Do we have any node in knime to Split multiple page PDF to individual pages ?
I’m not aware of a specific node but having done something a while ago to join PDFs using the R snippet node, this should be fairly simple to achieve.
Take a look at this thread
I didn’t know any R when I wrote that and this is still the limit of my R experience but I believe the same toolkit used there is capable of splitting pdf files too.
From memory, I think you will need to have the R pdftools package and qpdf. Have a quick look at that and see if that gives sufficient clues. If you need more assistance post back and I’ll have a play when I have some time.
In the meantime somebody else may know another way.
3 Likes
This is a very difficult question to answer because it really depends on the structure of your file. Is it text only ? Contains images, tables ?
It is possible if the file has any page number for example or a footer with a significant text, so you cant find with regex that number/footer, and do a split somehow. But if you have a page number, again could be hard to do because you can have numbers on the body of the PDF (advanced/improved regex).
Both of the nodes I know (Default PDF Parser and Tika Paser from the KNIME Textprocessing – KNIME Hub extension) returns the whole PDF as one column, and then you need to make your way by parsing/manipulating that column.
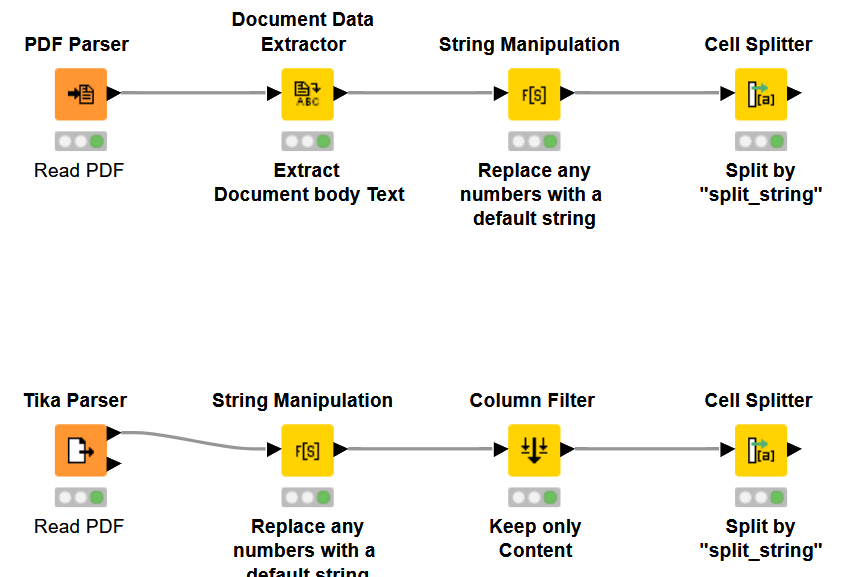
I wanted to show you an example, this could help you in a way. Take a look at both implementations, the Tika Parser would ask you to install the extension.
1 Like
Thanks for reply @takbb .
I do not have any exp in R. it will be really helpful to get some more assistance .
Hi @eamendola
The PDF , I am using contain around 50 pages. and each page has couple of images and some text related to those images.
I have tried using both PDF and Tikka parser. but these nodes does not have functionality to split the PDF . It extract all texts from 50 pages as if it is 1 page data. we need to extract data page wise and keep it separate .
Hi @srinibash1980 ,
I realised that in my new KNIME environment, I don’t have R installed so I went looking for a quick java based solution. In the interests of expediency, I’ll just drop a workflow here. I created a component which you can find here on the hub:
knime://My-KNIME-Hub/Users/takbb/Public/Components/Split%20PDF%20to%20pages
Here is a workflow to demo its use.
