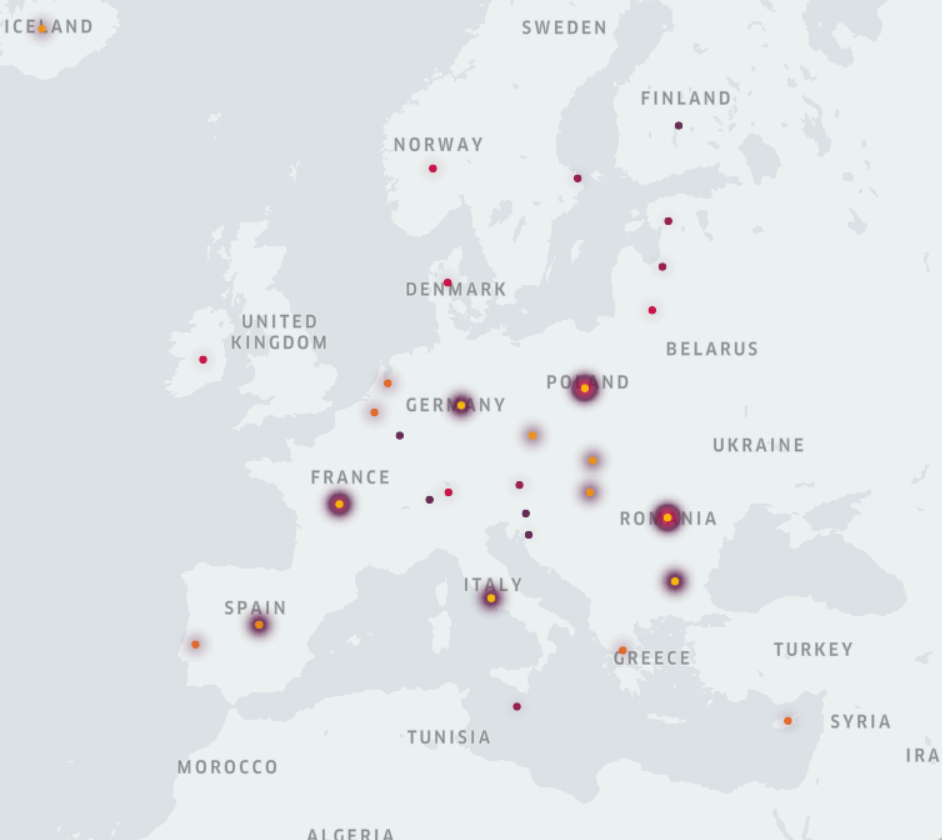
Hi, folks, hope you’ve been having a good week so far. Shall we solve a fresh Just KNIME It! challenge?
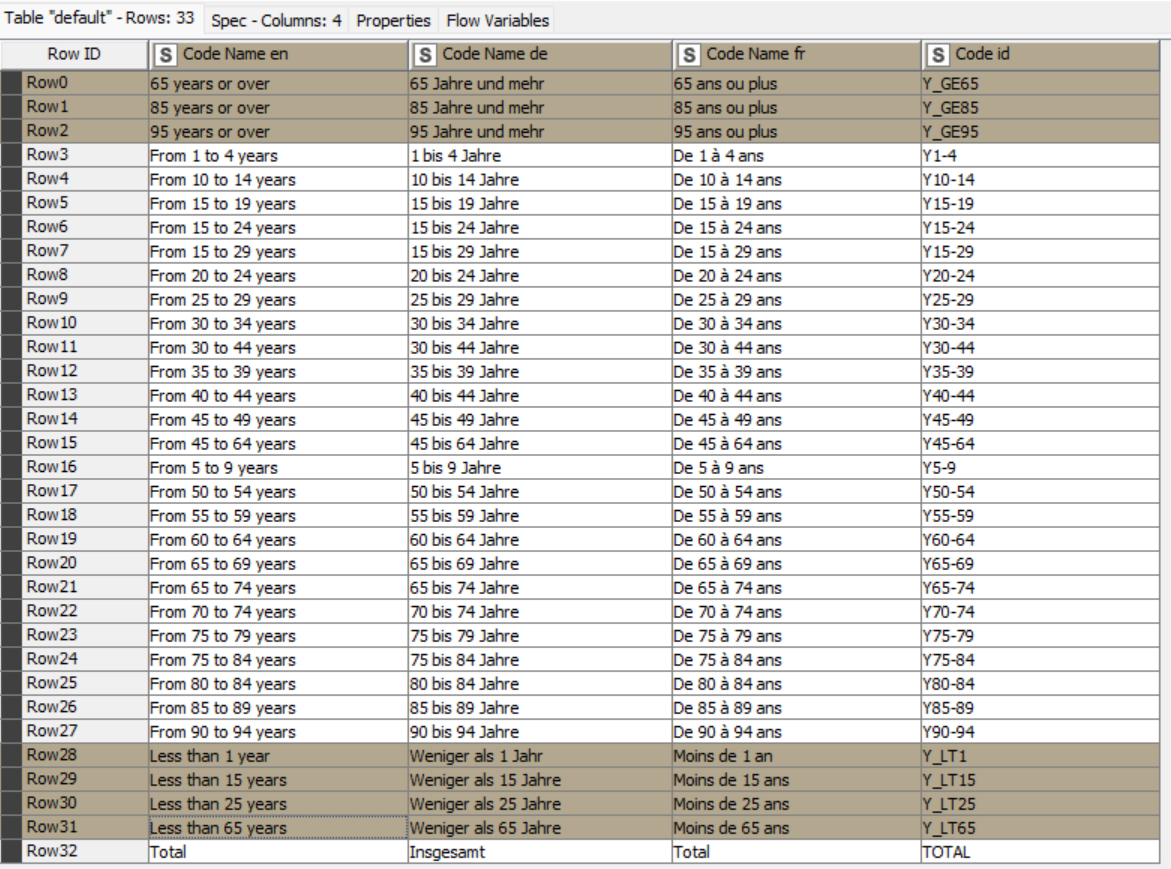
This week you’ll study some demographic data on causes of death in the European Union. The central dataset, however, has column names and values that, at first, don’t make a lot of sense. To gather proper insights, you’ll then have to match its structure with some given XML metadata. What are your findings? What regions of the EU have similar patterns or unexpected driving causes of death?
Here is the challenge. Let’s use this thread to post our solutions to it, which should be uploaded to your public KNIME Hub spaces with tag JKISeason3-4.
Need help with tags? To add tag JKISeason3-4 to your workflow, go to the description panel in KNIME Analytics Platform, click the pencil to edit it, and you will see the option for adding tags right there. Let us know if you have any problems!
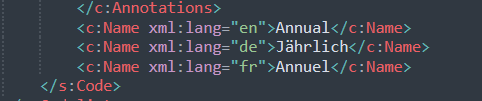
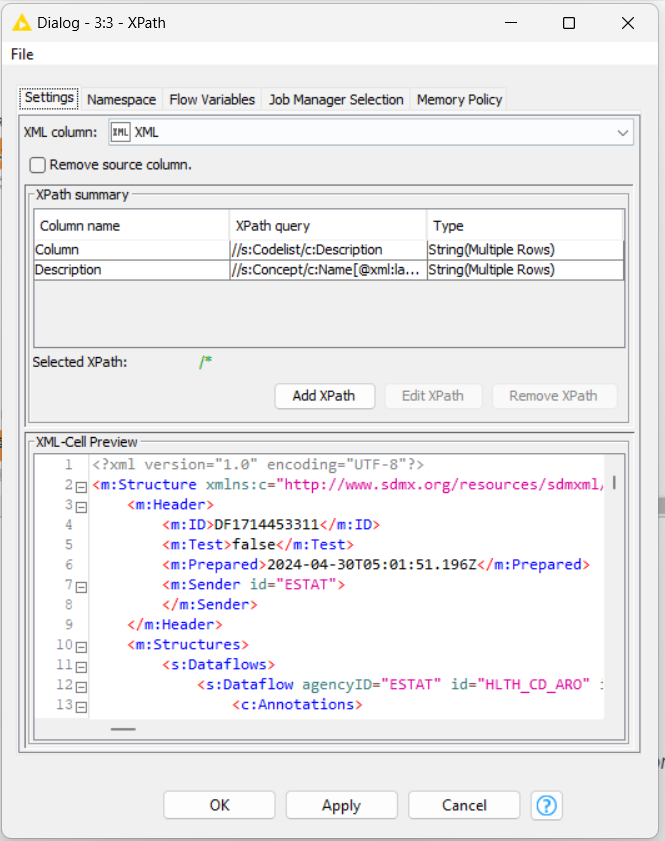
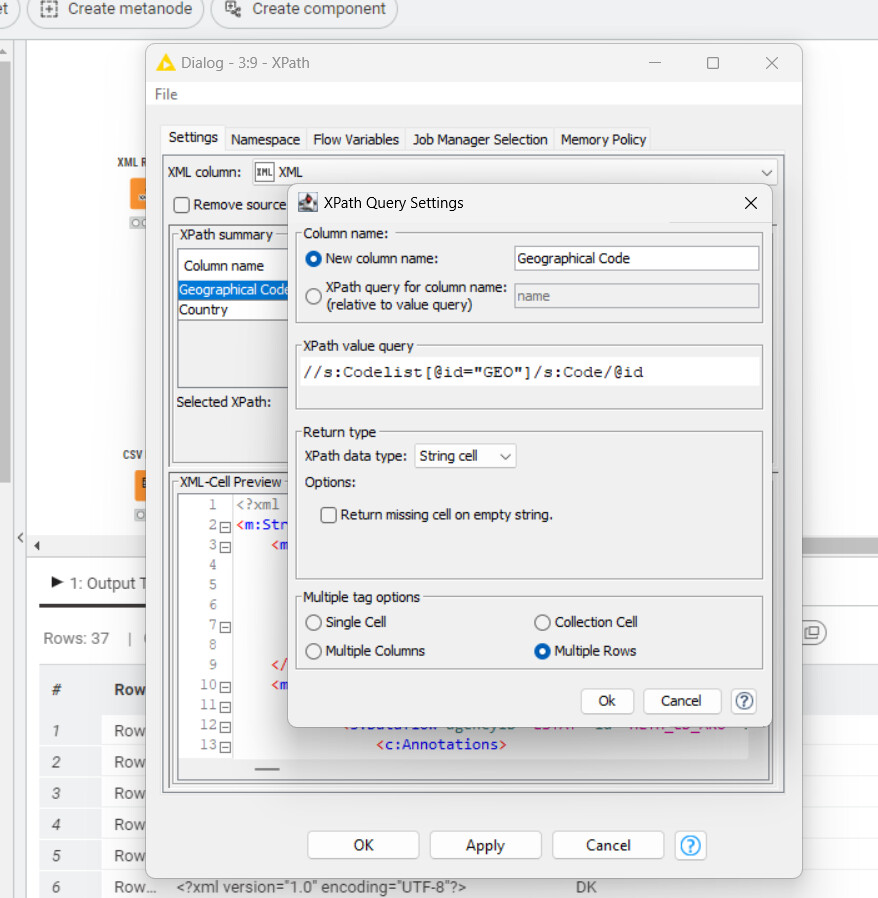
FYI - Upon inspecting the XML I noticed something other Knimers might struggle with. Colons in the attribute names:
To level the playing field, this has been flagged before and there is a workaround available using indirect XPath declarations like @*[name()='<attribute:name>'] . e.g.: /rdf:Description/@*[name()='aux:Firmware'] (in courtesy of @armingrudd ). Read more in this thread:
Enjoy the challenge!
