Hi all,
I am hoping for some help, please.
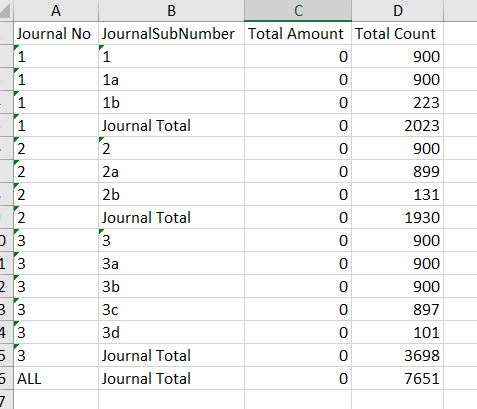
I have a dataset that includes many groups of data (grouped by journal number). Within each journal, there are a differing number of line items but each journal nets to zero in the Amount column.
My issue is that each journal number can only have a maximum of 6 lines. I have utilised Java script to determine whether a journal has 7 or more line items (1= No, 2 = Yes).
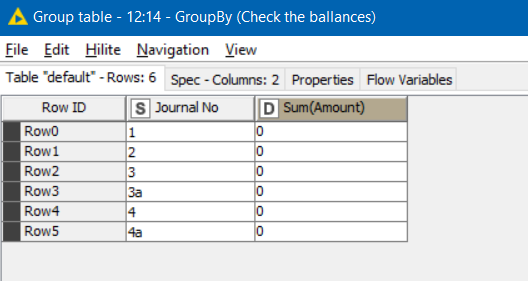
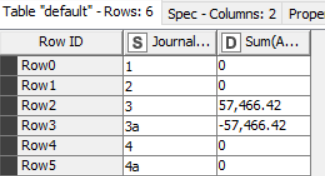
However, I am struggling with the next bit…If a journal has more than 6 lines (e.g journal 3 in the screenshot below), this needs to be split into two separate journals (3 and 3a - illustration in yellow an orange on the screenshot).
My issue is that the two separate journals need to have the 10 line items split between them (not necessary equally) BUT both journals 3 and 3a need to still balance to zero individually (as per the illustration).
Note- in this example the line items do match up nicely but there will be scenarios where each of the line items has a different value but overall it nets to zero.
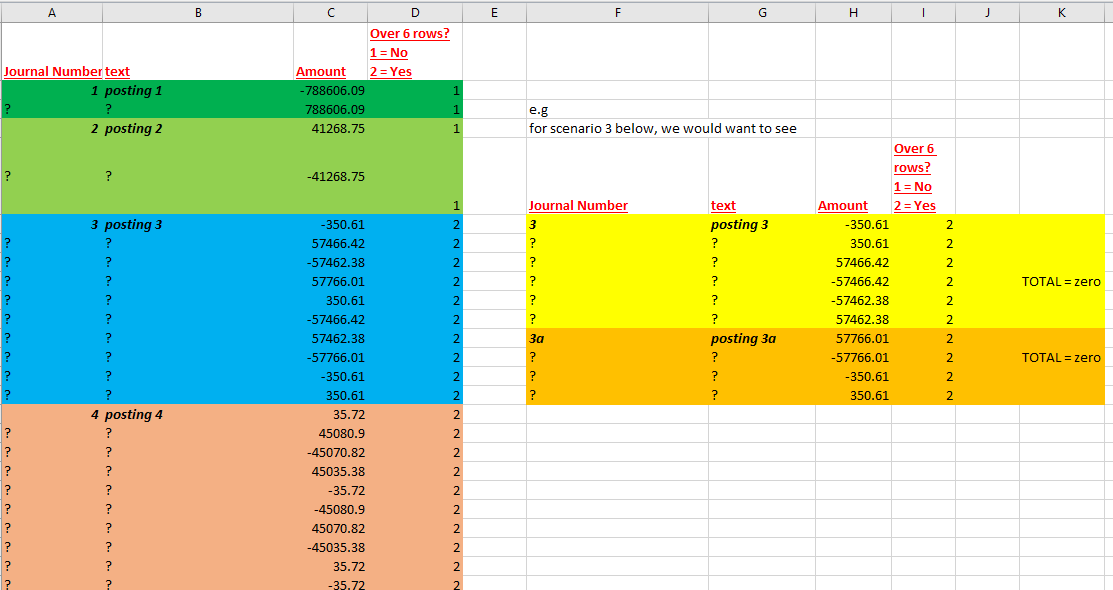
Does anyone know if there is a solution to my problem that is achievable within KNIME please? I am beginning to think this isn’t possible but just wanted to ask the question before i give up on it.
Thanks
tp