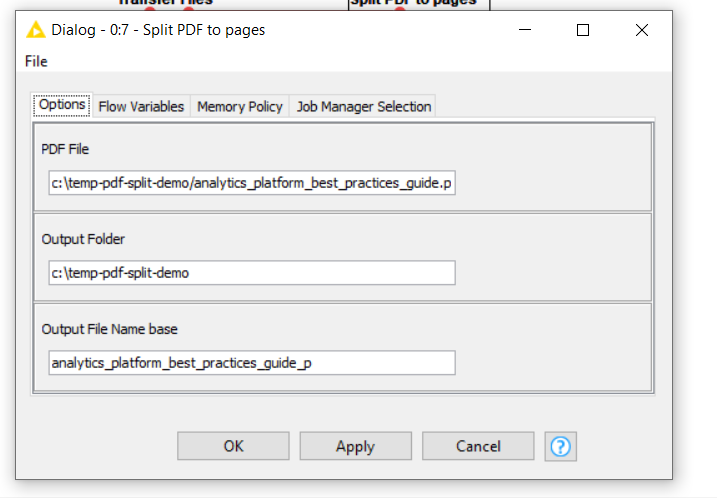
In this workflow, I download the analytics_platform_best_practices_guide.pdf file from the KNIME website, just so I have a pdf available to demo. The component is configured with an input file path, a destination folder path and a “base” file name to be used for creating the output.
If you run the workflow, it will create a folder on your pc called
c:\temp-pdf-split-demo

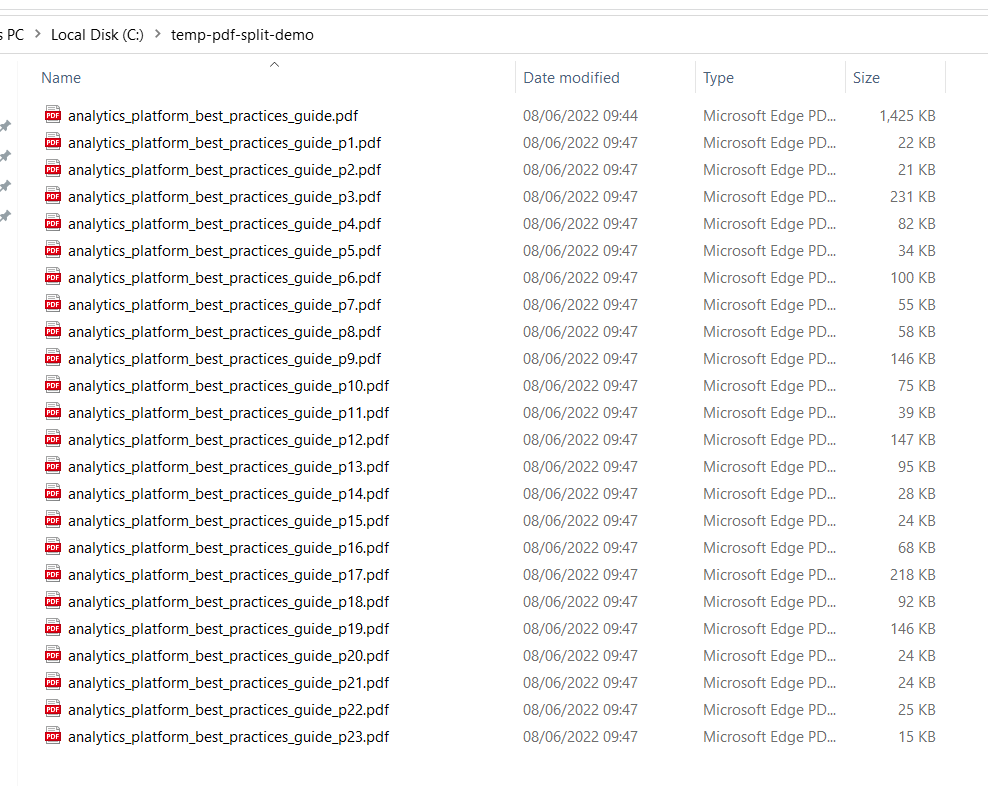
Hopefully it is self explanatory. Post back if you have any problems, or let me know if it works for you. At some point I’ll try to write up here how it works.