Edit: Here is a sample XPath as this aspect might be rather annoying //*[local-name()='Name' and @xml:lang='en']/text()
@MartinDDDD I interpreted it that way too but then there are also properly reported deaths with only “All deaths reported in the country”. Anyways, let’s put that in the “weird data drawer” and forget about it since not “death threatening” (pun intended)
Update
Is my perception wrong or is the data a huge mess, resulting in substantially fewer solution submissions because Exploratory Data Analysis (EDA), as well as any other method, only works with clean data?
I am still working to get the data workable and found that there are sub-groups that make no sense. Though, I noticed that the more data I filter, the easier the data set is to understand and charts finally start to make sense. But I work more to get the data usable than actually on a solution. Like in age:
String representation is not properly sortable, resulting in poor chart quality as related values are not grouped
Does Less than 15 years in- or exclude the less than 1 year group
Totals must be filtered, otherwise they mess up the charts even more
About what I found earlier regarding the geo column. That data clearly is messed up too because:
Subtracting all deaths of residents in or outside their home country from all deaths reported in the country (TOT_RESID - TOT_IN) it can result in negative values
Some data samples miss their counterpart representing 0, others have it present
If others agree to my perception, I’d provide a sample workflow to clean the data so we can continue with the challenge. Overall, this isn’t shouldn’t be challenging.
Please let me know your thoughts.
Update
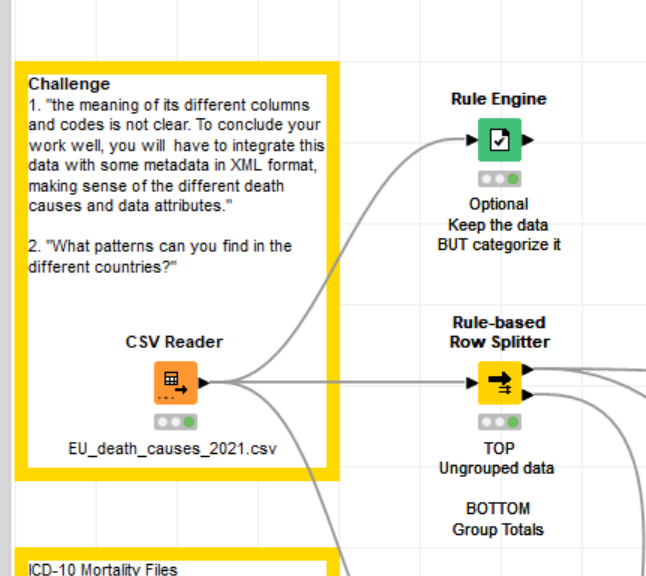
Here are the two options to either filter/split or mark the data which represent the cumulative value groups messing up the process. Happy Kniming!
$geo$ MATCHES "EU2.*" => "EU Countries"
// Deaths outside and inside of the country
// This data seems bad and represents an aggregation too
$resid$ = "TOT_RESID" => "Deaths in-/ and outside of the country"
// ICD 10 Grouped causes of Death like A15-A19_B90 OR B15-B19_B942
$icd10$ MATCHES "^[^_]+_[^_]+" => "ICD10 Grouped Causes of Death"
// Other aggregated values messing up the analysis
$age$ = "TOTAL" => "All ages"
$sex$ = "T" => "All genders"```
Rule based Row Filter
```// Grouped Values: geo = EU27_2020 & EU28
$geo$ MATCHES "EU2.*" => TRUE
// Deaths outside and inside of the country
// This data seems bad and represents an aggregation too
$resid$ = "TOT_RESID" => TRUE
// ICD 10 Grouped causes of Death like A15-A19_B90 OR B15-B19_B942
$icd10$ MATCHES "^[^_]+_[^_]+" => TRUE
// Other aggregated values messing up the analysis
$age$ = "TOTAL" => TRUE
$sex$ = "T" => TRUE```
Hi,
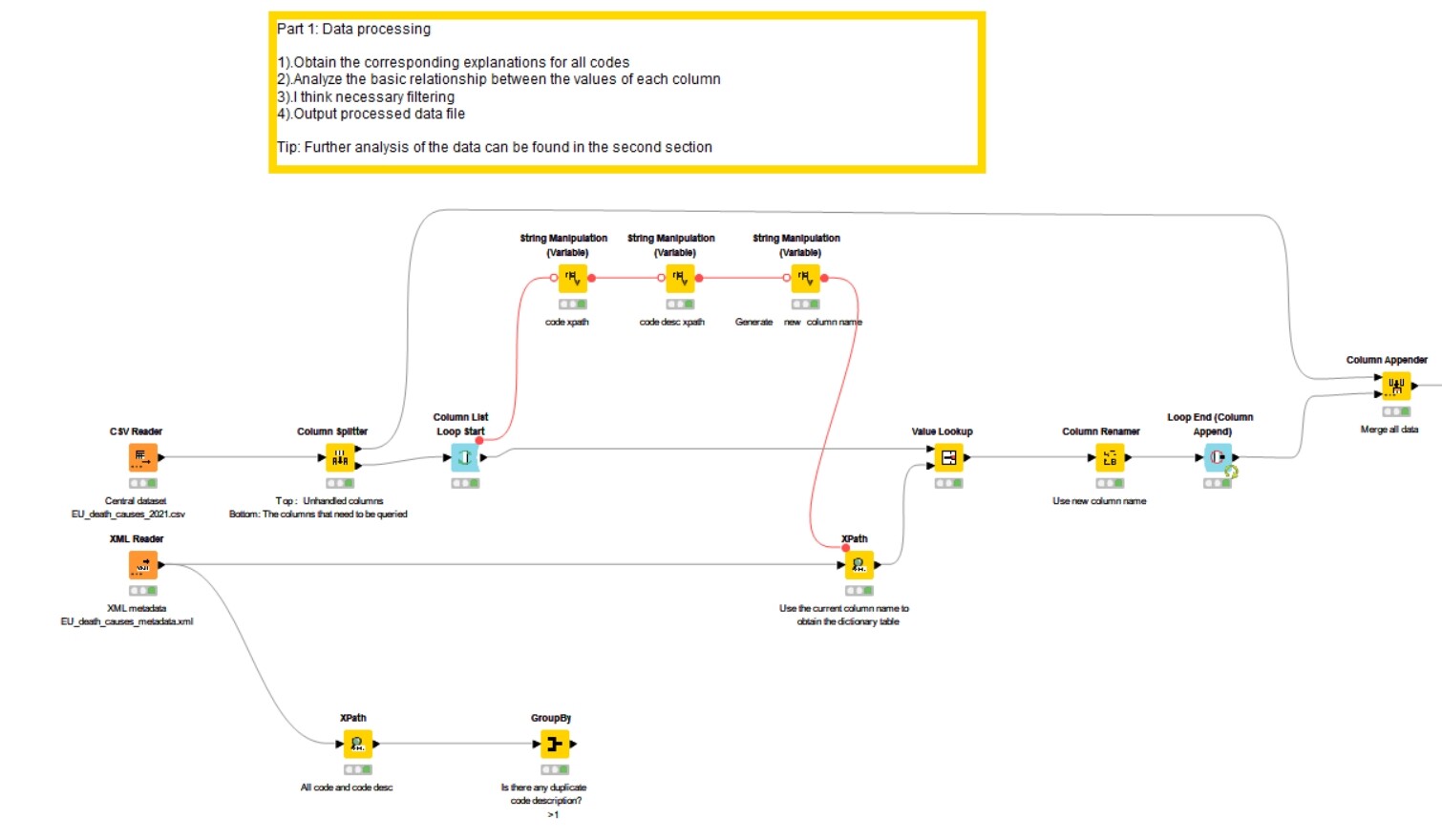
This is my first part of the workflow, completing data preprocessing.
Thank you for sharing with @mwiegand and @MartinDDDD . I created a column loop to extract all the code descriptions and proceed with preliminary data processing. Output a data file as the second part to process the dataset.
