Hi @MCBirne , my copy of Excel doesn’t appear to have a stabw.n function , but looking it up, I gather that this is the stdev.p (Std Dev of population) function in my copy.
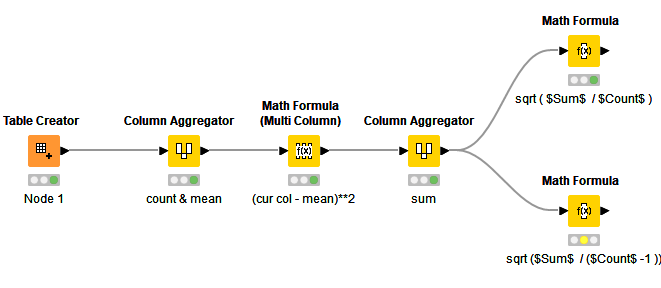
It seems that the “older” KNIME nodes all use the stdev.s (Std Dev of sample) function (STABW.S I think for your Excel). i.e. Column Aggregator, Math Formula, GroupBy
If you are using KNIME 5.4 (possibly KNIME 5.3 onwards), you can use the new Expression node to get the value you are looking for:
COLUMN_STDDEV
(column, ignore_nan, ddof)
Find the standard deviation of the values in a column, ignoring MISSING values. If all values are MISSING, the result is MISSING.
The ignore_nan option can be used to ignore NaN values. If it is set to TRUE, NaN values are ignored, but if all values are NaN, the result is MISSING. If it is FALSE, then NaN values are not ignored and the result is NaN if any value in the column is NaN.
There is also an optional argument for the delta degrees of freedom (ddof) to use for the calculation. By default it is set to 0, but this can be changed to 1 to calculate the corrected sample standard deviation. See wikipedia:standard_deviation. Other integer values are also accepted.
Arguments
- column: The name of the column to aggregate
- ignore_nan: Whether to skip
NaN values (defaults to FALSE)
- ddof: The delta degrees of freedom to use (defaults to 0)
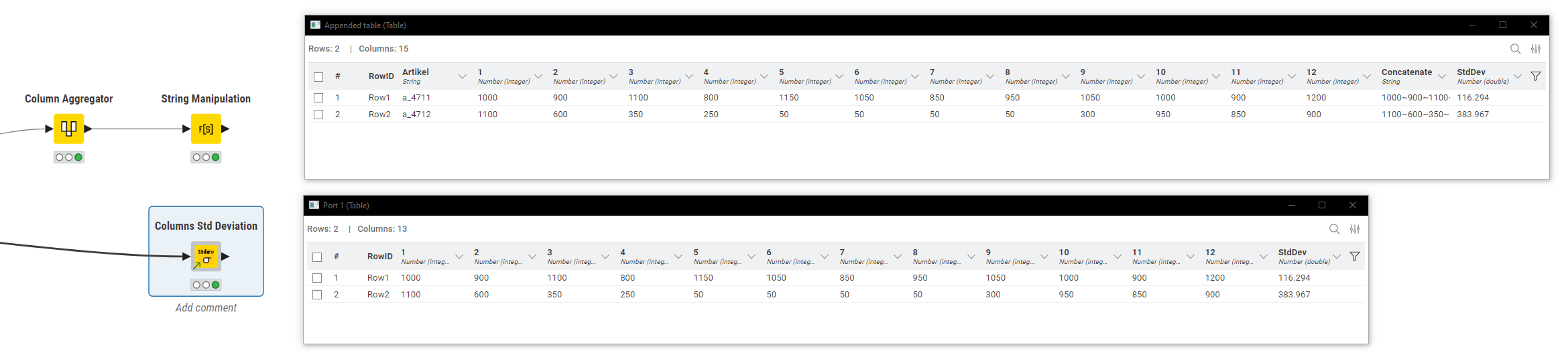
So if the optional third parameter is 0, it returns the value you want for the population (116.294), but if set to 1 it returns for the “sample” (121.46) as per the other KNIME nodes.
A couple of things to note.
- For column aggregation functions in the Expressions node, you specify the column name as a string literal e.g. “mycolumn”.
COLUMN_STDDEV("mycolumn")
If you attempt to write the column using the regular column name syntax for the Expressions node,
COLUMN_STDDEV($["mycolumn"])
this will be reported as a syntax error, which feels a little confusing at first.
- Unless your sample data is 10 rows or fewer, there is no point trying to test the column aggregation functions using the “Evaluate first 10 rows” button, since it will (as the name suggests) only use the first 10 rows in the calculation, leading to apparently incorrect (preview) results.
edit: btw, the expressions node will return the same value of course on every row. If you just want a single instance of the value, use the groupby node and simply group by the std dev column you just created to get back the single value (or you can use some other mechanism to remove the duplicated values)