PDF Split using java.knwf (2.6 MB)
6 Likes
@takbb Thanks a ton for the help
1 Like
@takbb , It is working so nicely. Thanks again.
I do have one more query Brian, the current node works fine when we pass 1 PDF with multiple pages. if we have scenario to extract pages from multiple PDFs ! how we should achieve that.
1 Like
Hi @srinibash1980 , I’m pleased it worked for you and thank you for marking the solution as that will help others find it.
Attached is an updated version demonstrating processing of all pdf files in a folder. It uses a loop and with each iteration adjusts the config of the pdf component using flow variables.
For demo here, I used the file name for each pdf as the basis for creating a new output folder, so the extracted pages for each file go into their own output folder. Obviously you can do that, or you can just leave the output folder alone on the component as before.
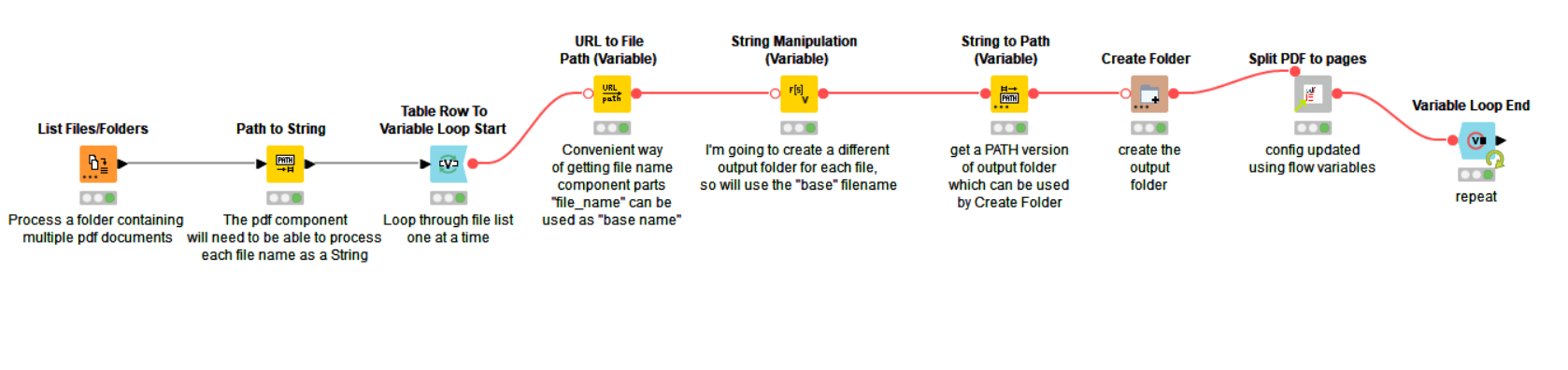
I hope that gives you the ideas/help you need for your own use case.
PDF Split using java with folder processing.knwf (2.6 MB)
[EDIT - I should add the website reference that was the source of the information/java code used in writing this solution:
I adapted the code from there to place in the java snippet.