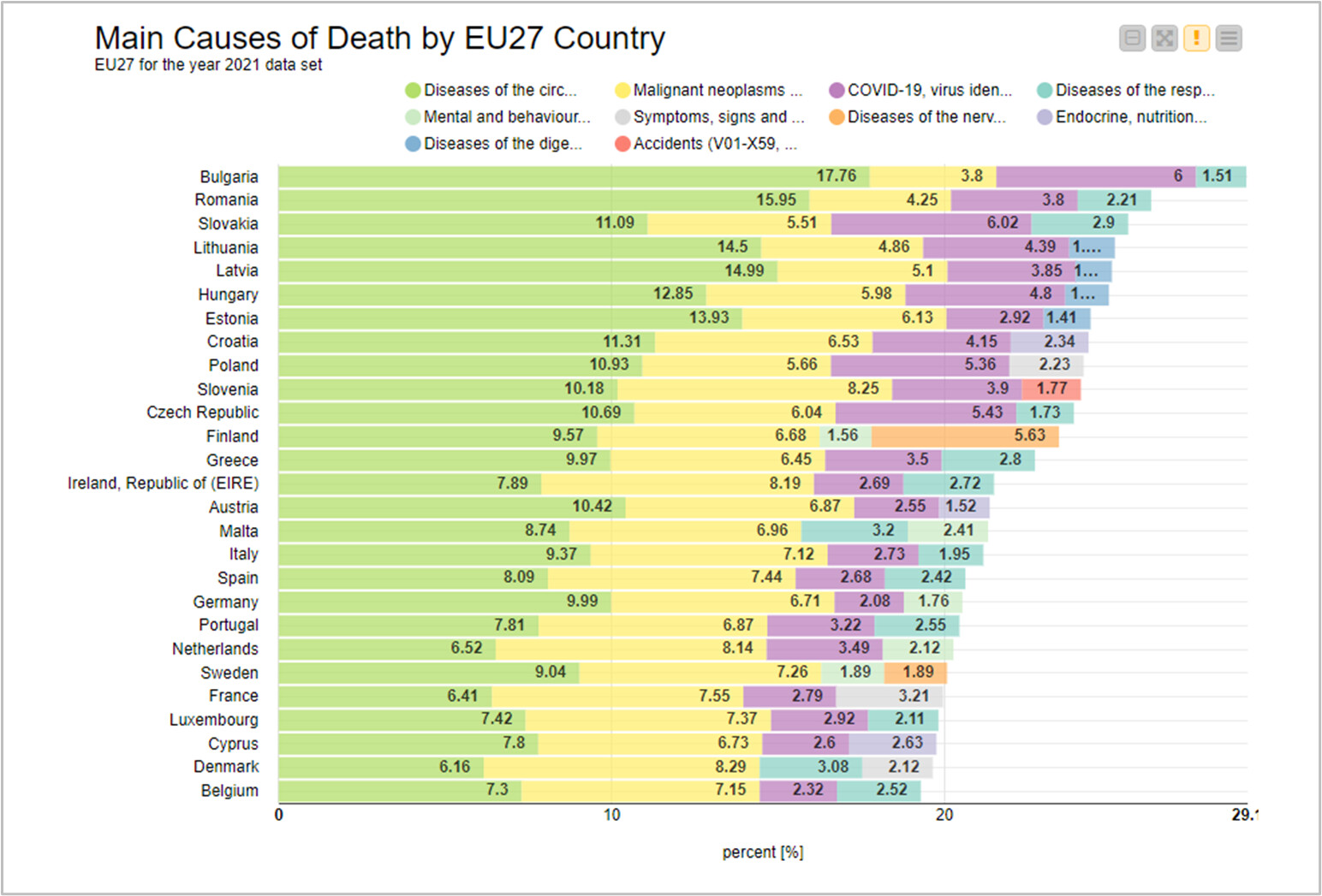
I decided to calculate a cause of death frequency per country. This normalizes comparisons across countries. Using raw data counts does not account for population differences. The drawback is that I couldn’t find EU census data by sex or age groups. If its available it would make this approach more robust. If all you’re interested in is comparing death causes for a single country, raw counts are perfectly ok; but not for comparing different countries. On 6/8 I uploaded a corrected version with the charts in a component.
Hi,
This is my second part of the workflow, using the output from the first part for the data.
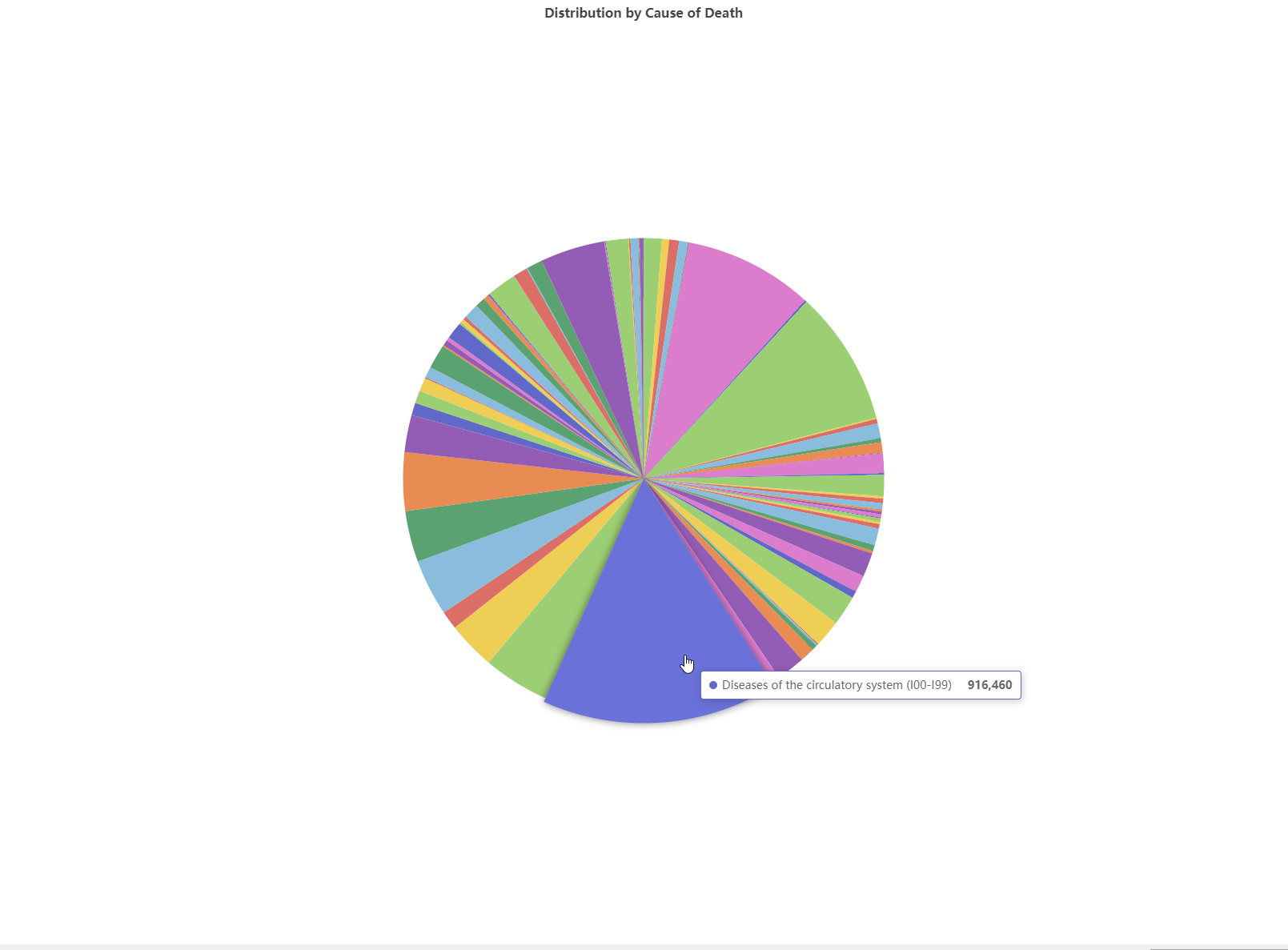
There are 5 dimensions in the data, first analyze the cause of death (icd10) dimension - a single dimension. Note that the statistics have already been completed in the data, so we only need to filter out the corresponding statistical rows.
