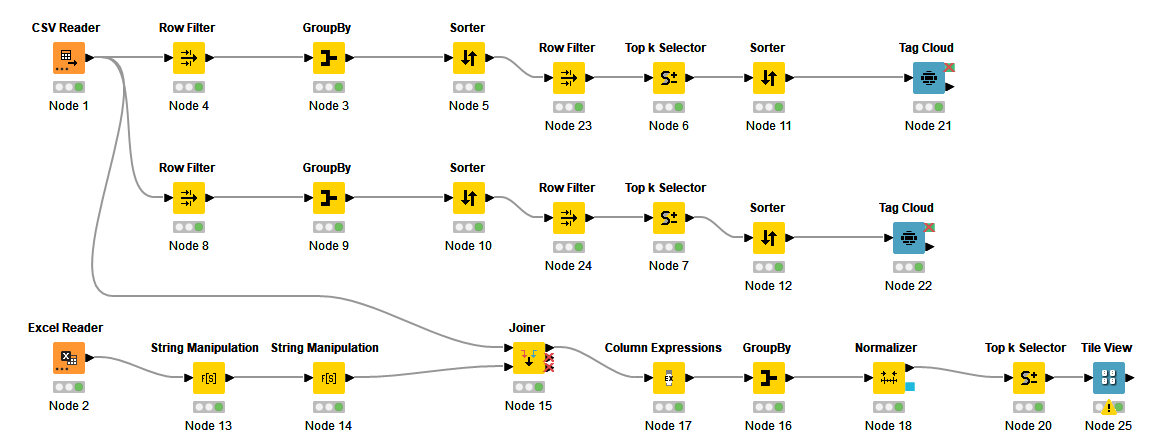
Here’s my solution:
2 Likes
Here’s my solution…some nodes were used for data cleaning (and some aggregation was already there  ).
).
https://kni.me/w/JhMbBGcfanUosdip
2 Likes
Here’s my solution
2 Likes
Hello!
Here’s my solution to the challenge.
Thanks!
OmprakashJena
2 Likes
I went back to my workflow, and realized that the results did not show what I expected. I sorted properly to get the Top 5, but somehow the results were not correct, or rather, it did pick out the Top 5 of the list correctly, but did not display the Top 5.
That is because by default it does not sort the results in the order that the Top k Selector is configured. I have to specify to sort the output too:
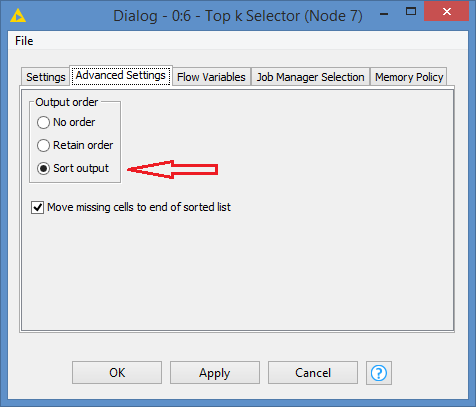
The corresponding nodes have been modified with this setting. Workflow updated.
1 Like
Here is what I got.
CDC Data.knwf (36.8 KB)
3 Likes

Here’s my solution to this interesting challenge (including my assumptions in the workflow):
3 Likes
this, I believe, is the “Cancer Sites” classification used in our dataset and this is a complete dataset based on that classification, which, as you can see, is hierarchical. But in our dataset the value of some aggregations, e.g. “Oral Cavity and Pharynx” (20010-20100), exceeds the sum of their sub-items, because some of them are missing, e.g. “Lip” (20010), “Floor of Mouth” (20040). I don’t know how to fix that
here is my solution for #3
Hello everyone,
here is my solution: justknimeit-3 - Raffaello Barri
I might have overdone it a little bit 
RB
2 Likes
Hello, here is my solution, It is the 1st versión, I will work on an alternative for joining the Cancer Sites Code, due to exists some groupings like the following:
- 35041-35043
- 35011-35043
- 33041-33042
- 33011-33012
- etc
Hello dear KNIME enthusiasts,
I have also tried this challenge, by providing an interactive dashboard at the end for the most frequent male/female cancer types.
Assumptions on the dataset are provided.
Here is my try : https://kni.me/w/zEA_i0AQQ8wqy4lX
Hello KNIME lovers:
Here my solution.
I tried to make it as easy as possible.