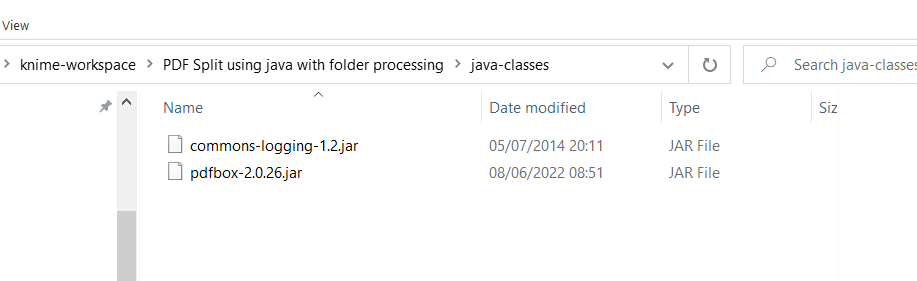
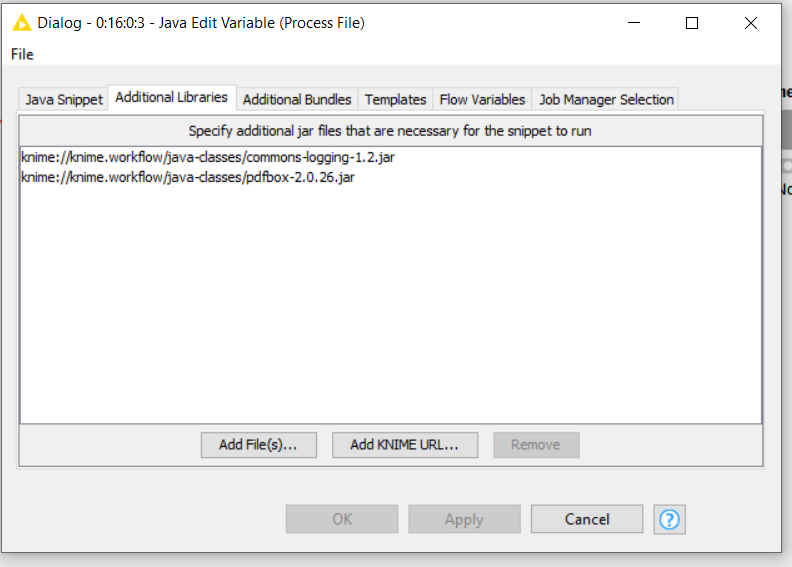
For this to work, it required two java .jar files:
- pdfbox-2.0.26.jar
- commons-logging-1.2.jar
These are open source and were downloaded from:
Apache PDFBox | Download
Apache Commons Logging - Download Apache Commons Logging
I created a folder inside the workflow folder itself called “java-classes”
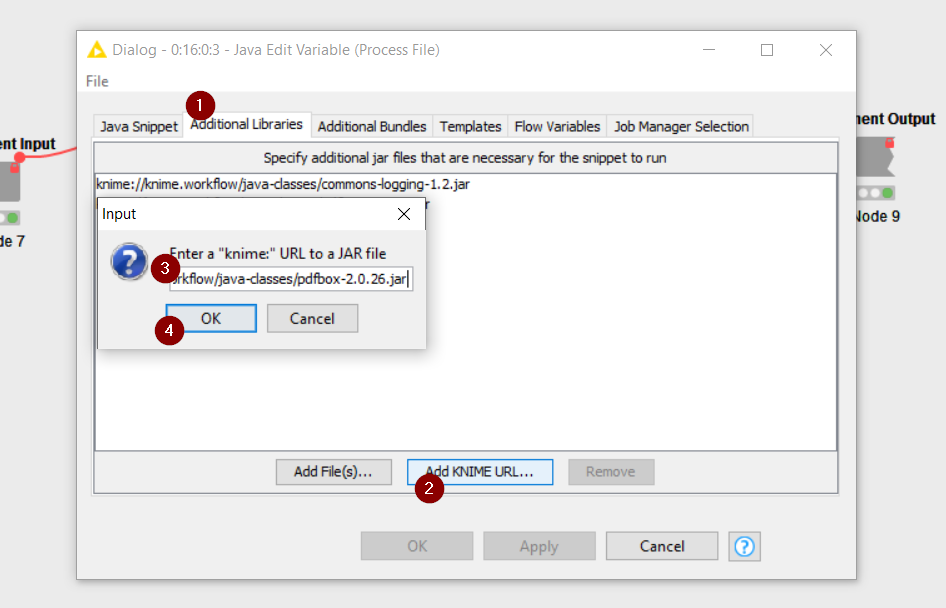