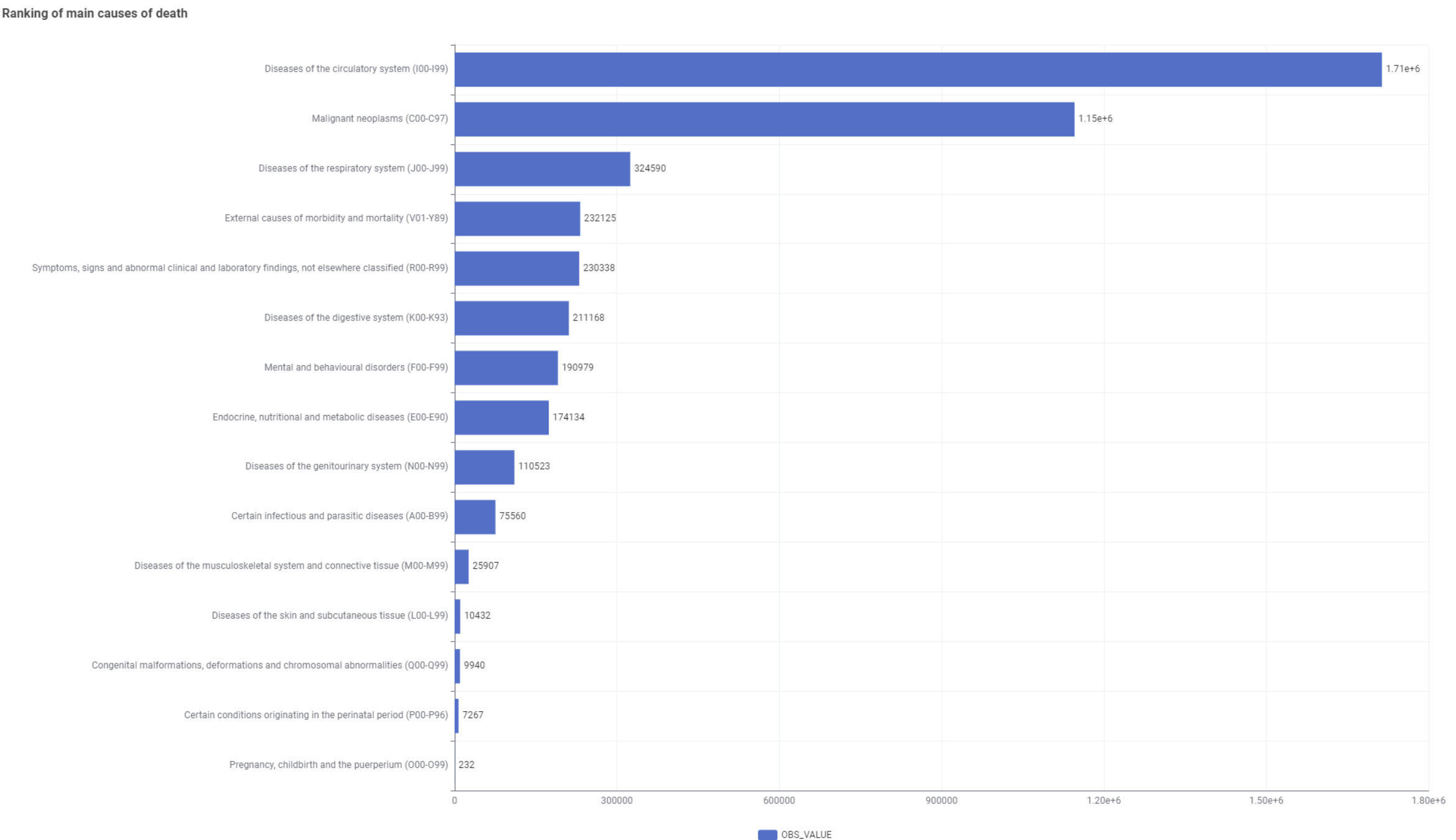
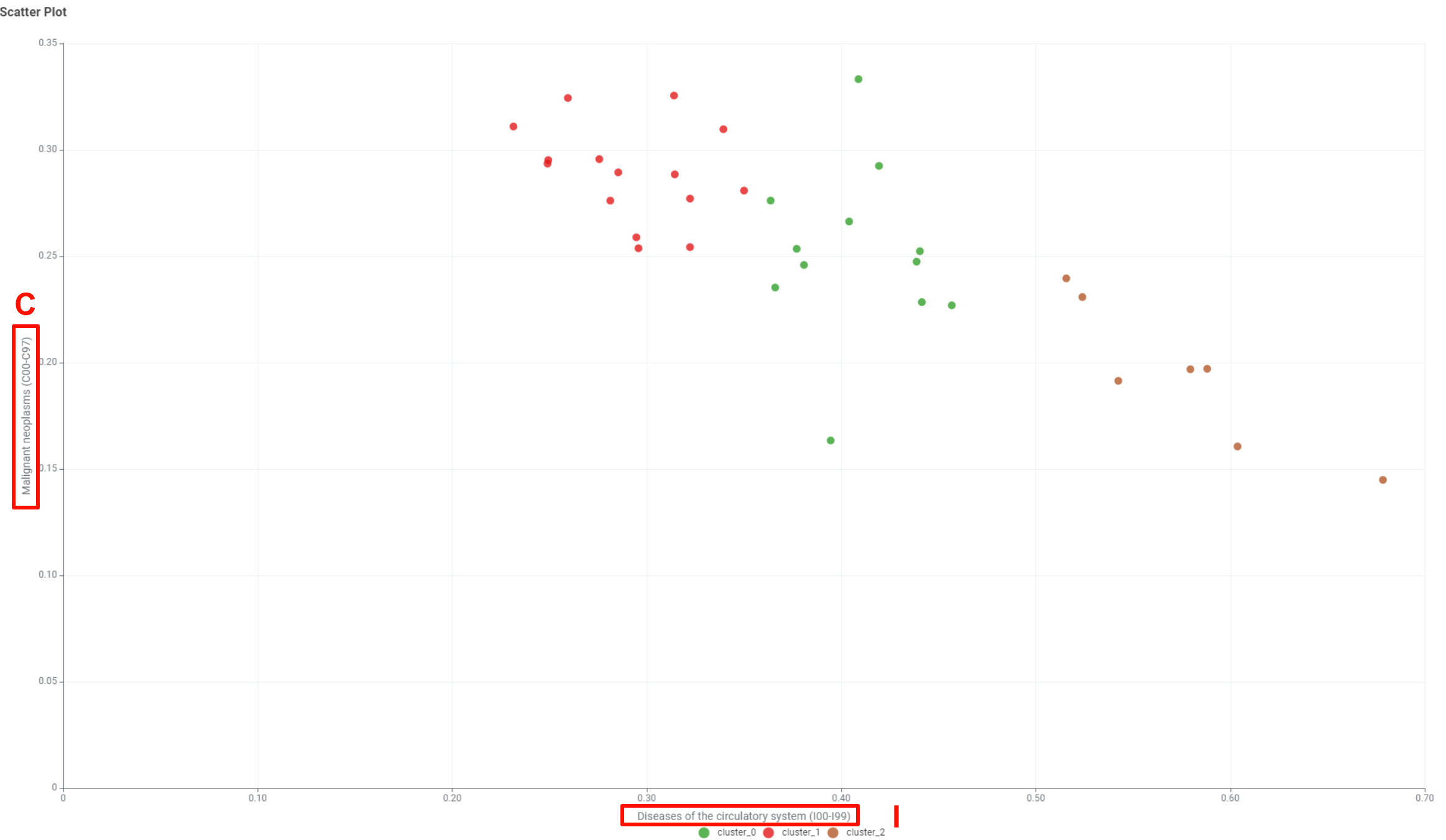
In the scatter plot, I selected the first cause (I) and the second cause (C) as the x-axis and y-axis, respectively, in the overall plot. It can be seen that data can be well separated in the I dimension.
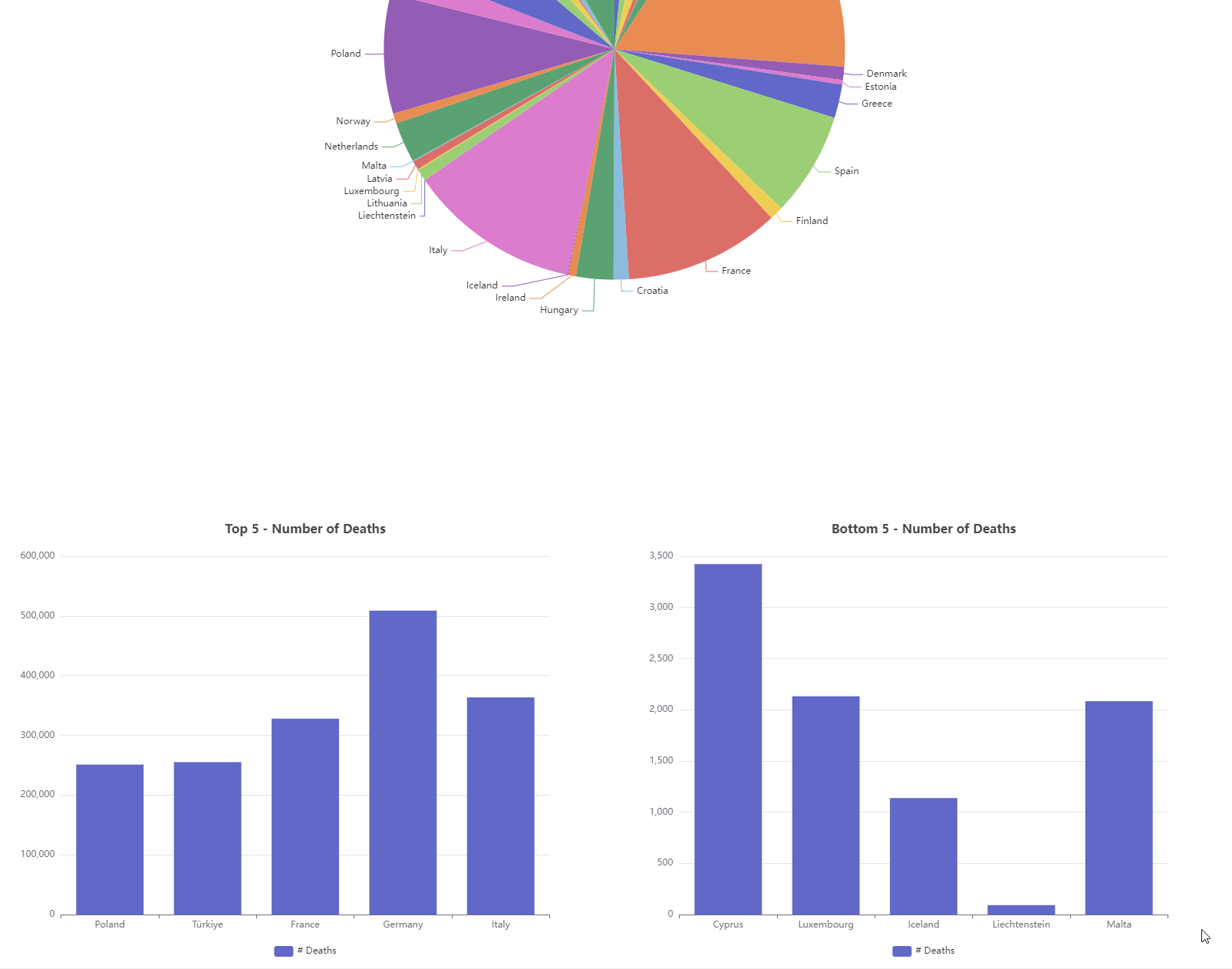
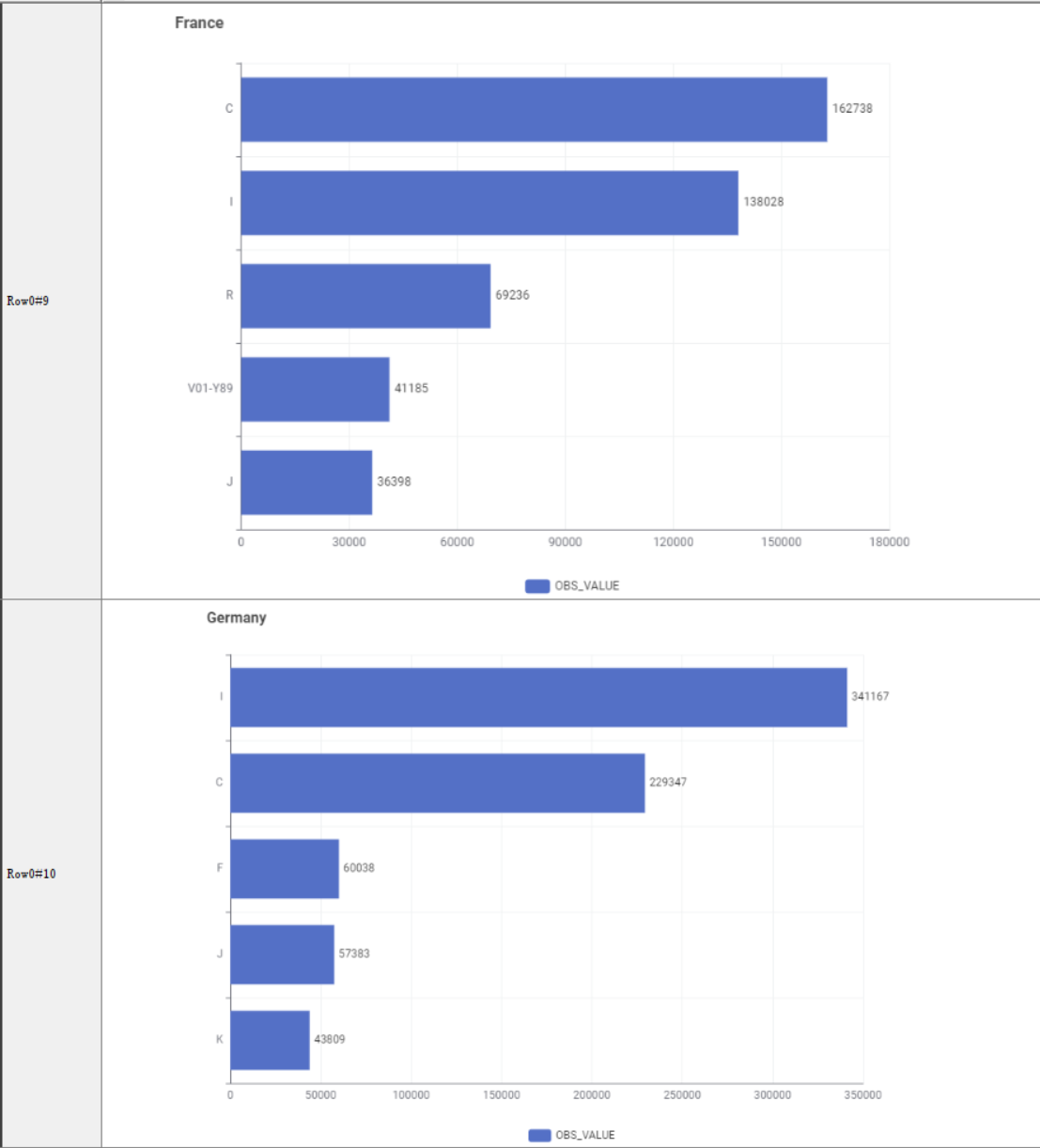
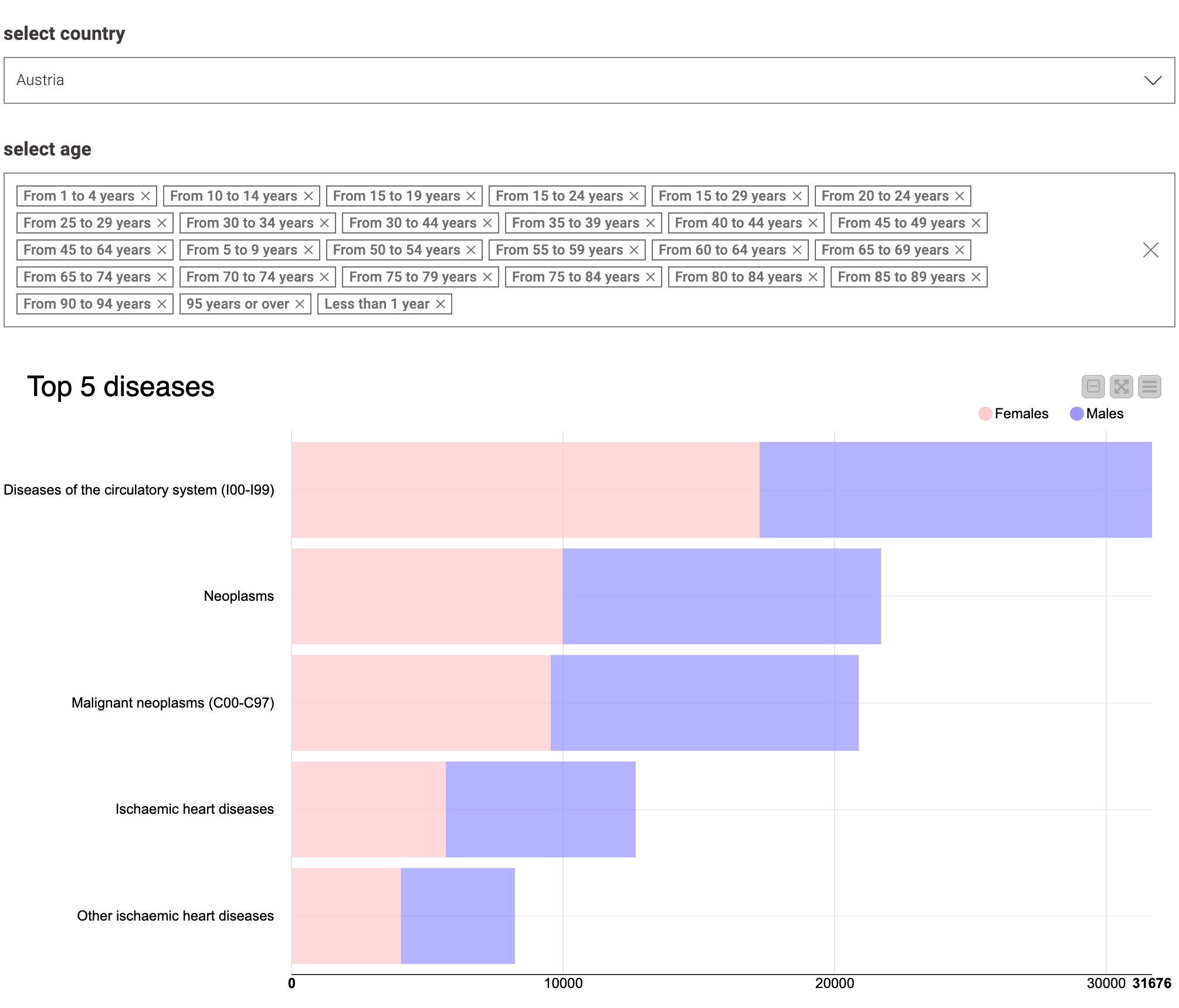
3.Extract representative countries from two categories for comparison
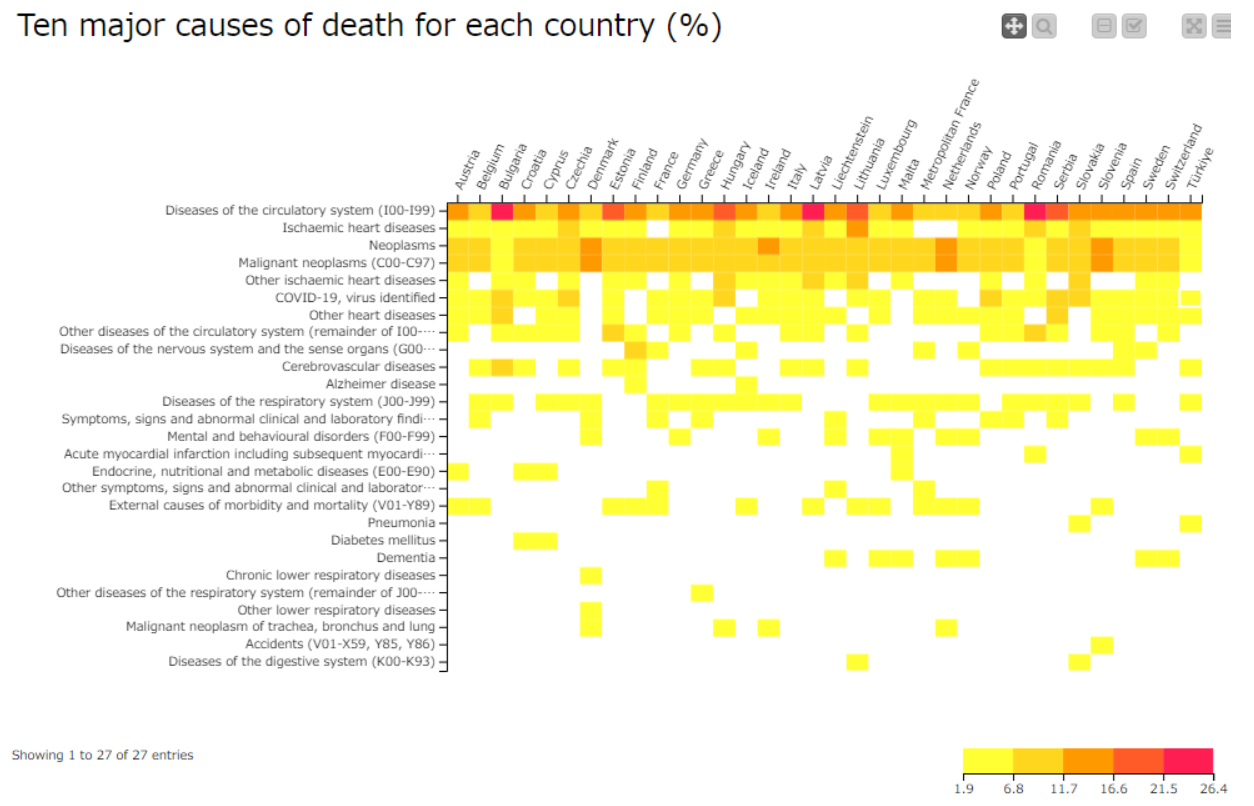
Please note the difference in the ranking of the main causes of death between the two countries.
For the data cleaning phase, I employed loops to generate XPath queries and conducted data replacement in batches (this process took some time to excecute).