Then on the java snippet, I added these .jar files as additional libraries using the Add KNIME URL button so that I could add files contained within the workflow folder:
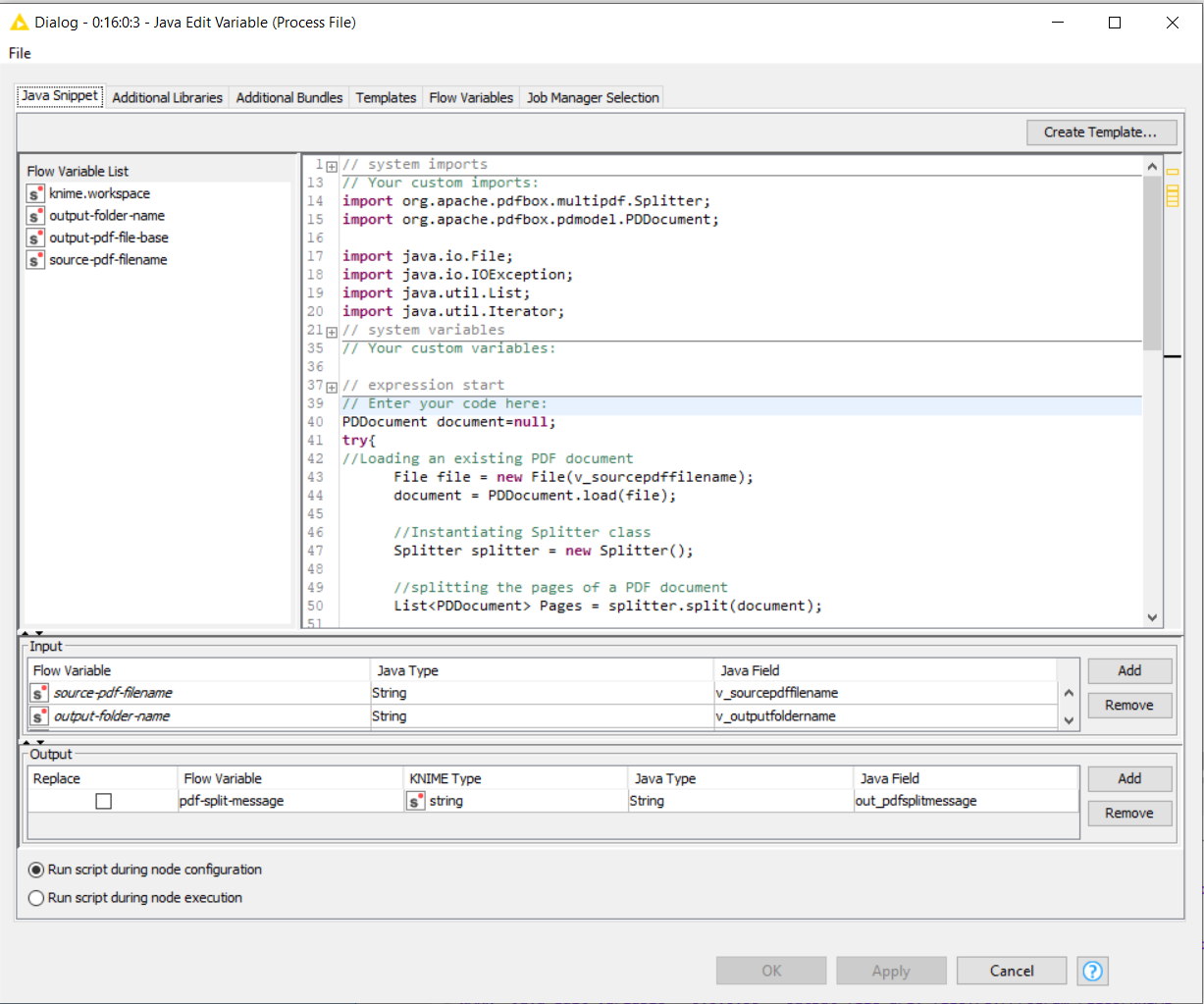
Enjoy! ![]()
5 Likes
@takbb , Thank you for the solution. I will implement as per my process and let you know if any further assistance needed.
1 Like
This topic was automatically closed 7 days after the last reply. New replies are no longer allowed.