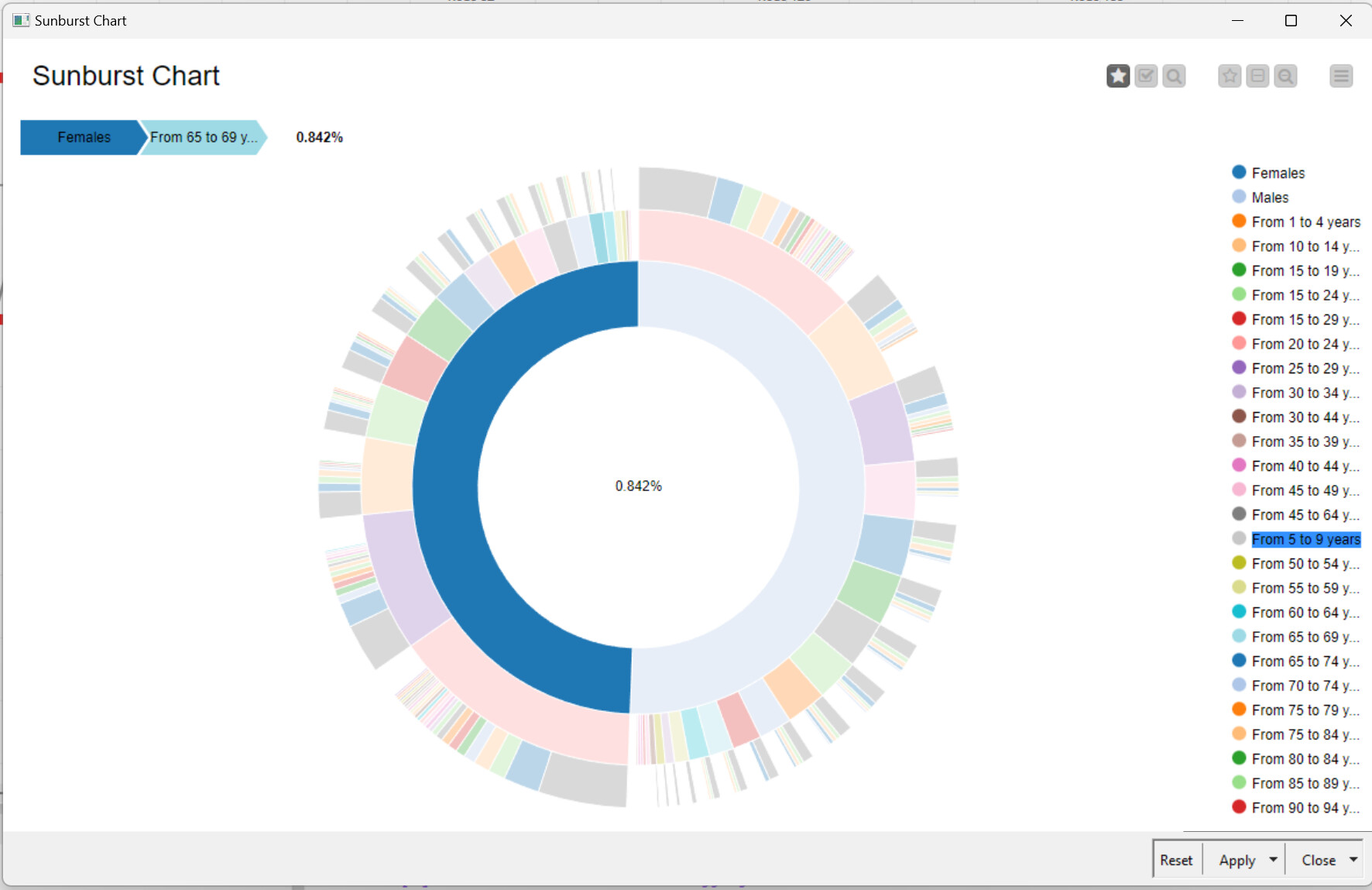
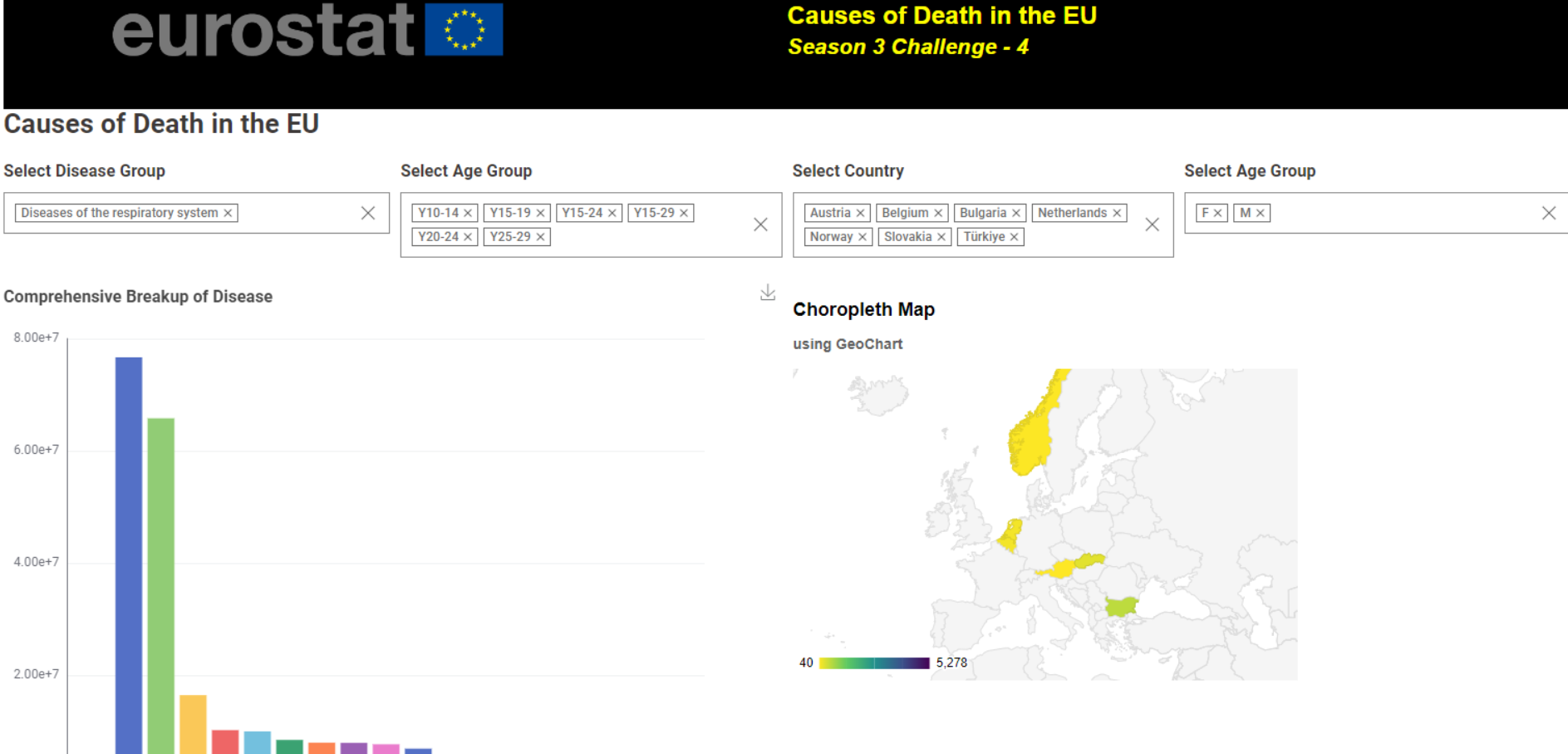
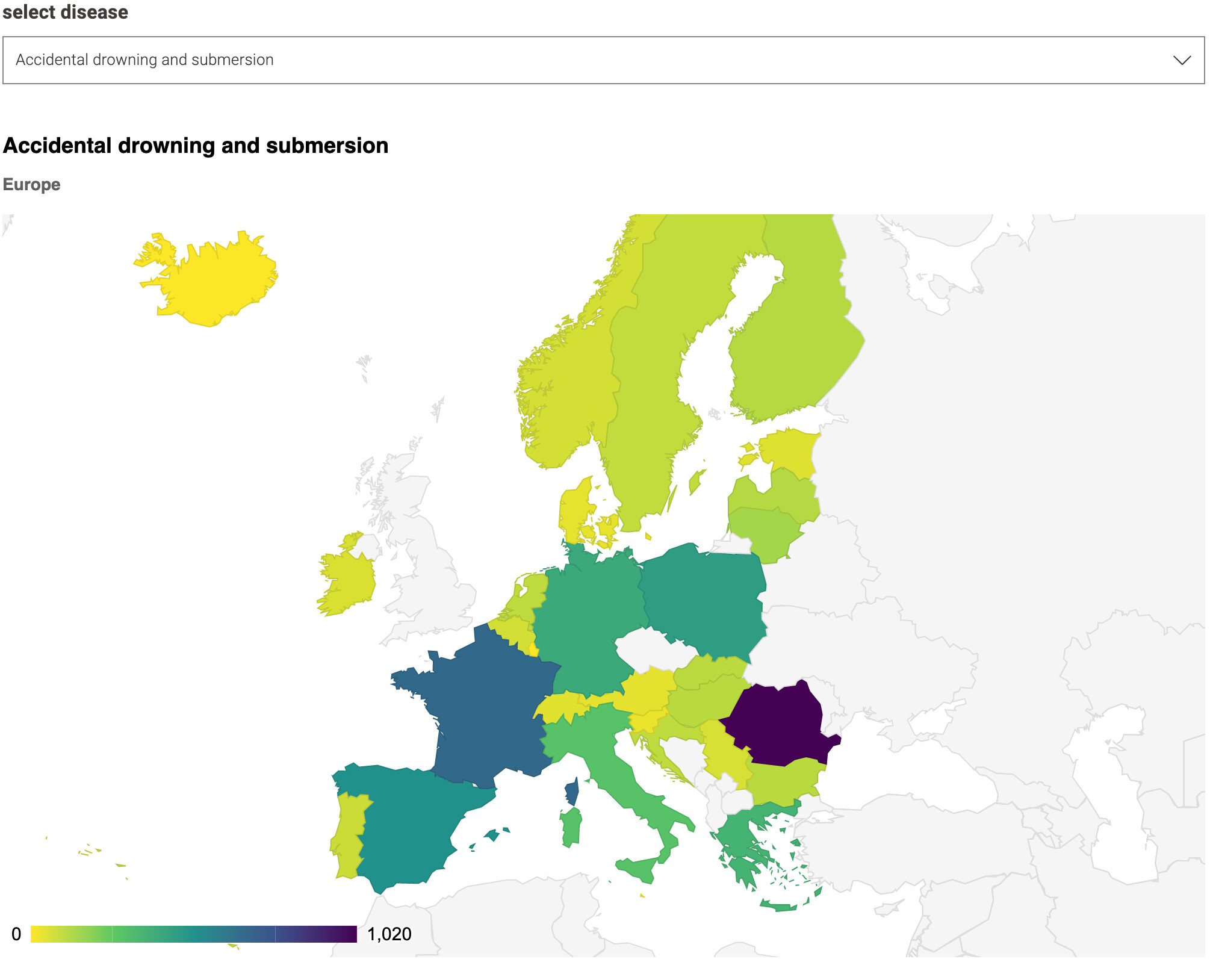
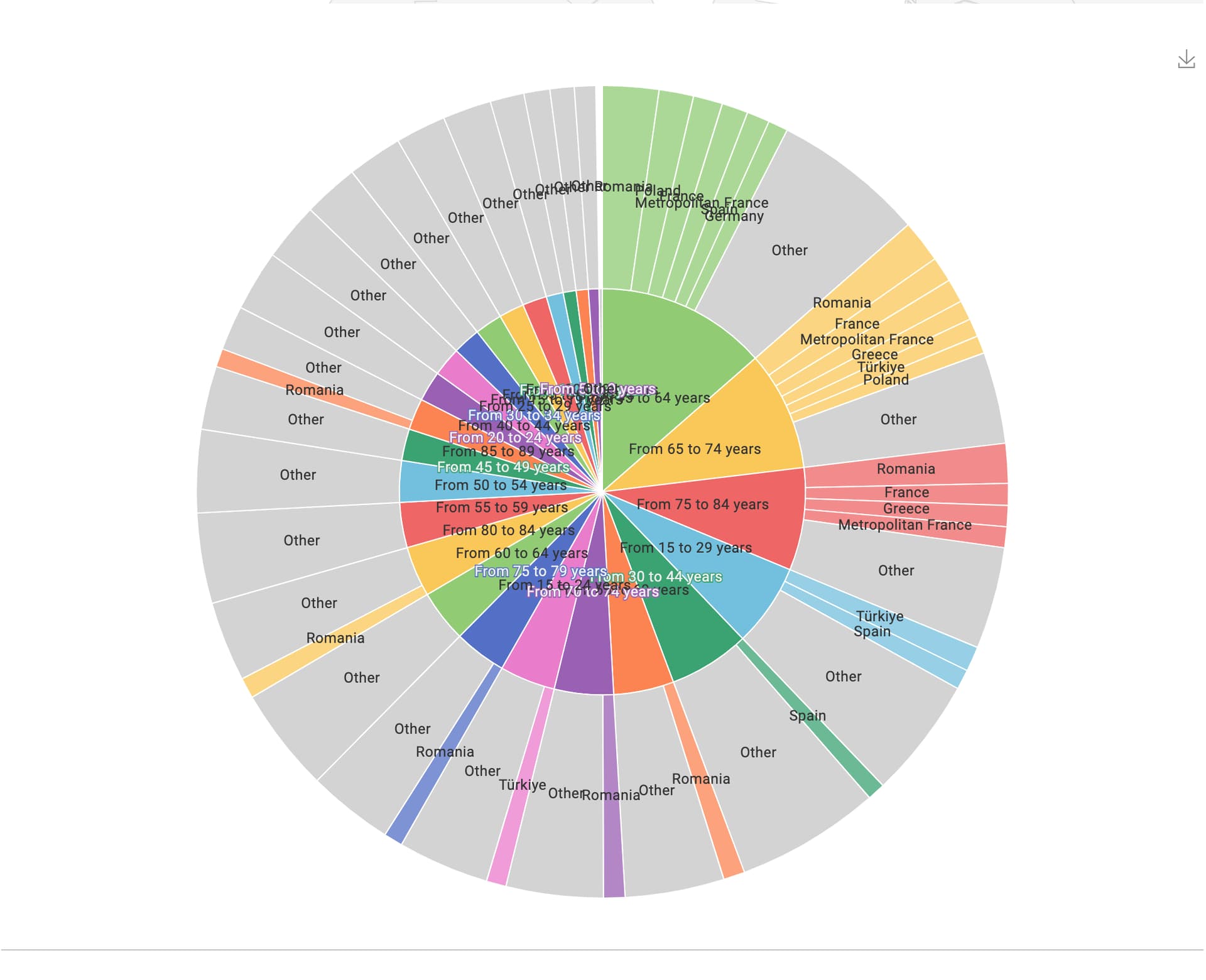
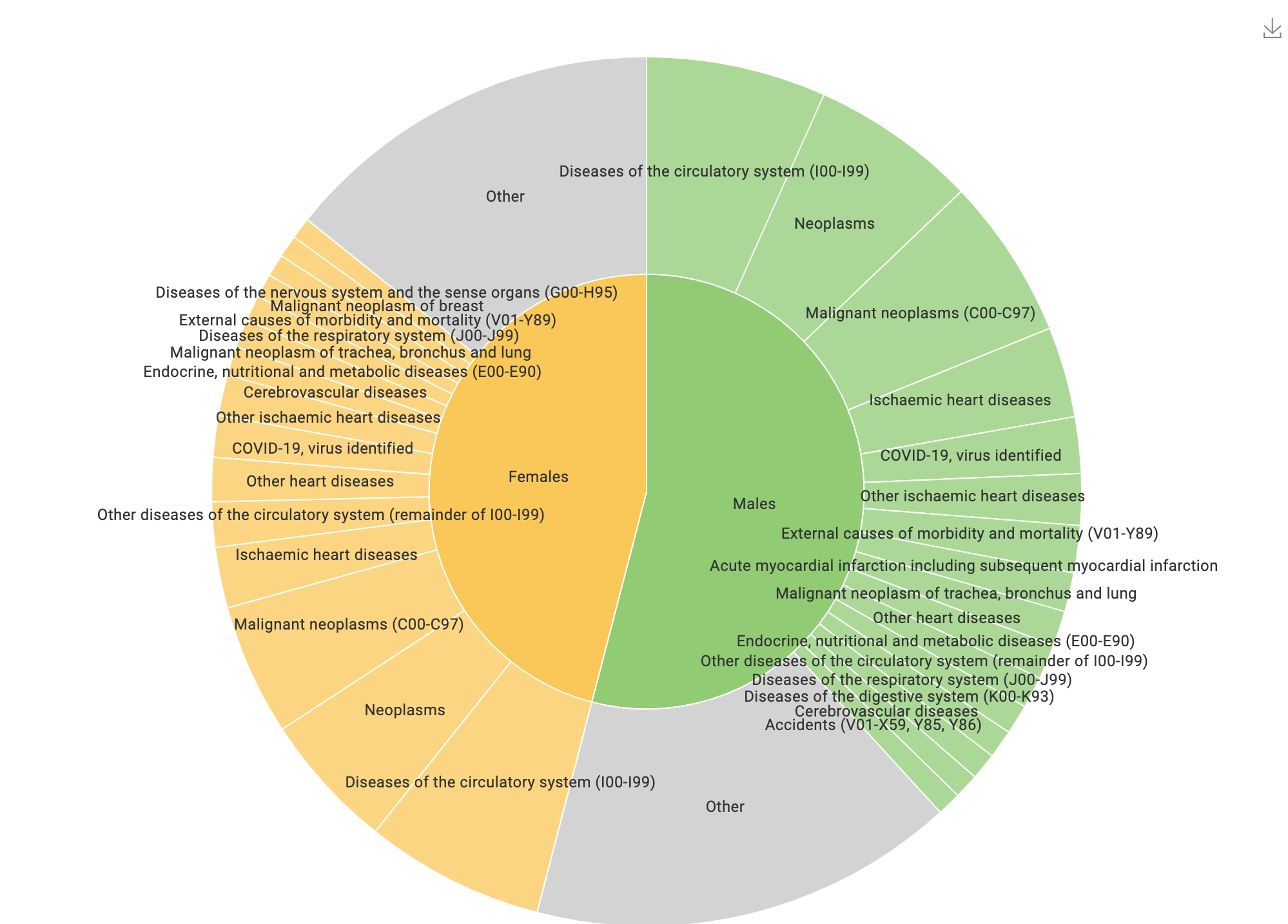
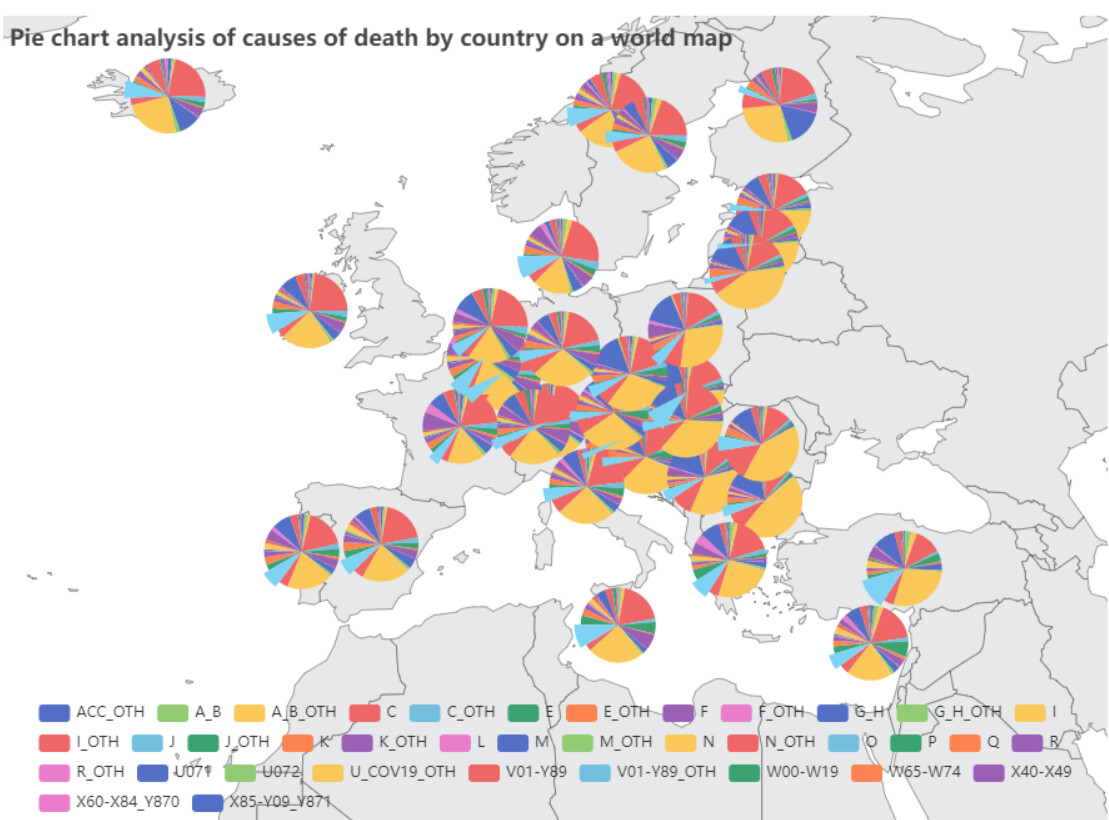
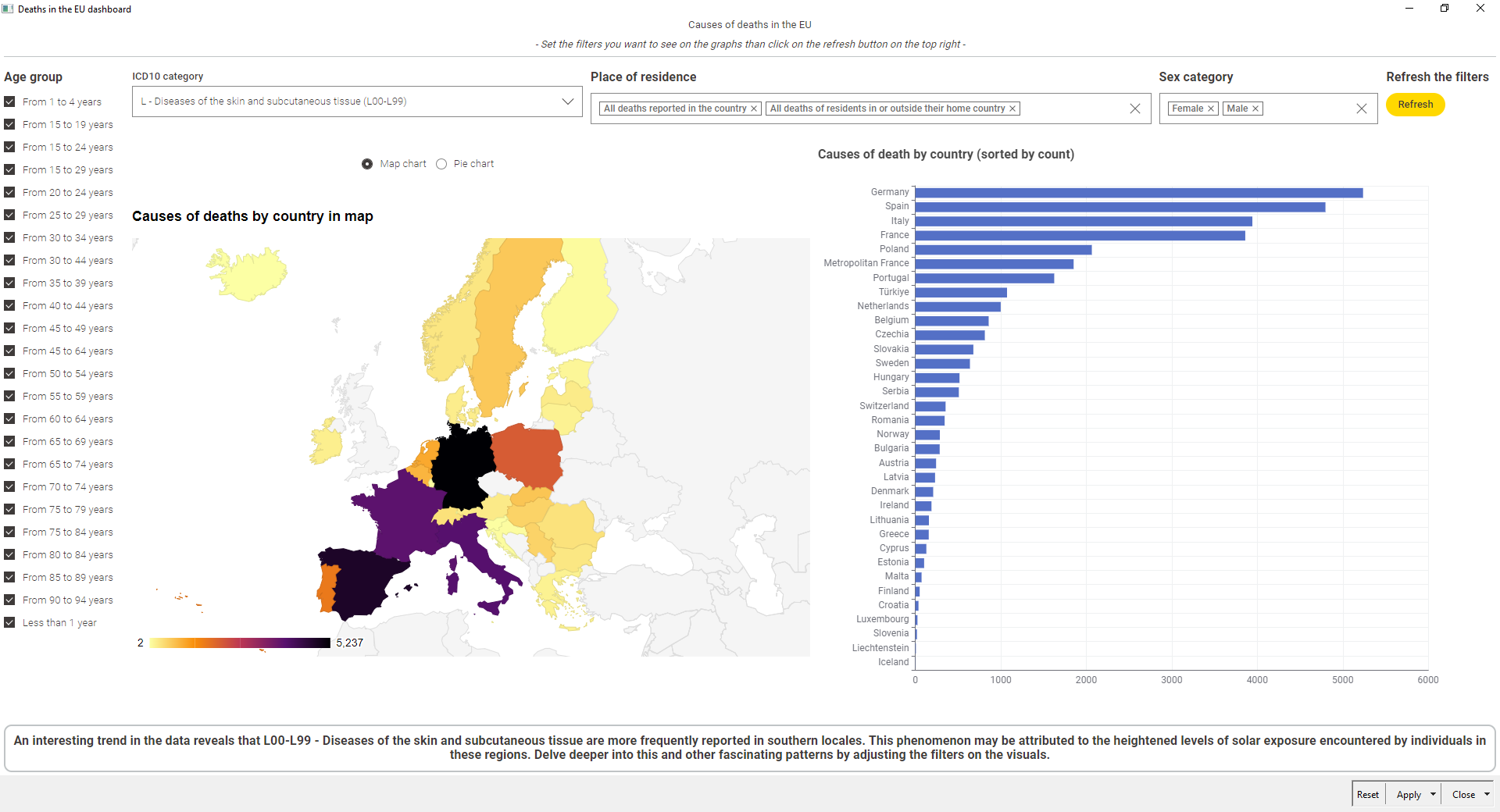
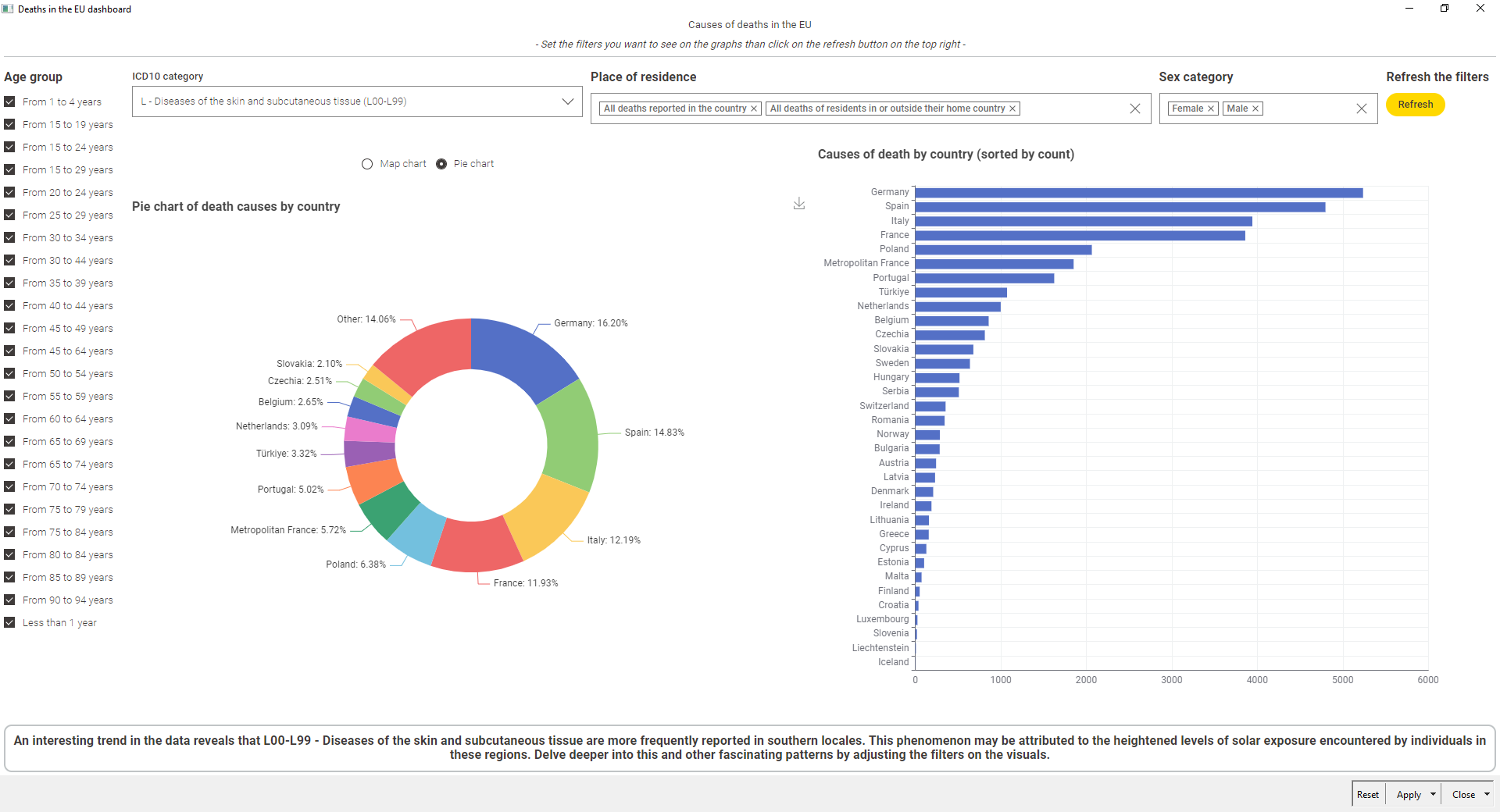
The dashboard was constructed mainly using a Choropleth Map and a Sunburst chart.
The Sunburst chart is useful because as it enables easy drill-down functionality.
My main disease filtering was not written correctly,
The original regular string is:
A_B|[C-R]|S_T|U |V01-Y89|Z
Change to:
[A-Z]|A_B|G_H|S_T|U.*|Z.*|V01-Y89
Cause of death filter conditions:
Statistics are based on major diseases, so capital letters A-Z are used.
But there are special circumstances where some types of diseases are merged, such as A_B, G_H, and S_T.
In 2021, the special epidemic was classified into category U, but there was no major category U, only minor items. So the filtering condition is “U.*” .
By the way, it seems that the code in the metadata is not comprehensive.
Hi all,
Here’s my solution. I had a little trouble dealing with XML, but thanks to the workflows posted by everyone here, I managed to make it. Thank you.
Here is my solution for Challange 4. It was a fun challenge big time! Big dataset, interesting topic, XML parsing, visualization. What more could a KNIME enthusiastic ask for?